Table of Contents
- 18.1 Group Replication Background
- 18.2 Getting Started
- 18.3 Monitoring Group Replication
- 18.4 Group Replication Operations
- 18.5 Group Replication Security
- 18.6 Upgrading Group Replication
- 18.7 Group Replication System Variables
- 18.8 Requirements and Limitations
- 18.9 Frequently Asked Questions
- 18.10 Group Replication Technical Details
This chapter explains MySQL Group Replication and how to install, configure and monitor groups. MySQL Group Replication is a MySQL Server plugin that enables you to create elastic, highly-available, fault-tolerant replication topologies.
Groups can operate in a single-primary mode with automatic primary election, where only one server accepts updates at a time. Alternatively, for more advanced users, groups can be deployed in multi-primary mode, where all servers can accept updates, even if they are issued concurrently.
There is a built-in group membership service that keeps the view of the group consistent and available for all servers at any given point in time. Servers can leave and join the group and the view is updated accordingly. Sometimes servers can leave the group unexpectedly, in which case the failure detection mechanism detects this and notifies the group that the view has changed. This is all automatic.
The chapter is structured as follows:
Section 18.1, “Group Replication Background” provides an introduction to groups and how Group Replication works.
Section 18.2, “Getting Started” explains how to configure multiple MySQL Server instances to create a group.
Section 18.3, “Monitoring Group Replication” explains how to monitor a group.
Section 18.4, “Group Replication Operations” explains how to work with a group.
Section 18.5, “Group Replication Security” explains how to secure a group.
Section 18.6, “Upgrading Group Replication” explains how to upgrade a group.
Section 18.10, “Group Replication Technical Details” provides in-depth information about how Group Replication works.
This section provides background information on MySQL Group Replication.
The most common way to create a fault-tolerant system is to resort to making components redundant, in other words the component can be removed and the system should continue to operate as expected. This creates a set of challenges that raise complexity of such systems to a whole different level. Specifically, replicated databases have to deal with the fact that they require maintenance and administration of several servers instead of just one. Moreover, as servers are cooperating together to create the group several other classic distributed systems problems have to be dealt with, such as network partitioning or split brain scenarios.
Therefore, the ultimate challenge is to fuse the logic of the database and data replication with the logic of having several servers coordinated in a consistent and simple way. In other words, to have multiple servers agreeing on the state of the system and the data on each and every change that the system goes through. This can be summarized as having servers reaching agreement on each database state transition, so that they all progress as one single database or alternatively that they eventually converge to the same state. Meaning that they need to operate as a (distributed) state machine.
MySQL Group Replication provides distributed state machine replication with strong coordination between servers. Servers coordinate themselves automatically when they are part of the same group. The group can operate in a single-primary mode with automatic primary election, where only one server accepts updates at a time. Alternatively, for more advanced users the group can be deployed in multi-primary mode, where all servers can accept updates, even if they are issued concurrently. This power comes at the expense of applications having to work around the limitations imposed by such deployments.
There is a built-in group membership service that keeps the view of the group consistent and available for all servers at any given point in time. Servers can leave and join the group and the view is updated accordingly. Sometimes servers can leave the group unexpectedly, in which case the failure detection mechanism detects this and notifies the group that the view has changed. This is all automatic.
For a transaction to commit, the majority of the group have to agree on the order of a given transaction in the global sequence of transactions. Deciding to commit or abort a transaction is done by each server individually, but all servers make the same decision. If there is a network partition, resulting in a split where members are unable to reach agreement, then the system does not progress until this issue is resolved. Hence there is also a built-in, automatic, split-brain protection mechanism.
All of this is powered by the provided Group Communication System (GCS) protocols. These provide a failure detection mechanism, a group membership service, and safe and completely ordered message delivery. All these properties are key to creating a system which ensures that data is consistently replicated across the group of servers. At the very core of this technology lies an implementation of the Paxos algorithm. It acts as the group communication engine.
Before getting into the details of MySQL Group Replication, this section introduces some background concepts and an overview of how things work. This provides some context to help understand what is required for Group Replication and what the differences are between classic asynchronous MySQL Replication and Group Replication.
