The analyze API is an invaluable tool for viewing the
terms produced by an analyzer. A built-in analyzer (or combination of built-in
tokenizer, token filters, and character filters) can be specified inline in
the request:
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
POST _analyze
{
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}Alternatively, a custom analyzer can be
referred to when running the analyze API on a specific index:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"std_folded": {  "type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std_folded"
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std_folded"  }
}
}
}
GET my_index/_analyze
}
}
}
}
GET my_index/_analyze  {
"analyzer": "std_folded",
{
"analyzer": "std_folded", 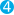 "text": "Is this déjà vu?"
}
GET my_index/_analyze
"text": "Is this déjà vu?"
}
GET my_index/_analyze  {
"field": "my_text",
{
"field": "my_text",  "text": "Is this déjà vu?"
}
"text": "Is this déjà vu?"
}
|
Define a |
|
The field |
|
To refer to this analyzer, the |
| Refer to the analyzer by name. |
|
Refer to the analyzer used by field |