
MXNET是这样压榨深度学习的内存消耗的¶
最近在学习mxnet,发现mxnet的有些思想挺好,这里试着翻译它的一篇文章,也试着了解减少内存消耗的设计原则,希望这篇文章对大家有帮助。 原文链接Squeeze the Memory Consumption of Deep Learning
深度学习的重要主题是关于训练更深度和更大型的网络。最近几年,硬件普遍升级的相当迅速,这种巨型的深度网络怪物常常对显存有更多的需求。如果同样的网络模型我们能使用更少的内存意味着我们每批输入数据可以输入更多,也能增加GPU的利用率。
这篇文章讨论了深度神经网络中如何对内存分配优化,并且提供了一些候选的解决方案。文章里所讨论的解决方案并不意味着全部完成了,但我们想其中的例子能对大部分情况有用。
计算图谱(图计算)¶
我们将从计算图谱开始讨论,这些篇幅的后面部分有一些工具可以帮助我们。图计算描述(数据流)在深度网络中的运算依赖关系。图里面的运算执行可以是细粒度也可以是粗粒度。以下给出计算图谱的两个例子。
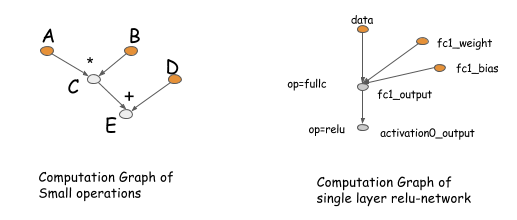
计算图谱的这些概念在如Theano,CGT的包中有深入体现。事实上,它们也隐含的存在于大多数网络结构的库中。这些库的主要区别是他们如何做梯度计算。这里有两种方法,在同一个图里用BP算法,或者用一个显式反向路径(explicit backward path)计算所需梯度。
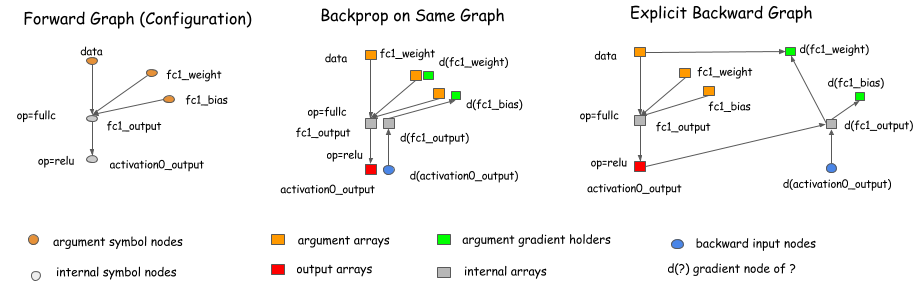
像caffe, cxxnet, torch这些库在同一个图中使用了BP算法。而像Theano, CGT 这些库使用了显式反向路径逼近算法。这篇文章中我们采用了显式反向路径,因为该方法在轮流的优化中可以带来更多的优势。
然而,我们要强调的是,选择显式反向路径法的执行并不限制我们使用Theano,
CGT库的范围。我们也可以将显式反向路径法用在基于层(前向,后向在一起)的库做梯度计算。下面的图表展示如何做到。基本上,我们可以引出一个反向节点到图的正向节点,并且在反向的操作中可以调用layer.backward
。
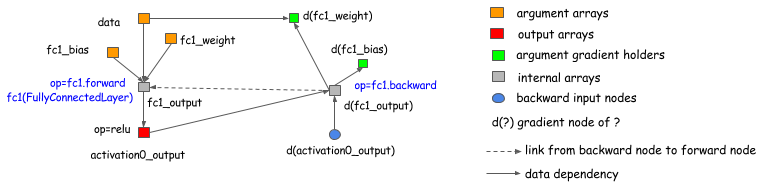
这次讨论中提供几乎所有已存在的深度学习库(这些库有些区别,比如高阶分化,这些不在本篇文章中讨论)
为什么明确反向路径更好?让我们用两个例子来解释吧。第一个原因是,明确反向路径能清晰描述计算间的依赖关系。考虑下面的情况,我们想要得到的A和B的梯度。我们可以从图中清楚地看到,d(C)的梯度计算不依赖于F,这意味着我们可以在正向计算完成后释放内存,同样C的内存也可以回收。
