Overview¶
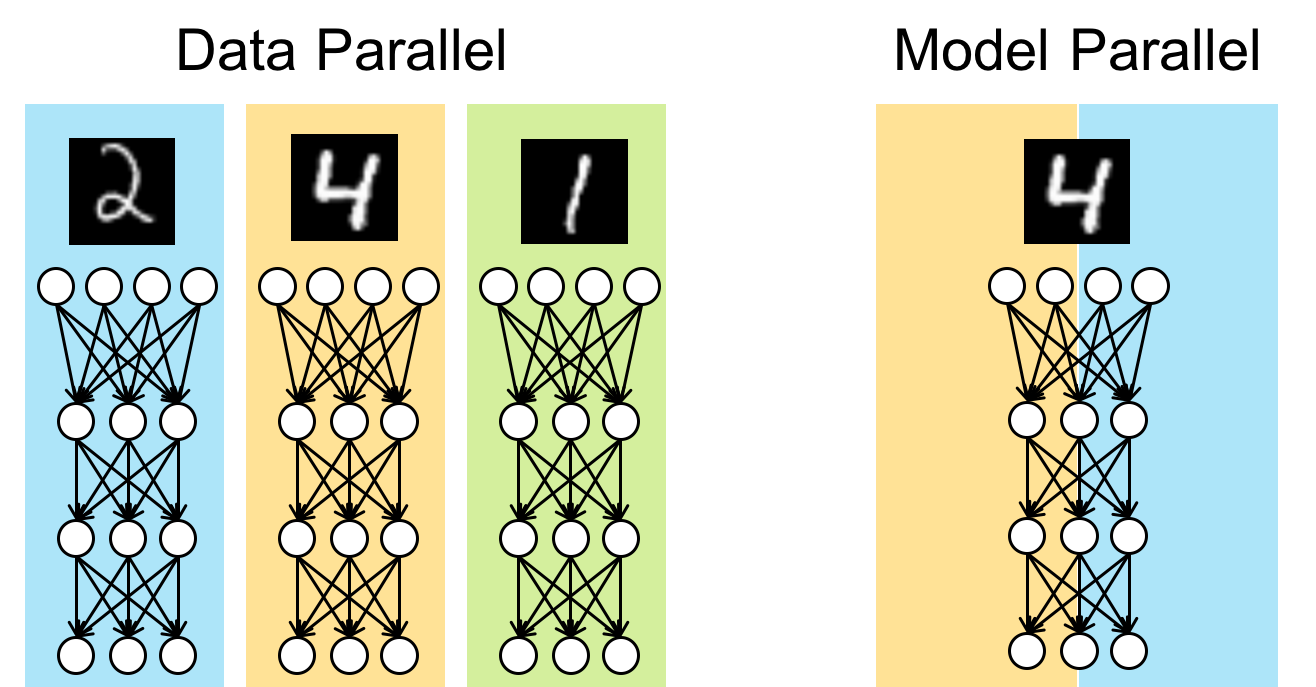
Model Parallelism¶
Even though ChainerMN mainly supports the data parallel approach for distributed training, it also has experimental APIs for the model parallel approach. The model parallel approach splits a given model into subcomponents loaded on several processes. This approach is useful in cases where
large mini-batch or high-resolusion is needed.
the model is too huge to run on a single process.
the mixture of experts are trained.
Philosophy¶
ChainerMN takes the following three approaches to realize the model parallelism.
1. Communication as Function¶
ChainerMN provides several special functions for communications such as chainermn.functions.bcast and chainermn.functions.alltoall, which wraps raw MPI communications.
Users define communications between processes as Chainer function calls in the model definitions.
This enables highly flexible communication patterns.
Moreover, parameter updates in backward propagation are automatically invoked through backward defined in those functions for communications.

2. Synchronous Model Parallel¶
ChainerMN restricts itself to synchronous SGD. Though the asynchronous counterpart seems to be more computationally efficient, asynchronous SGD often suffer from the stale gradients problem and results in difficulty while debugging. ChainerMN’s synchronous communication model makes SGD simpler.
3. Single-Program-Multiple-Data (SPMD)¶
In principle, ChainerMN supports single-program-multiple-data (SPMD), which means the same program is invoked and different data are used on each process.
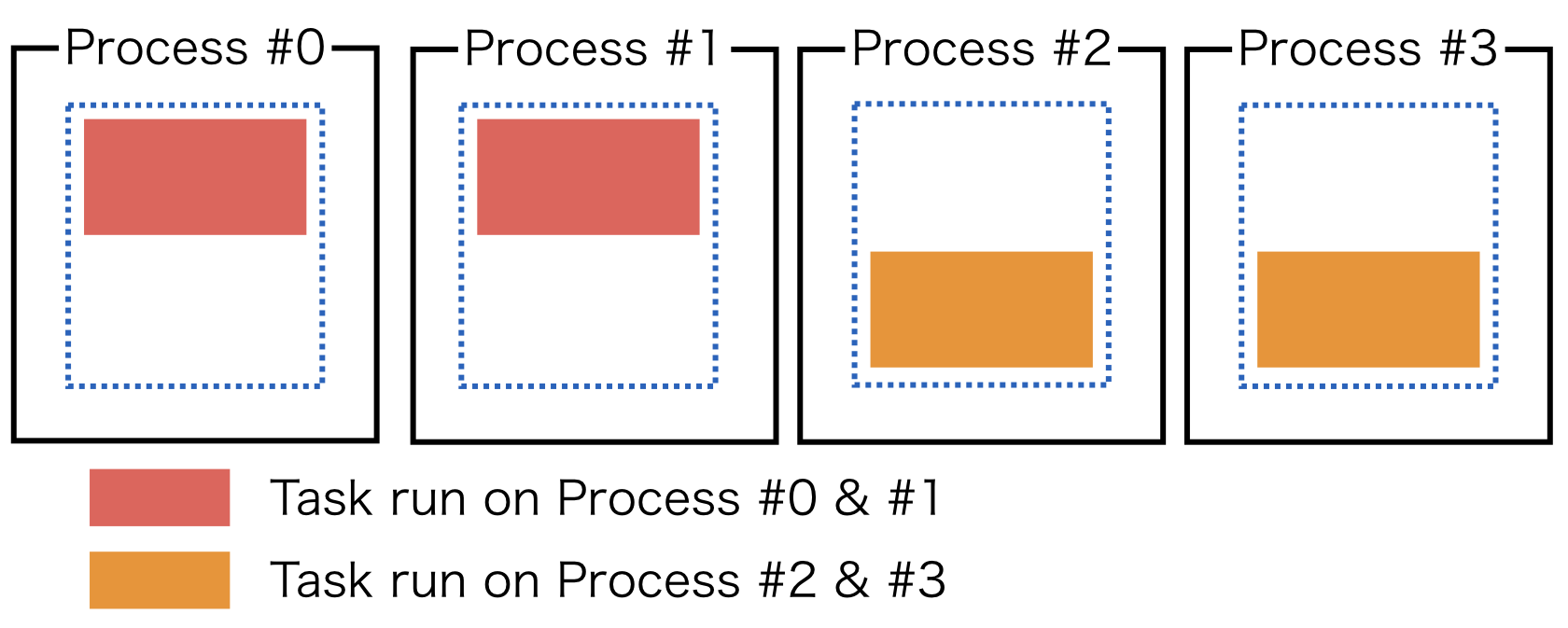
Synchronous model-parallelism suits well with MPI programming style and SPMD model.
References¶
More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
AMPNet: Asynchronous Model-Parallel Training for Dynamic Neural Networks
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism