It is often useful to index the same field in different ways for different
purposes. This is the purpose of multi-fields. For instance, a string
field could be mapped as a text field for full-text
search, and as a keyword field for sorting or aggregations:
PUT my_index
{
"mappings": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {  "type": "keyword"
}
}
}
}
}
}
PUT my_index/_doc/1
{
"city": "New York"
}
PUT my_index/_doc/2
{
"city": "York"
}
GET my_index/_search
{
"query": {
"match": {
"city": "york"
"type": "keyword"
}
}
}
}
}
}
PUT my_index/_doc/1
{
"city": "New York"
}
PUT my_index/_doc/2
{
"city": "York"
}
GET my_index/_search
{
"query": {
"match": {
"city": "york"  }
},
"sort": {
"city.raw": "asc"
}
},
"sort": {
"city.raw": "asc"  },
"aggs": {
"Cities": {
"terms": {
"field": "city.raw"
},
"aggs": {
"Cities": {
"terms": {
"field": "city.raw" 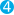 }
}
}
}
}
}
}
}
|
The |
|
The |
|
The |
Multi-fields do not change the original _source field.
The fields setting is allowed to have different settings for fields of
the same name in the same index. New multi-fields can be added to existing
fields using the PUT mapping API.
Another use case of multi-fields is to analyze the same field in different
ways for better relevance. For instance we could index a field with the
standard analyzer which breaks text up into
words, and again with the english analyzer
which stems words into their root form:
PUT my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
PUT my_index/_doc/1
{ "text": "quick brown fox" }
PUT my_index/_doc/2
{ "text": "quick brown foxes" }
GET my_index/_search
{
"query": {
"multi_match": {
"query": "quick brown foxes",
"fields": [  "text",
"text.english"
],
"type": "most_fields"
"text",
"text.english"
],
"type": "most_fields"  }
}
}
}
}
}
|
The |
|
The |
|
Index two documents, one with |
|
Query both the |
The text field contains the term fox in the first document and foxes in
the second document. The text.english field contains fox for both
documents, because foxes is stemmed to fox.
The query string is also analyzed by the standard analyzer for the text
field, and by the english analyzer for the text.english field. The
stemmed field allows a query for foxes to also match the document containing
just fox. This allows us to match as many documents as possible. By also
querying the unstemmed text field, we improve the relevance score of the
document which matches foxes exactly.