Usually, the same analyzer should be applied at index time and at search time, to ensure that the terms in the query are in the same format as the terms in the inverted index.
Sometimes, though, it can make sense to use a different analyzer at search
time, such as when using the edge_ngram
tokenizer for autocomplete.
By default, queries will use the analyzer defined in the field mapping, but
this can be overridden with the search_analyzer setting:
PUT my_index
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {  "type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "autocomplete",
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "autocomplete",  "search_analyzer": "standard"
"search_analyzer": "standard"  }
}
}
}
PUT my_index/_doc/1
{
"text": "Quick Brown Fox"
}
}
}
}
PUT my_index/_doc/1
{
"text": "Quick Brown Fox" 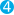 }
GET my_index/_search
{
"query": {
"match": {
"text": {
"query": "Quick Br",
}
GET my_index/_search
{
"query": {
"match": {
"text": {
"query": "Quick Br",  "operator": "and"
}
}
}
}
"operator": "and"
}
}
}
}
|
Analysis settings to define the custom |
|
The |
|
This field is indexed as the terms: [ |
|
The query searches for both of these terms: [ |
See Index time search-as-you- type for a full explanation of this example.
The search_analyzer setting can be updated on existing fields
using the PUT mapping API.