During Index Lifecycle Management’s execution of the policy for an index, it’s possible for a step to encounter an error during its execution. When this happens, ILM will move the management state into an "error" step. This halts further execution of the policy and gives an administrator the chance to address any issues with the policy, index, or cluster.
An example will be helpful in illustrating this, imagine the following policy has been created by a user:
PUT _ilm/policy/shrink-the-index
{
"policy": {
"phases": {
"warm": {
"min_age": "5d",
"actions": {
"shrink": {
"number_of_shards": 4
}
}
}
}
}
}This policy waits until the index is at least 5 days old, and then shrinks the index to 4 shards.
Now imagine that a user creates a new index "myindex" with two primary shards, telling it to use the policy they have created:
PUT /myindex
{
"settings": {
"index.number_of_shards": 2,
"index.lifecycle.name": "shrink-the-index"
}
}After five days have passed, ILM will attempt to shrink this index from 2 shards to 4, which is invalid since the shrink action cannot increase the number of shards. When this occurs, ILM will move this index to the "error" step. Once an index is in this step, information about the reason for the error can be retrieved from the ILM Explain API:
GET /myindex/_ilm/explain
Which returns the following information:
{
"indices" : {
"myindex" : {
"index" : "myindex",
"managed" : true,  "policy" : "shrink-the-index",
"policy" : "shrink-the-index",  "lifecycle_date_millis" : 1541717265865,
"phase" : "warm",
"lifecycle_date_millis" : 1541717265865,
"phase" : "warm",  "phase_time_millis" : 1541717272601,
"action" : "shrink",
"phase_time_millis" : 1541717272601,
"action" : "shrink", 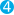 "action_time_millis" : 1541717272601,
"step" : "ERROR",
"action_time_millis" : 1541717272601,
"step" : "ERROR",  "step_time_millis" : 1541717272688,
"failed_step" : "shrink",
"step_time_millis" : 1541717272688,
"failed_step" : "shrink",  "step_info" : {
"type" : "illegal_argument_exception",
"step_info" : {
"type" : "illegal_argument_exception",  "reason" : "the number of target shards [4] must be less that the number of source shards [2]"
"reason" : "the number of target shards [4] must be less that the number of source shards [2]"  },
"phase_execution" : {
"policy" : "shrink-the-index",
"phase_definition" : {
},
"phase_execution" : {
"policy" : "shrink-the-index",
"phase_definition" : {  "min_age" : "5d",
"actions" : {
"shrink" : {
"number_of_shards" : 4
}
}
},
"version" : 1,
"modified_date_in_millis" : 1541717264230
}
}
}
}
"min_age" : "5d",
"actions" : {
"shrink" : {
"number_of_shards" : 4
}
}
},
"version" : 1,
"modified_date_in_millis" : 1541717264230
}
}
}
}
| this index is managed by ILM |
| the policy in question, in this case, "shrink-the-index" |
| what phase the index is currently in |
| what action the index is currently on |
| what step the index is currently on, in this case, because there is an error, the index is in the "ERROR" step |
| the name of the step that failed to execute, in this case "shrink" |
| the error class that occurred during this step |
| the error message that occurred during the execution failure |
| the definition of the phase (in this case, the "warm" phase) that the index is currently on |
The index here has been moved to the error step because the shrink definition in the policy is using an incorrect number of shards. So rectifying that in the policy entails updating the existing policy to use one instead of four for the targeted number of shards.
PUT _ilm/policy/shrink-the-index
{
"policy": {
"phases": {
"warm": {
"min_age": "5d",
"actions": {
"shrink": {
"number_of_shards": 1
}
}
}
}
}
}Retrying failed index lifecycle management steps
Once the underlying issue that caused an index to move to the error step has been corrected, index lifecycle management must be told to retry the step to see if it can progress further. This is accomplished by invoking the retry API
POST /myindex/_ilm/retry
Once this has been issue, index lifecycle management will asynchronously pick up on the step that is in a failed state, attempting to re-run it. The ILM Explain API can again be used to monitor the status of re-running the step.