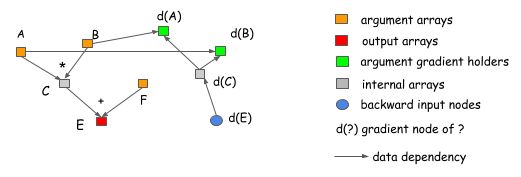
显式反向路径的另一个优点是能够有不同的反向路径而不是一个正向的镜像。一个常见的例子是分割连接情况,如下图所示。
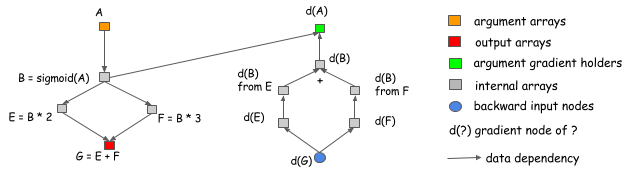
在这个例子中, 两个操作引用了B的输出。如果我们想在同一网络做梯度计算,一个显式分割层需要引入。这意味着我们需要分割正向传递。在这个图中,正向传递不包含一个分割层,但图会在通过梯度回到B之前,自动插入一个梯度聚合节点。这帮助我们节省输出分割层的内存的分配,以及在正向传递中操作复制数据的消耗。
如果我们采用计算图的显式反向视图,在正向和反向传递中是没有区别的。我们只会简单的按照计算图的拓扑顺序进行,并完成计算。这也简化了讨论。现在的问题就变成:
- 如何在每一个计算图的输出节点上分配内存?
嗯,似乎与深度学习无关,但更多的上下文编译、数据流优化等有关。但它确实是深度学习的饥饿怪兽,激励我们解决这个问题,并从中受益。
如何优化?¶
希望你能相信,图计算是内存分配优化技术中的好方法。正如你所看到的显式反向图可以已经可以节省一些内存。让我们讨论下,我们可以做什么优化和底线是什么。
假设我们要建设具有n层的神经网络。神经网络的一个典型实现是需要给每一层的输出分配节点的空间,以及反向传播梯度值。这意味着我们需要大致2n个内存单元。这在显式反向图中也一样,在反向传播节点与前向传播节点大致相同。
替代操作¶
其中第一个我们可以做的事就是替代操作内存共享。这通常是简单的操作,如激活函数。考虑以下情况,在这里我们要计算3个chained sigmoid函数的值。
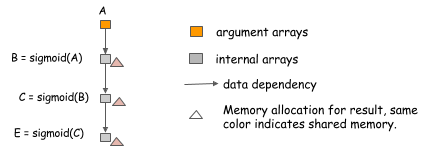
因为我们可以用代替方式计算sigmoid函数,即,为输入输出使用相同的内存区。我们可以简单地分配一份内存,并用它计算sigmoid链的任意长度。
然而,替代优化有时也是一种错误的方式,特别是这个包变的有点普通。考虑以下情况,其中,B的值不是仅由C也由F使用。
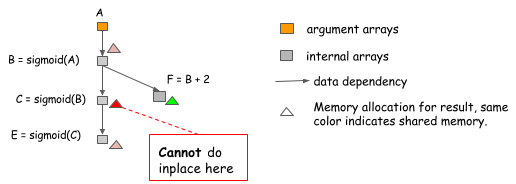
因为B的值在C=sigmoid(B)后仍然需要,我们不能执行替代优化。所以为每一个sigmoid操作做简单替代优化算法可能会落入这个陷阱,我们在做的时候必须要小心。
普通的内存共享¶
除了替代操作,内存也可以共享。考虑以下情况下,由于在我们计算了E之后,B的值是不再需要,我们可以重新使用内存来保存E的结果。
