
Note
Click here to download the full example code
Using FunctionTransformer to select columns¶
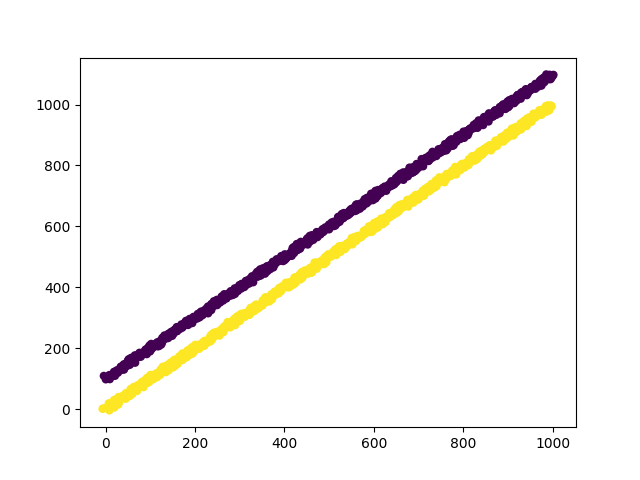
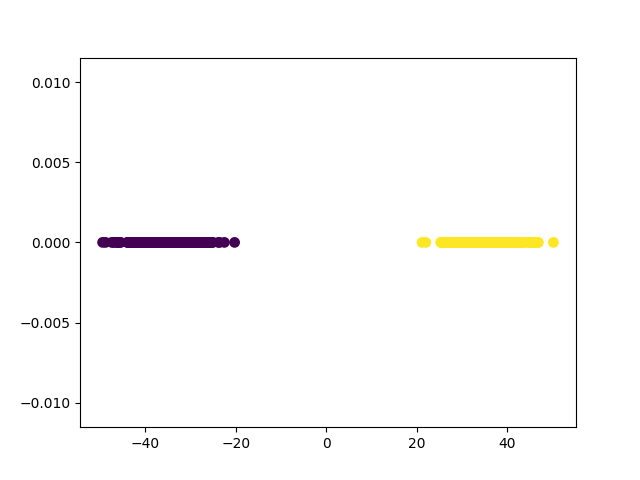
Shows how to use a function transformer in a pipeline. If you know your dataset’s first principle component is irrelevant for a classification task, you can use the FunctionTransformer to select all but the first column of the PCA transformed data.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer
def _generate_vector(shift=0.5, noise=15):
return np.arange(1000) + (np.random.rand(1000) - shift) * noise
def generate_dataset():
"""
This dataset is two lines with a slope ~ 1, where one has
a y offset of ~100
"""
return np.vstack((
np.vstack((
_generate_vector(),
_generate_vector() + 100,
)).T,
np.vstack((
_generate_vector(),
_generate_vector(),
)).T,
)), np.hstack((np.zeros(1000), np.ones(1000)))
def all_but_first_column(X):
return X[:, 1:]
def drop_first_component(X, y):
"""
Create a pipeline with PCA and the column selector and use it to
transform the dataset.
"""
pipeline = make_pipeline(
PCA(), FunctionTransformer(all_but_first_column),
)
X_train, X_test, y_train, y_test = train_test_split(X, y)
pipeline.fit(X_train, y_train)
return pipeline.transform(X_test), y_test
if __name__ == '__main__':
X, y = generate_dataset()
lw = 0
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=y, lw=lw)
plt.figure()
X_transformed, y_transformed = drop_first_component(*generate_dataset())
plt.scatter(
X_transformed[:, 0],
np.zeros(len(X_transformed)),
c=y_transformed,
lw=lw,
s=60
)
plt.show()
Total running time of the script: ( 0 minutes 0.050 seconds)