Traditional MySQL Replication provides a simple Primary-Secondary approach to replication. There is a primary (master) and there is one or more secondaries (slaves). The primary executes transactions, commits them and then they are later (thus asynchronously) sent to the secondaries to be either re-executed (in statement-based replication) or applied (in row-based replication). It is a shared-nothing system, where all servers have a full copy of the data by default.
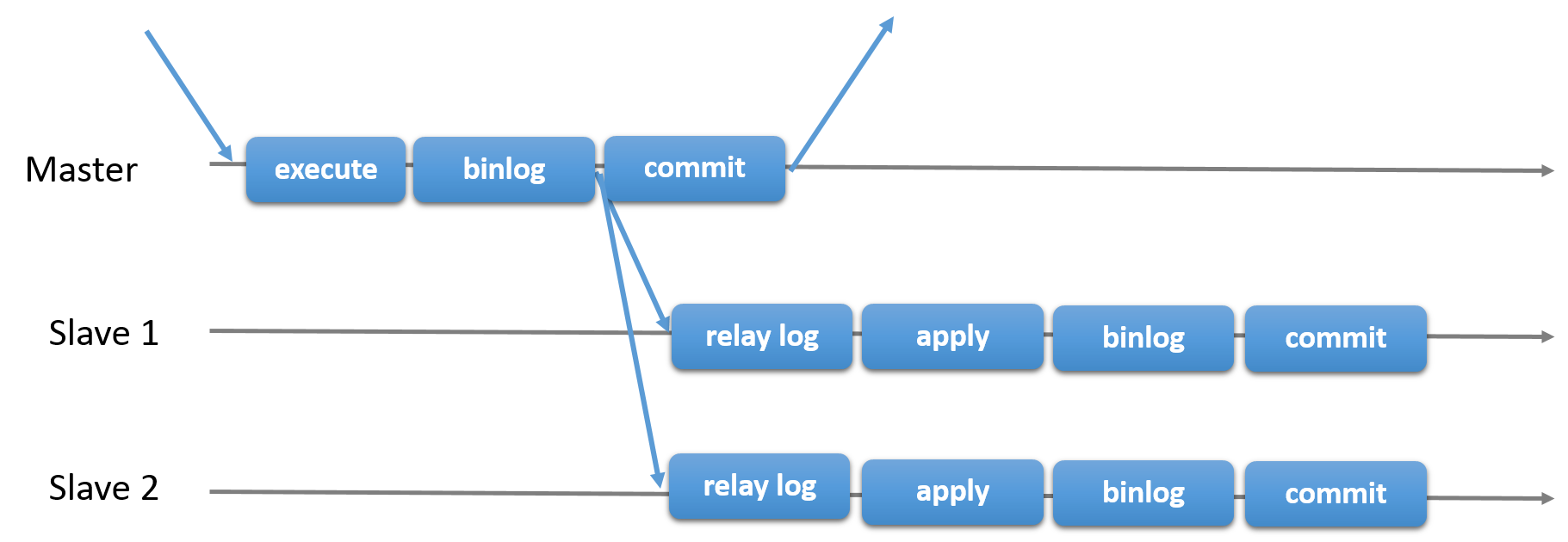
There is also semisynchronous replication, which adds one synchronization step to the protocol. This means that the Primary waits, at commit time, for the secondary to acknowledge that it has received the transaction. Only then does the Primary resume the commit operation.
In the two pictures above, you can see a diagram of the classic asynchronous MySQL Replication protocol (and its semisynchronous variant as well). Diagonal arrows represent messages exchanged between servers or messages exchanged between servers and the client application.
Group Replication is a technique that can be used to implement fault-tolerant systems. The replication group is a set of servers that interact with each other through message passing. The communication layer provides a set of guarantees such as atomic message and total order message delivery. These are very powerful properties that translate into very useful abstractions that one can resort to build more advanced database replication solutions.
MySQL Group Replication builds on top of such properties and abstractions and implements a multi-master update everywhere replication protocol. In essence, a replication group is formed by multiple servers and each server in the group may execute transactions independently. But all read-write (RW) transactions commit only after they have been approved by the group. Read-only (RO) transactions need no coordination within the group and thus commit immediately. In other words, for any RW transaction the group needs to decide whether it commits or not, thus the commit operation is not a unilateral decision from the originating server. To be precise, when a transaction is ready to commit at the originating server, the server atomically broadcasts the write values (rows changed) and the correspondent write set (unique identifiers of the rows that were updated). Then a global total order is established for that transaction. Ultimately, this means that all servers receive the same set of transactions in the same order. As a consequence, all servers apply the same set of changes in the same order, therefore they remain consistent within the group.
