|
|
Version: 3.1.0 |
Table of Contents
wxString is a class which represents a Unicode string of arbitrary length and containing arbitrary Unicode characters.
This class has all the standard operations you can expect to find in a string class: dynamic memory management (string extends to accommodate new characters), construction from other strings, compatibility with C strings and wide character C strings, assignment operators, access to individual characters, string concatenation and comparison, substring extraction, case conversion, trimming and padding (with spaces), searching and replacing and both C-like printf (wxString::Printf) and stream-like insertion functions as well as much more - see wxString for a list of all functions.
The wxString class has been completely rewritten for wxWidgets 3.0 but much work has been done to make existing code using ANSI string literals work as it did in previous versions.
Internal wxString Encoding
Since wxWidgets 3.0 wxString may use any of UTF-16 (under Windows, using the native 16 bit wchar_t), UTF-32 (under Unix, using the native 32 bit wchar_t) or UTF-8 (under both Windows and Unix) to store its content. By default, wchar_t is used under all platforms, but wxWidgets can be compiled with wxUSE_UNICODE_UTF8=1 to use UTF-8.
For simplicity of implementation, wxString uses per code unit indexing instead of per code point indexing when using UTF-16, i.e. in the default wxUSE_UNICODE_WCHAR==1 build under Windows and doesn't know anything about surrogate pairs. In other words it always considers code points to be composed by 1 code unit, while this is really true only for characters in the BMP (Basic Multilingual Plane), as explained in more details in the Unicode Representations and Terminology section. Thus when iterating over a UTF-16 string stored in a wxString under Windows, the user code has to take care of surrogate pairs himself. (Note however that Windows itself has built-in support for surrogate pairs in UTF-16, such as for drawing strings on screen.)
- Remarks
- Note that while the behaviour of wxString when
wxUSE_UNICODE_WCHAR==1resembles UCS-2 encoding, it's not completely correct to refer to wxString as UCS-2 encoded since you can encode code points outside the BMP in a wxString as two code units (i.e. as a surrogate pair; as already mentioned however wxString will "see" them as two different code points)
In wxUSE_UNICODE_UTF8==1 case, wxString handles UTF-8 multi-bytes sequences just fine also for characters outside the BMP (it implements per code point indexing), so that you can use UTF-8 in a completely transparent way:
Example:
To better explain what stated above, consider the second string of the example above; it's composed by 3 characters and the final NULL:
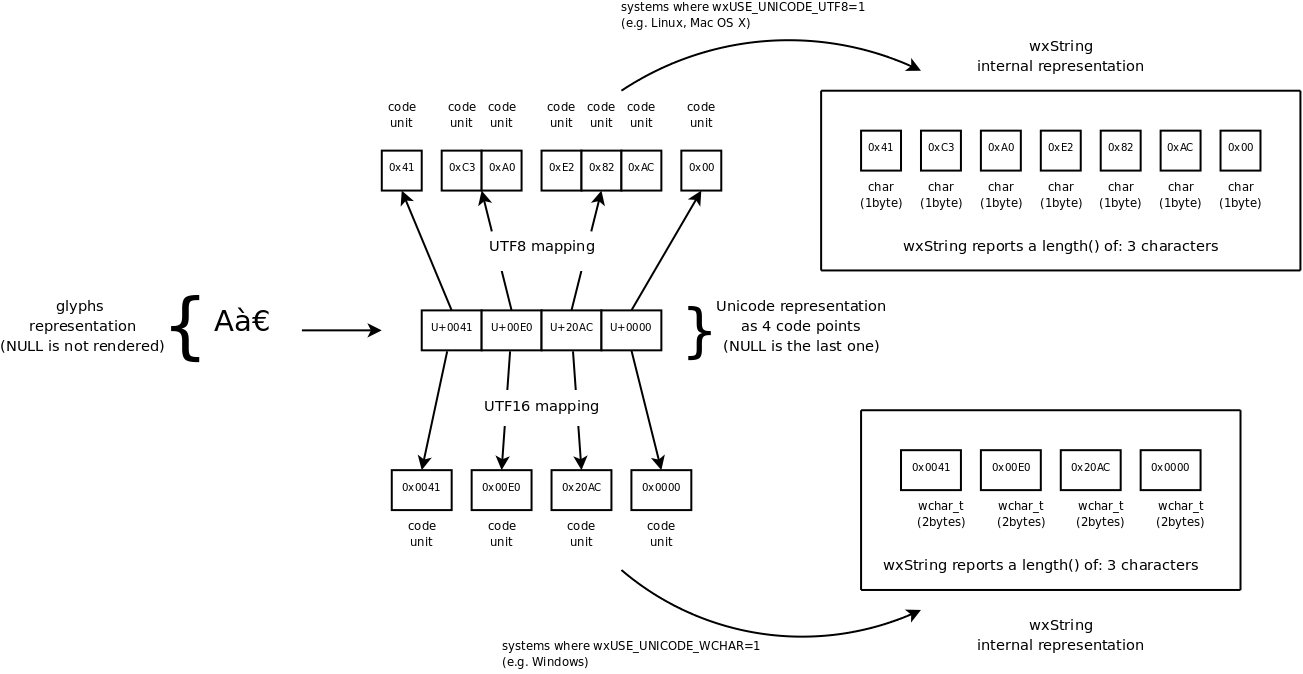
As you can see, UTF16 encoding is straightforward (for characters in the BMP) and in this example the UTF16-encoded wxString takes 8 bytes. UTF8 encoding is more elaborated and in this example takes 7 bytes.
