- Data Models >
- Data Modeling Concepts >
- Data Model Design
Data Model Design¶
Effective data models support your application needs. The key consideration for the structure of your documents is the decision to embed or to use references.
Embedded Data Models¶
With MongoDB, you may embed related data in a single structure or document. These schema are generally known as “denormalized” models, and take advantage of MongoDB’s rich documents. Consider the following diagram:

Embedded data models allow applications to store related pieces of information in the same database record. As a result, applications may need to issue fewer queries and updates to complete common operations.
In general, use embedded data models when:
- you have “contains” relationships between entities. See Model One-to-One Relationships with Embedded Documents.
- you have one-to-many relationships between entities. In these relationships the “many” or child documents always appear with or are viewed in the context of the “one” or parent documents. See Model One-to-Many Relationships with Embedded Documents.
In general, embedding provides better performance for read operations, as well as the ability to request and retrieve related data in a single database operation. Embedded data models make it possible to update related data in a single atomic write operation.
However, embedding related data in documents may lead to situations where documents grow after creation. With the MMAPv1 storage engine, document growth can impact write performance and lead to data fragmentation.
In version 3.0.0, MongoDB uses Power of 2 Sized Allocations as the default allocation strategy for MMAPv1 in order to account for document growth, minimizing the likelihood of data fragmentation. See Power of 2 Sized Allocations for details. Furthermore, documents in MongoDB must be smaller than the maximum BSON document size. For bulk binary data, consider GridFS.
To interact with embedded documents, use dot notation to “reach into” embedded documents. See query for data in arrays and query data in embedded documents for more examples on accessing data in arrays and embedded documents.
Normalized Data Models¶
Normalized data models describe relationships using references between documents.
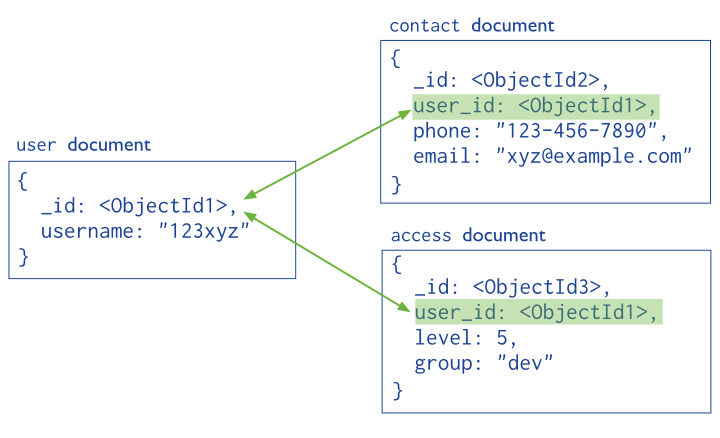
In general, use normalized data models:
- when embedding would result in duplication of data but would not provide sufficient read performance advantages to outweigh the implications of the duplication.
- to represent more complex many-to-many relationships.
- to model large hierarchical data sets.
References provides more flexibility than embedding. However, client-side applications must issue follow-up queries to resolve the references. In other words, normalized data models can require more round trips to the server.
See Model One-to-Many Relationships with Document References for an example of referencing. For examples of various tree models using references, see Model Tree Structures.