However, there may be conflicts between transactions that execute concurrently on different servers. Such conflicts are detected by inspecting the write sets of two different and concurrent transactions, in a process called certification. If two concurrent transactions, that executed on different servers, update the same row, then there is a conflict. The resolution procedure states that the transaction that was ordered first commits on all servers, whereas the transaction ordered second aborts, and thus is rolled back on the originating server and dropped by the other servers in the group. This is in fact a distributed first commit wins rule.
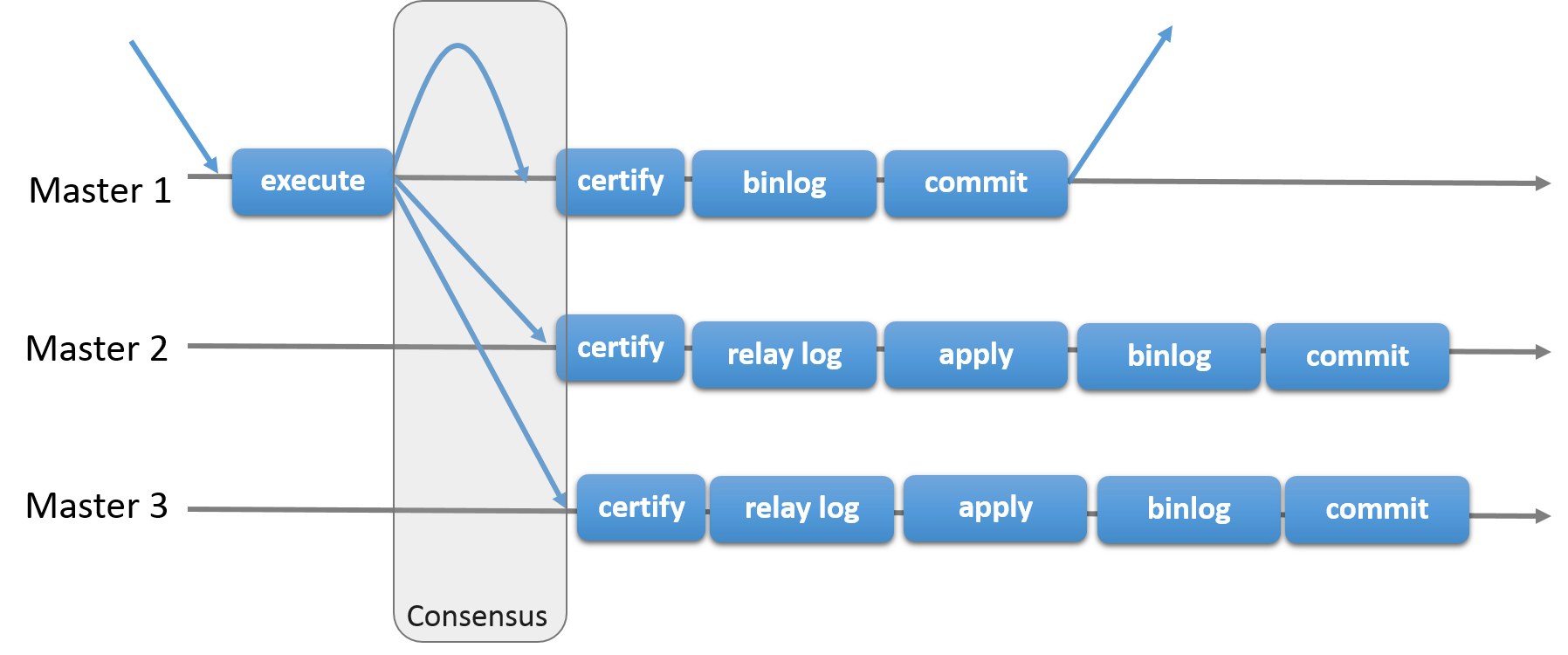
Finally, Group Replication is a shared-nothing replication scheme where each server has its own entire copy of the data.