In general, for strings containing many latin characters UTF8 provides a big advantage with regards to the memory footprint respect UTF16, but requires some more processing for common operations like e.g. length calculation.
Finally, note that the type used by wxString to store Unicode code units (wchar_t or char) is always typedef-ined to be wxStringCharType.
Using wxString to store binary data
wxString can be used to store binary data (even if it contains NULs) using the functions wxString::To8BitData and wxString::From8BitData.
Beware that even if NUL character is allowed, in the current string implementation some methods might not work correctly with them.
Note however that other classes like wxMemoryBuffer are more suited to this task. For handling binary data you may also want to look at the wxStreamBuffer, wxMemoryOutputStream, wxMemoryInputStream classes.
Comparison to Other String Classes
The advantages of using a special string class instead of working directly with C strings are so obvious that there is a huge number of such classes available. The most important advantage is the need to always remember to allocate/free memory for C strings; working with fixed size buffers almost inevitably leads to buffer overflows. At last, C++ has a standard string class (std::string). So why the need for wxString? There are several advantages:
- Efficiency: Since wxWidgets 3.0 wxString uses
std::string(in UTF8 mode under Linux, Unix and OS X) orstd::wstring(in UTF16 mode under Windows) internally by default to store its contents. wxString will therefore inherit the performance characteristics fromstd::string. - Compatibility: This class tries to combine almost full compatibility with the old wxWidgets 1.xx wxString class, some reminiscence of MFC's CString class and 90% of the functionality of
std::stringclass. - Rich set of functions: Some of the functions present in wxString are very useful but don't exist in most of other string classes: for example, wxString::AfterFirst, wxString::BeforeLast, wxString::Printf. Of course, all the standard string operations are supported as well.
- wxString is Unicode friendly: it allows to easily convert to and from ANSI and Unicode strings (see Unicode Support in wxWidgets for more details) and maps to
std::wstringtransparently. - Used by wxWidgets: And, of course, this class is used everywhere inside wxWidgets so there is no performance loss which would result from conversions of objects of any other string class (including
std::string) to wxString internally by wxWidgets.
However, there are several problems as well. The most important one is probably that there are often several functions to do exactly the same thing: for example, to get the length of the string either one of wxString::length(), wxString::Len() or wxString::Length() may be used. The first function, as almost all the other functions in lowercase, is std::string compatible. The second one is the "native" wxString version and the last one is the wxWidgets 1.xx way.
So which is better to use? The usage of the std::string compatible functions is strongly advised! It will both make your code more familiar to other C++ programmers (who are supposed to have knowledge of std::string but not of wxString), let you reuse the same code in both wxWidgets and other programs (by just typedefing wxString as std::string when used outside wxWidgets) and by staying compatible with future versions of wxWidgets which will probably start using std::string sooner or later too.
In the situations where there is no corresponding std::string function, please try to use the new wxString methods and not the old wxWidgets 1.xx variants which are deprecated and may disappear in future versions.
Advice About Using wxString
Implicit conversions
Probably the main trap with using this class is the implicit conversion operator to const char*. It is advised that you use wxString::c_str() instead to clearly indicate when the conversion is done. Specifically, the danger of this implicit conversion may be seen in the following code fragment:
There are two nasty bugs in these three lines. The first is in the call to the printf() function. Although the implicit conversion to C strings is applied automatically by the compiler in the case of
because the argument of puts() is known to be of the type const char*, this is not done for printf() which is a function with variable number of arguments (and whose arguments are of unknown types). So this call may do any number of things (including displaying the correct string on screen), although the most likely result is a program crash. The solution is to use wxString::c_str(). Just replace this line with this:
The second bug is that returning output doesn't work. The implicit cast is used again, so the code compiles, but as it returns a pointer to a buffer belonging to a local variable which is deleted as soon as the function exits, its contents are completely arbitrary. The solution to this problem is also easy, just make the function return wxString instead of a C string.
This leads us to the following general advice: all functions taking string arguments should take const wxString& (this makes assignment to the strings inside the function faster) and all functions returning strings should return wxString - this makes it safe to return local variables.
Finally note that wxString uses the current locale encoding to convert any C string literal to Unicode. The same is done for converting to and from std::string and for the return value of c_str(). For this conversion, the wxConvLibc class instance is used. See wxCSConv and wxMBConv.
