Actions and the Dispatcher
This guide originally appeared as a post on the React blog, and has been edited and updated for inclusion here.
The Dispatcher #
The dispatcher is a singleton, and operates as the central hub of data flow in a Flux application. It is essentially a registry of callbacks, and can invoke these callbacks in order. Each store registers a callback with the dispatcher. When new data comes into the dispatcher, it then uses these callbacks to propagate that data to all of the stores. The process of invoking the callbacks is initiated through the dispatch() method, which takes a data payload object as its sole argument. This payload is typically synonymous with an action.
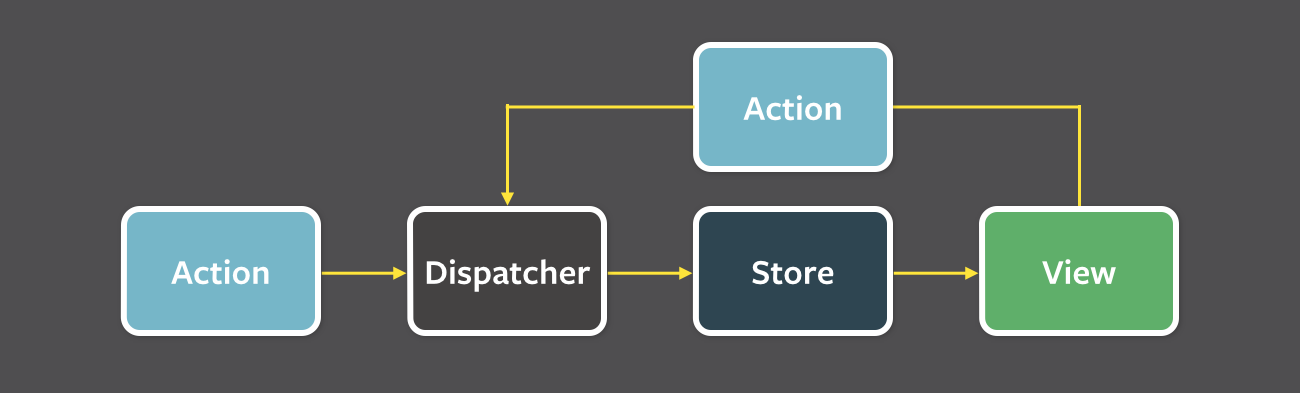
Actions and Action Creators #
When new data enters the system, whether through a person interacting with the application or through a web api call, that data is packaged into an action — an object literal containing the new fields of data and a specific action type. We often create a library of helper methods called action creators that not only create the action object, but also pass the action to the dispatcher.
Different actions are identified by a type attribute. When all of the stores receive the action, they typically use this attribute to determine if and how they should respond to it. In a Flux application, both stores and views control themselves; they are not acted upon by external objects. Actions flow into the stores through the callbacks they define and register, not through setter methods.
Letting the stores update themselves eliminates many entanglements typically found in MVC applications, where cascading updates between models can lead to unstable state and make accurate testing very difficult. The objects within a Flux application are highly decoupled, and adhere very strongly to the Law of Demeter, the principle that each object within a system should know as little as possible about the other objects in the system. This results in software that is more maintainable, adaptable, testable, and easier for new engineering team members to understand.
Why We Need a Dispatcher #
As an application grows, dependencies across different stores are a near certainty. Store A will inevitably need Store B to update itself first, so that Store A can know how to update itself. We need the dispatcher to be able to invoke the callback for Store B, and finish that callback, before moving forward with Store A. To declaratively assert this dependency, a store needs to be able to say to the dispatcher, "I need to wait for Store B to finish processing this action." The dispatcher provides this functionality through its waitFor() method.
The dispatch() method provides a simple, synchronous iteration through the callbacks, invoking each in turn. When waitFor() is encountered within one of the callbacks, execution of that callback stops and waitFor() provides us with a new iteration cycle over the dependencies. After the entire set of dependencies have been fulfilled, the original callback then continues to execute.
Further, the waitFor() method may be used in different ways for different actions, within the same store's callback. In one case, Store A might need to wait for Store B. But in another case, it might need to wait for Store C. Using waitFor() within the code block that is specific to an action allows us to have fine-grained control of these dependencies.
Problems arise, however, if we have circular dependencies. That is, if Store A needs to wait for Store B, and Store B needs to wait for Store A, we could wind up in an endless loop. The dispatcher now available in the Flux repo protects against this by throwing an informative error to alert the developer that this problem has occurred. The developer can then create a third store and resolve the circular dependency.