The figure above depicts the MySQL Group Replication protocol and by comparing it to MySQL Replication (or even MySQL semisynchronous replication) you can see some differences. Note that some underlying consensus and Paxos related messages are missing from this picture for the sake of clarity.
Group Replication enables you to create fault-tolerant systems with redundancy by replicating the system state to a set of servers. Even if some of the servers subsequently fail, as long it is not all or a majority, the system is still available. Depending on the number of servers which fail the group might have degraded performance or scalability, but it is still available. Server failures are isolated and independent. They are tracked by a group membership service which relies on a distributed failure detector that is able to signal when any servers leave the group, either voluntarily or due to an unexpected halt. There is a distributed recovery procedure to ensure that when servers join the group they are brought up to date automatically. There is no need for server fail-over, and the multi-master update everywhere nature ensures that even updates are not blocked in the event of a single server failure. To summarize, MySQL Group Replication guarantees that the database service is continuously available.
It is important to understand that although the database service is available, in the event of a server crash, those clients connected to it must be redirected, or failed over, to a different server. This is not something Group Replication attempts to resolve. A connector, load balancer, router, or some form of middleware are more suitable to deal with this issue. For example see MySQL Router 8.0.
To summarize, MySQL Group Replication provides a highly available, highly elastic, dependable MySQL service.
The following examples are typical use cases for Group Replication.
Elastic Replication - Environments that require a very fluid replication infrastructure, where the number of servers has to grow or shrink dynamically and with as few side-effects as possible. For instance, database services for the cloud.
Highly Available Shards - Sharding is a popular approach to achieve write scale-out. Use MySQL Group Replication to implement highly available shards, where each shard maps to a replication group.
Alternative to Master-Slave replication - In certain situations, using a single master server makes it a single point of contention. Writing to an entire group may prove more scalable under certain circumstances.
Autonomic Systems - Additionally, you can deploy MySQL Group Replication purely for the automation that is built into the replication protocol (described already in this and previous chapters).
This section presents details about some of the services that Group Replication builds on.
There is a failure detection mechanism provided that is able to find and report which servers are silent and as such assumed to be dead. At a high level, the failure detector is a distributed service that provides information about which servers may be dead (suspicions). Later if the group agrees that the suspicions are probably true, then the group decides that a given server has indeed failed. This means that the remaining members in the group take a coordinated decision to exclude a given member.
Suspicions are triggered when servers go mute. When server A does not receive messages from server B during a given period, a timeout occurs and a suspicion is raised.
If a server gets isolated from the rest of the group, then it suspects that all others have failed. Being unable to secure agreement with the group (as it cannot secure a quorum), its suspicion does not have consequences. When a server is isolated from the group in this way, it is unable to execute any local transactions.
MySQL Group Replication relies on a group membership service. This is built into the plugin. It defines which servers are online and participating in the group. The list of online servers is often referred to as a view. Therefore, every server in the group has a consistent view of which are the members participating actively in the group at a given moment in time.
Servers have to agree not only on transaction commits, but also which is the current view. Therefore, if servers agree that a new server becomes part of the group, then the group itself is reconfigured to integrate that server in it, triggering a view change. The opposite also happens, if a server leaves the group, voluntarily or not, then the group dynamically rearranges its configuration and a view change is triggered.
Note though that when a member leaves voluntarily, it first initiates a dynamic group reconfiguration. This triggers a procedure, where all members have to agree on the new view without the leaving server. However, if a member leaves involuntarily (for example it has stopped unexpectedly or the network connection is down) then the failure detection mechanism realizes this fact and a reconfiguration of the group is proposed, this one without the failed member. As mentioned this requires agreement from the majority of servers in the group. If the group is not able to reach agreement (for example it partitioned in such a way that there is no majority of servers online), then the system is not be able to dynamically change the configuration and as such, blocks to prevent a split-brain situation. Ultimately, this means that the administrator needs to step in and fix this.
MySQL Group Replication builds on an implementation of the Paxos
distributed algorithm to provide distributed coordination
between servers. As such, it requires a majority of servers to
be active to reach quorum and thus make a decision. This has
direct impact on the number of failures the system can tolerate
without compromising itself and its overall functionality. The
number of servers (n) needed to tolerate f
failures is then n = 2 x f + 1.