Iterating wxString Characters
As previously described, when wxUSE_UNICODE_UTF8==1, wxString internally uses the variable-length UTF8 encoding. Accessing a UTF-8 string by index can be very inefficient because a single character is represented by a variable number of bytes so that the entire string has to be parsed in order to find the character. Since iterating over a string by index is a common programming technique and was also possible and encouraged by wxString using the access operator[]() wxString implements caching of the last used index so that iterating over a string is a linear operation even in UTF-8 mode.
It is nonetheless recommended to use iterators (instead of index based access) like this:
String Related Functions and Classes
As most programs use character strings, the standard C library provides quite a few functions to work with them. Unfortunately, some of them have rather counter-intuitive behaviour (like strncpy() which doesn't always terminate the resulting string with a NULL) and are in general not very safe (passing NULL to them will probably lead to program crash). Moreover, some very useful functions are not standard at all. This is why in addition to all wxString functions, there are also a few global string functions which try to correct these problems: wxIsEmpty() verifies whether the string is empty (returning true for NULL pointers), wxStrlen() also handles NULL correctly and returns 0 for them and wxStricmp() is just a platform-independent version of case-insensitive string comparison function known either as stricmp() or strcasecmp() on different platforms.
The <wx/string.h> header also defines wxSnprintf() and wxVsnprintf() functions which should be used instead of the inherently dangerous standard sprintf() and which use snprintf() instead which does buffer size checks whenever possible. Of course, you may also use wxString::Printf which is also safe.
There is another class which might be useful when working with wxString: wxStringTokenizer. It is helpful when a string must be broken into tokens and replaces the standard C library strtok() function.
And the very last string-related class is wxArrayString: it is just a version of the "template" dynamic array class which is specialized to work with strings. Please note that this class is specially optimized (using its knowledge of the internal structure of wxString) for storing strings and so it is vastly better from a performance point of view than a wxObjectArray of wxStrings.
Tuning wxString for Your Application
- Note
- This section is strictly about performance issues and is absolutely not necessary to read for using wxString class. Please skip it unless you feel familiar with profilers and relative tools.
For the performance reasons wxString doesn't allocate exactly the amount of memory needed for each string. Instead, it adds a small amount of space to each allocated block which allows it to not reallocate memory (a relatively expensive operation) too often as when, for example, a string is constructed by subsequently adding one character at a time to it, as for example in:
This is quite a common situation and not allocating extra memory at all would lead to very bad performance in this case because there would be as many memory (re)allocations as there are consonants in the original string. Allocating too much extra memory would help to improve the speed in this situation, but due to a great number of wxString objects typically used in a program would also increase the memory consumption too much.
The very best solution in precisely this case would be to use wxString::Alloc() function to preallocate, for example, len bytes from the beginning - this will lead to exactly one memory allocation being performed (because the result is at most as long as the original string).
However, using wxString::Alloc() is tedious and so wxString tries to do its best. The default algorithm assumes that memory allocation is done in granularity of at least 16 bytes (which is the case on almost all of wide-spread platforms) and so nothing is lost if the amount of memory to allocate is rounded up to the next multiple of 16. Like this, no memory is lost and 15 iterations from 16 in the example above won't allocate memory but use the already allocated pool.
The default approach is quite conservative. Allocating more memory may bring important performance benefits for programs using (relatively) few very long strings. The amount of memory allocated is configured by the setting of EXTRA_ALLOC in the file string.cpp during compilation (be sure to understand why its default value is what it is before modifying it!). You may try setting it to greater amount (say twice nLen) or to 0 (to see performance degradation which will follow) and analyse the impact of it on your program. If you do it, you will probably find it helpful to also define WXSTRING_STATISTICS symbol which tells the wxString class to collect performance statistics and to show them on stderr on program termination. This will show you the average length of strings your program manipulates, their average initial length and also the percent of times when memory wasn't reallocated when string concatenation was done but the already preallocated memory was used (this value should be about 98% for the default allocation policy, if it is less than 90% you should really consider fine tuning wxString for your application).
It goes without saying that a profiler should be used to measure the precise difference the change to EXTRA_ALLOC makes to your program.
wxString Related Compilation Settings
The main option affecting wxString is wxUSE_UNICODE which is now always defined as 1 by default to indicate Unicode support. You may set it to 0 to disable Unicode support in wxString and elsewhere in wxWidgets but this is strongly not recommended.
Another option affecting wxWidgets is wxUSE_UNICODE_WCHAR which is also 1 by default. You may want to set it to 0 and set wxUSE_UNICODE_UTF8 to 1 instead to use UTF-8 internally. wxString still provides the same API in this case, but using UTF-8 has performance implications as explained in Performance Implications of Using UTF-8, so it probably shouldn't be enabled for legacy code which might contain a lot of index-using loops.
See also Most Important Symbols for a few other options affecting wxString.