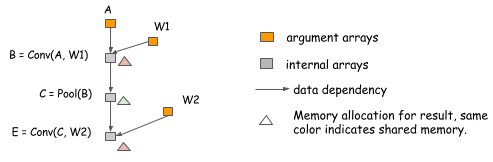
我们想指出的是在相同的数据模型上内存共享并不是必须的。在上面的例子中,B和E的模型可以是不同的,我们可以简单地按两个最大的尺寸分配内存区域,也可以在两者之间共享它。
实时神经网络分配示例¶
上面的例子都是构成情况,仅包含正向传递的计算。实际上这个思想也可以用于存储实时的神经网络。下图显示了分配方案:我们可以为一个两层感知器分配。
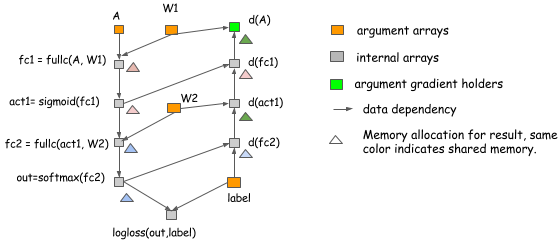
在上面的例子:
- 替代优化会被应用在计算
act1,d(fc1),out和d(fc2)。 - 内存共享被用在
d(act1)和d(A)之间。
内存分配算法¶
上一节中我们已经讨论了如何用一般的技术来优化内存分配。但是,我们也看到一些陷阱,类似于替代这是我们想要避免的情况。我们怎样才能正确地分配内存?这不是一个新的问题。例如,它与编译器寄存器分配非常相似。所以,我们可以借鉴很多思想。我们不打算在这里给出全面的技术回顾,而是介绍一些简单实用的技巧来解决问题。
关键问题是,我们要放置资源,使得它们不互相冲突。更具体地讲,每个变量有一个life time。它在计算时间和上个使用时间之间。在多层感知器的例子中,fc1的life time在act1计算后结束。
其原理是,仅允许变量在不重叠的生命周期中共享内存。有多种方式来解决这个问题。一种可能的方法是构造一个冲突的图,这个图模型每一个变量作为节点和链接边在一些具有重叠生命周期变量中,并运行一个图着色算法。这可能需要\(O(n^2)\)的时间复杂度,其中n是图中的节点的数量,这也是较为合理的消耗。
在这里我们将介绍另一种简单的有启发的方法。这样做是为了模拟遍历图的步骤,并保持未来依赖于节点的操作计数器。
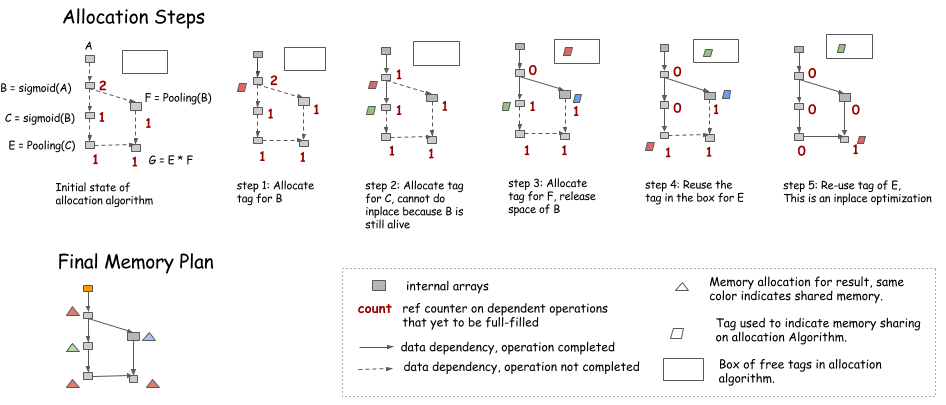
- 只有当前的操作依赖于来源时,就可以执行一个替代优化(即,
counter=1) - 当计数器变为0时,内存可以回收到在右上角的框中
- 每一次,当我们需要新的内存,我们可以从框中得到它,或分配一个新的。
其中值得注意的是,在模拟过程中,将不会分配内存,但我们可以保留每个节点需要多少内存的信息,并在最终的内存方案中分配最大共享部分。
静态VS动态分配¶
如果你仔细想想,在如python的脚本语言中,你会发现上面的策略正好模拟了动态内存分配的过程。这个计数器是每一个内存对象的引用计数器,当引用计数器变为零对象被回收。在这个意义上,我们模拟了动态内存分配一次,就创建一个静态分配方案。现在的问题是,我们可以简单地使用脚本语言去动态分配并释放内存吗?
主要的区别是静态分配只做一次,因此,我们可以使用更复杂的算法
- 例如,在内存中搜索的情形和请求内存块是比较相似的。
- 图模型也可以意识到这种分配,见下一节更多的讨论。
- 动态方式将会给快速内存分配器和垃圾收集器带来更大的压力。
此外,对那些想要回应动态内存分配的用户来说,也有另一种方法:不要获取不必要的对象引用。例如,在一个网络中,如果我们组织和存储一个列表中所有的节点,这些节点将一直有个引用(reference),让我们没有可以利用的空间分配内存。不幸的是,这是组织代码的一种常见方法。
在并行操作上分配¶
在上一节中,我们讨论我们如何模拟图计算的运行步骤,并得到一个静态分配方案。不过,在我们使用并行优化计算时有更多的问题,资源共享和并行是天平的两端。让我们来看看在同一图形下的两个分配方案:
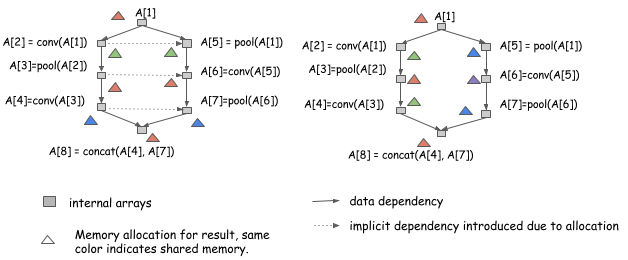
如果我们以串行方式运行从A[1]到A[8],那这两种分配方案是都有效的。然而,左侧的分配方案引入更多的依赖,意味着我们不能以并行方式运行A[2]和A[5]的计算,而右边可以运行。
我们可以看到,如果我们想要并行计算,需要更多的关注计算方面的关系。
优先保证安全和正确¶
保正正确,这是我们需要知道的第一原则。这意味着执行的这种方式需要考虑采取隐式依赖内存共享。这可以通过添加隐式依赖边到执行图模型来完成。或者更简单的,按照依赖引擎说明dependency engine note中所述,如果执行引擎意识到变化了,往序列里推送一个操作和写入同样的变量标记,这个标记表示相同的内存区域。
另一种方式是一直产生内存分配方案,这是安全的,也意味着永远都不分配同样的内存给可以并行的节点。可能这不是理想的方式,因为有时内存的减少是更可取的,我们可以在相同的GPU获取由多个计算流的执行结果,但这没有太大的提高。
尽量允许更多的并行¶
假定我们是正确的,我们现在安全的做了一些优化。总的想法是尽量鼓励在无法并行节点之间做内存共享。这又可以在分配时通过创建和查询一个父辈关系图,它耗费约\(O(n^2)\)时间来构建完成。这里我们也可以使用探索法,例如,可以将图上的路径标记好颜色。这个想法在下图所示,每次我们尝试找到一个图中最长路径,给他们标记相同的颜色,然后继续。
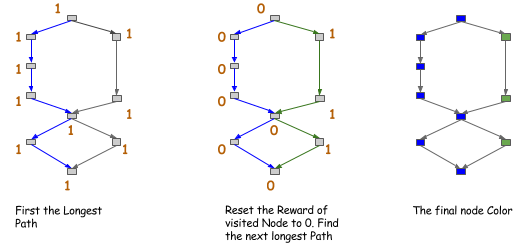
我们得到的节点的颜色之后,可以在同样颜色的节点之间共享(或鼓励这种共享)内存。这是一个比父辈关系更精确的版本,如果我们只搜索第一个k路径它的时间成本为\(O(n)\)。
这里讨论的策略是绝不是唯一的解决方案,我们希望能沿着这条路找到更多的高级方法。
我们可以节省多少内存?¶
感谢您阅读到这部分!我们已经讨论了可以用来压缩深度学习的内存使用量的技术和算法。现在问题来了,我们可以用这些技术节省多少内存?
答案是,我们可以通过使用这些技术大致减少内存消耗一半。这是已经优化的粗粒度操作图大操作。如果我们要优化一个更细粒度的计算网络,可以使用如Theano这样的库,将减少更多的内存消耗。
本文的大部分想法激发mxnet的设计。我们提供了一个内存消耗估算脚本Memory Cost Estimation Script,你可以试一下,看看我们在不同的策略下需要多少内存。
如果你要试试这个脚本,有一个选项叫forward_only,显示了只运行一个正向传递时的消耗。你会发现这个内存消耗极低。如果你读文章的前面部分,你不会感到惊讶,这是因为如果我只进行正向传递,有更多的内存被重复使用。因此,这里有两个结论:
- 使用图计算图巧妙和正确地分配内存。
- 运行深度学习预测的消耗比深度学习训练的内存消耗要少得多。
贡献说明¶
本说明是我们的提供给开源深度学习库系统设计说明的一部分。你可以通过提交pull request为此文档做贡献,我们非常欢迎!