In practice this means that to tolerate one failure the group must have three servers in it. As such if one server fails, there are still two servers to form a majority (two out of three) and allow the system to continue to make decisions automatically and progress. However, if a second server fails involuntarily, then the group (with one server left) blocks, because there is no majority to reach a decision.
The following is a small table illustrating the formula above.
Group Size |
Majority |
Instant Failures Tolerated |
|---|---|---|
1 |
1 |
0 |
2 |
2 |
0 |
3 |
2 |
1 |
4 |
3 |
1 |
5 |
3 |
2 |
6 |
4 |
2 |
7 |
4 |
3 |
The next Chapter covers technical aspects of Group Replication.
MySQL Group Replication is provided as a plugin to MySQL server, and each server in a group requires configuration and installation of the plugin. This section provides a detailed tutorial with the steps required to create a replication group with at least three servers.
Each of the server instances in a group can run on an independent physical machine, or on the same machine. This section explains how to create a replication group with three MySQL Server instances on one physical machine. This means that three data directories are needed, one per server instance, and that you need to configure each instance independently.
This tutorial explains how to get and deploy MySQL Server with the Group Replication plugin, how to configure each server instance before creating a group, and how to use Performance Schema monitoring to verify that everything is working correctly.
The first step is to deploy three instances of MySQL Server.
Group Replication is a built-in MySQL plugin provided with MySQL
Server 8.0. For more background information on MySQL plugins,
see Section 5.6, “MySQL Server Plugins”. This procedure assumes
that MySQL Server was downloaded and unpacked into the directory
named mysql-8.0. The following procedure uses
one physical machine, therefore each MySQL server instance
requires a specific data directory for the instance. Create the
data directories in a directory named data
and initialize each one.
mkdir datamysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s1mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s2mysql-8.0/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-8.0 --datadir=$PWD/data/s3
Inside data/s1, data/s2,
data/s3 is an initialized data directory,
containing the mysql system database and related tables and much
more. To learn more about the initialization procedure, see
Section 2.10.1, “Initializing the Data Directory”.
Do not use --initialize-insecure in
production environments, it is only used here to simplify the
tutorial. For more information on security settings, see
Section 18.5, “Group Replication Security”.
This section explains the configuration settings required for MySQL Server instances that you want to use for Group Replication. For background information, see Section 18.8.2, “Group Replication Limitations”.
To install and use the Group Replication plugin you must configure the MySQL Server instance correctly. It is recommended to store the configuration in the instance's configuration file. See Section 4.2.7, “Using Option Files” for more information. Unless stated otherwise, what follows is the configuration for the first instance in the group, referred to as s1 in this procedure. The following section shows an example server configuration.
[mysqld] # server configuration datadir=<full_path_to_data>/data/s1 basedir=<full_path_to_bin>/mysql-8.0/ port=24801 socket=<full_path_to_sock_dir>/s1.sock
These settings configure MySQL server to use the data directory created earlier and which port the server should open and start listening for incoming connections.
The non-default port of 24801 is used because in this tutorial the three server instances use the same hostname. In a setup with three different machines this would not be required.
Group Replication requires a network connection between the
members, which means that each member must be able to resolve
the network address of all of the other members. For example
in this tutorial all three instances run on one machine, so to
ensure that the members can contact each other you could add a
line to the option file such as
report_host=127.0.0.1.
The following settings configure replication according to the MySQL Group Replication requirements.
server_id=1 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE
These settings configure the server to use the unique identifier number 1, to enable global transaction identifiers, to allow execution of only statements that can be safely logged using a GTID, and to disable writing checksums for events written to the binary log.
If you are using a version of MySQL earlier than 8.0.3, where the defaults were improved for replication, you need to add these lines to the member's option file.
log_bin=binlog log_slave_updates=ON binlog_format=ROW master_info_repository=TABLE relay_log_info_repository=TABLE
These settings instruct the server to turn on binary logging, use row-based format, to store replication metadata in system tables instead of files and disable binary log event checksums. For more details see Section 18.8.1, “Group Replication Requirements”.
At this point the my.cnf file ensures
that the server is configured and is instructed to instantiate
the replication infrastructure under a given configuration.
The following section configures the Group Replication
settings for the server.
transaction_write_set_extraction=XXHASH64 group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" group_replication_start_on_boot=off group_replication_local_address= "127.0.0.1:24901" group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903" group_replication_bootstrap_group=off
Configuring
transaction_write_set_extractioninstructs the server that for each transaction it has to collect the write set and encode it as a hash using the XXHASH64 hashing algorithm. From MySQL 8.0.2, this setting is the default, so this line can be omitted.Configuring
group_replication_group_nametells the plugin that the group that it is joining, or creating, is named "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa".The value of
group_replication_group_namemust be a valid UUID. This UUID is used internally when setting GTIDs for Group Replication events in the binary log. UseSELECT UUID()to generate a UUID.Configuring
group_replication_start_on_bootinstructs the plugin to not start operations automatically when the server starts. This is important when setting up Group Replication as it ensures you can configure the server before manually starting the plugin. Once the member is configured you can setgroup_replication_start_on_bootto on so that Group Replication starts automatically upon server boot.Configuring
group_replication_local_addresstells the plugin to use the network address 127.0.0.1 and port 24901 for internal communication with other members in the group.ImportantGroup Replication uses this address for internal member-to-member connections involving remote instances of the group communication engine (XCom, a Paxos variant). This address must be different to the hostname and port used for SQL and it must not be used for client applications. It must be reserved for internal communication between the members of the group while running Group Replication.
The network address configured by
group_replication_local_addressmust be resolvable by all group members. For example, if each server instance is on a different machine with a fixed network address, you could use the IP address of the machine, such as 10.0.0.1. If you use a host name, you must use a fully qualified name, and ensure it is resolvable through DNS, correctly configured/etc/hostsfiles, or other name resolution processes. From MySQL 8.0.14, IPv6 addresses (or host names that resolve to them) can be used as well as IPv4 addresses. A group can contain a mix of members using IPv6 and members using IPv4. For more information on Group Replication support for IPv6 networks and on mixed IPv4 and IPv6 groups, see Section 18.4.5, “Support For IPv6 And For Mixed IPv6 And IPv4 Groups”.The recommended port for
group_replication_local_addressis 33061. In this tutorial we use three server instances running on one machine, thus ports 24901 to 24903 are used for the internal communication network address.group_replication_local_addressis used by Group Replication as the unique identifier for a group member within the replication group. You can use the same port for all members of a replication group as long as the host names or IP addresses are all different, and as demonstrated in this tutorial, you can use the same host name or IP address for all members as long as the ports are all different.Configuring
group_replication_group_seedssets the hostname and port of the group members which are used by the new member to establish its connection to the group. These members are called the seed members. Once the connection is established, the group membership information is listed atperformance_schema.replication_group_members. Usually thegroup_replication_group_seedslist contains thehostname:portof each of the group member'sgroup_replication_local_address, but this is not obligatory and a subset of the group members can be chosen as seeds.ImportantThe
hostname:portlisted ingroup_replication_group_seedsis the seed member's internal network address, configured bygroup_replication_local_addressand not the SQLhostname:portused for client connections, and shown for example inperformance_schema.replication_group_memberstable.The server that starts the group does not make use of this option, since it is the initial server and as such, it is in charge of bootstrapping the group. In other words, any existing data which is on the server bootstrapping the group is what is used as the data for the next joining member. The second server joining asks the one and only member in the group to join, any missing data on the second server is replicated from the donor data on the bootstrapping member, and then the group expands. The third server joining can ask any of these two to join, data is synchronized to the new member, and then the group expands again. Subsequent servers repeat this procedure when joining.
WarningWhen joining multiple servers at the same time, make sure that they point to seed members that are already in the group. Do not use members that are also joining the group as seeds, because they may not yet be in the group when contacted.
It is good practice to start the bootstrap member first, and let it create the group. Then make it the seed member for the rest of the members that are joining. This ensures that there is a group formed when joining the rest of the members.
Creating a group and joining multiple members at the same time is not supported. It may work, but chances are that the operations race and then the act of joining the group ends up in an error or a time out.
