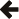


Error codes
Error codes are reasonable error handling technique, also working in C.
In this case the information is also stored as an int, but returned by value,
which makes it possible to make functions pure (side-effect-free and referentially
transparent).
int readInt(const char * filename, int& val)
{
FILE* fd;
int r = openFile(filename, /*out*/ fd);
if (r != 0)
return r; // return whatever error openFile() returned
r = readInt(fd, /*out*/ val);
if (r != 0)
return READERRC_NOINT; // my error code
return 0; // success
}
Because the type of the error information (int) is known statically, no memory
allocation or type erasure is required. This technique is very efficient.
Downsides
All failure paths written manually can be considered both an advantage and a
disadvantage. Forgetting to put a failure handling if causes bugs.
If I need to substitute an error code returned by lower-level function with mine more appropriate at this level, the information about the original failure is gone.
Also, all possible error codes invented by different programmers in different
third party libraries must fit into one int and not overlap with any other error
code value. This is quite impossible and does not scale well.
Because errors are communicated through returned values, we cannot use function’s return type to return computed values. Computed values are written to function output parameters, which requires objects to be created before we have values to put into them. This requires many objects in unintended state to exist. Writing to output parameters often requires an indirection and can incur some run-time cost.