The Profile API is a debugging tool and adds significant overhead to search execution.
The Profile API provides detailed timing information about the execution of individual components in a search request. It gives the user insight into how search requests are executed at a low level so that the user can understand why certain requests are slow, and take steps to improve them. Note that the Profile API, amongst other things, doesn’t measure network latency, time spent in the search fetch phase, time spent while the requests spends in queues or while merging shard responses on the coordinating node.
The output from the Profile API is very verbose, especially for complicated requests executed across many shards. Pretty-printing the response is recommended to help understand the output
Usage
Any _search request can be profiled by adding a top-level profile parameter:
|
Setting the top-level |
This will yield the following result:
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped" : 0,
"failed": 0
},
"hits": {
"total" : {
"value": 4,
"relation": "eq"
},
"max_score": 0.5093388,
"hits": [...]  },
"profile": {
"shards": [
{
"id": "[2aE02wS1R8q_QFnYu6vDVQ][twitter][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "message:some message:number",
"time_in_nanos": "1873811",
"breakdown": {
"score": 51306,
"score_count": 4,
"build_scorer": 2935582,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 919297,
"create_weight_count": 1,
"next_doc": 53876,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "message:some",
"time_in_nanos": "391943",
"breakdown": {
"score": 28776,
"score_count": 4,
"build_scorer": 784451,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 1669564,
"create_weight_count": 1,
"next_doc": 10111,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
}
},
{
"type": "TermQuery",
"description": "message:number",
"time_in_nanos": "210682",
"breakdown": {
"score": 4552,
"score_count": 4,
"build_scorer": 42602,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 89323,
"create_weight_count": 1,
"next_doc": 2852,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
}
}
]
}
],
"rewrite_time": 51443,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": "304311",
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": "32273"
}
]
}
]
}
],
"aggregations": []
}
]
}
}
},
"profile": {
"shards": [
{
"id": "[2aE02wS1R8q_QFnYu6vDVQ][twitter][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "message:some message:number",
"time_in_nanos": "1873811",
"breakdown": {
"score": 51306,
"score_count": 4,
"build_scorer": 2935582,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 919297,
"create_weight_count": 1,
"next_doc": 53876,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "message:some",
"time_in_nanos": "391943",
"breakdown": {
"score": 28776,
"score_count": 4,
"build_scorer": 784451,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 1669564,
"create_weight_count": 1,
"next_doc": 10111,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
}
},
{
"type": "TermQuery",
"description": "message:number",
"time_in_nanos": "210682",
"breakdown": {
"score": 4552,
"score_count": 4,
"build_scorer": 42602,
"build_scorer_count": 1,
"match": 0,
"match_count": 0,
"create_weight": 89323,
"create_weight_count": 1,
"next_doc": 2852,
"next_doc_count": 5,
"advance": 0,
"advance_count": 0,
"compute_max_score": 0,
"compute_max_score_count": 0,
"shallow_advance": 0,
"shallow_advance_count": 0,
"set_min_competitive_score": 0,
"set_min_competitive_score_count": 0
}
}
]
}
],
"rewrite_time": 51443,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": "304311",
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": "32273"
}
]
}
]
}
],
"aggregations": []
}
]
}
}
| Search results are returned, but were omitted here for brevity |
Even for a simple query, the response is relatively complicated. Let’s break it down piece-by-piece before moving to more complex examples.
First, the overall structure of the profile response is as follows:
{
"profile": {
"shards": [
{
"id": "[2aE02wS1R8q_QFnYu6vDVQ][twitter][0]",
"searches": [
{
"query": [...],  "rewrite_time": 51443,
"rewrite_time": 51443,  "collector": [...]
"collector": [...] 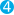 }
],
"aggregations": [...]
}
],
"aggregations": [...]  }
]
}
}
}
]
}
}
| A profile is returned for each shard that participated in the response, and is identified by a unique ID |
| Each profile contains a section which holds details about the query execution |
| Each profile has a single time representing the cumulative rewrite time |
| Each profile also contains a section about the Lucene Collectors which run the search |
| Each profile contains a section which holds the details about the aggregation execution |
Because a search request may be executed against one or more shards in an index, and a search may cover
one or more indices, the top level element in the profile response is an array of shard objects.
Each shard object lists its id which uniquely identifies the shard. The ID’s format is
[nodeID][indexName][shardID].
The profile itself may consist of one or more "searches", where a search is a query executed against the underlying
Lucene index. Most search requests submitted by the user will only execute a single search against the Lucene index.
But occasionally multiple searches will be executed, such as including a global aggregation (which needs to execute
a secondary "match_all" query for the global context).
Inside each search object there will be two arrays of profiled information:
a query array and a collector array. Alongside the search object is an aggregations object that contains the profile information for the aggregations. In the future, more sections may be added, such as suggest, highlight, etc.
There will also be a rewrite metric showing the total time spent rewriting the query (in nanoseconds).
As with other statistics apis, the Profile API supports human readable outputs. This can be turned on by adding
?human=true to the query string. In this case, the output contains the additional time field containing rounded,
human readable timing information (e.g. "time": "391,9ms", "time": "123.3micros").