A joining member must communicate with a seed member using the same protocol (IPv4 or IPv6) that the seed member advertises in the
group_replication_group_seedsoption. For the purpose of IP address whitelisting for Group Replication, the whitelist on the seed member must include an IP address for the joining member for the protocol offered by the seed member, or a host name that resolves to an address for that protocol. This address or host name must be set up and whitelisted in addition to the joining member'sgroup_replication_local_addressif the protocol for that address does not match the seed member's advertised protocol. If a joining member does not have a whitelisted address for the appropriate protocol, its connection attempt is refused. For more information, see Section 18.5.1, “IP Address Whitelisting”.Configuring
group_replication_bootstrap_groupinstructs the plugin whether to bootstrap the group or not.ImportantThis option must only be used on one server instance at any time, usually the first time you bootstrap the group (or in case the entire group is brought down and back up again). If you bootstrap the group multiple times, for example when multiple server instances have this option set, then they could create an artificial split brain scenario, in which two distinct groups with the same name exist. Disable this option after the first server instance comes online.
Configuration for all servers in the group is quite similar.
You need to change the specifics about each server (for
example server_id,
datadir,
group_replication_local_address).
This is illustrated later in this tutorial.
Group Replication uses the asynchronous replication protocol to
achieve
Section 18.10.5, “Distributed Recovery”,
synchronizing group members before joining them to the group.
The distributed recovery process relies on a replication channel
named group_replication_recovery which is
used to transfer transactions from donor members to members that
join the group. Therefore you need to set up a replication user
with the correct permissions so that Group Replication can
establish direct member-to-member recovery replication channels.
Start the server using the options file:
mysql-8.0/bin/mysqld --defaults-file=data/s1/s1.cnf
Create a MySQL user with the
REPLICATION-SLAVE privilege. This
process can be captured in the binary log and then you can rely
on distributed recovery to replicate the statements used to
create the user. Alternatively, you can disable binary logging
and then create the user manually on each member, for example if
you want to avoid the changes being propagated to other server
instances. To disable binary logging, connect to server s1 and
issue the following statements:
mysql> SET SQL_LOG_BIN=0;
In the following example the user
rpl_user with the password
password is shown. When configuring
your servers use a suitable user name and password.
mysql>CREATE USERmysql>rpl_user@'%' IDENTIFIED BY 'password';GRANT REPLICATION SLAVE ON *.* TOmysql>rpl_user@'%';FLUSH PRIVILEGES;
If binary logging was disabled, enable it again once the user has been created.
mysql> SET SQL_LOG_BIN=1;
Once the user has been configured, use the
CHANGE MASTER TO statement to
configure the server to use the given credentials for the
group_replication_recovery replication
channel the next time it needs to recover its state from another
member. Issue the following, replacing
rpl_user and
password with the values used when
creating the user.
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' \\
FOR CHANNEL 'group_replication_recovery';
Distributed recovery is the first step taken by a server that
joins the group and does not have the same set of transactions
as the group members. If these credentials are not set correctly
for the group_replication_recovery
replication channel and the rpl_user as
shown, the server cannot connect to the donor members and run
the distributed recovery process to gain synchrony with the
other group members, and hence ultimately cannot join the group.
Similarly, if the server cannot correctly identify the other
members via the server's hostname the
recovery process can fail. It is recommended that operating
systems running MySQL have a properly configured unique
hostname, either using DNS or local settings.
This hostname can be verified in the
Member_host column of the
performance_schema.replication_group_members
table. If multiple group members externalize a default
hostname set by the operating system, there
is a chance of the member not resolving to the correct member
address and not being able to join the group. In such a
situation use report_host to
configure a unique hostname to be
externalized by each of the servers.
By default, users created in MySQL 8 use
Section 6.5.1.3, “Caching SHA-2 Pluggable Authentication”. If
the rpl_user you configure for
distributed recovery uses the caching SHA-2 authentication
plugin and you are not using
Section 18.5.2, “Secure Socket Layer Support (SSL)”
for the group_replication_recovery
replication channel, RSA key-pairs are used for password
exchange, see Section 6.4.3, “Creating SSL and RSA Certificates and Keys”. You
can either copy the public key of the
rpl_user to the member that should recover
its state from the group, or configure the donors to provide
the public key when requested.
The more secure approach is to copy the public key of the
rpl_user to the member that should recover
the group state from the donors. Then you need to configure
the
group_replication_recovery_public_key_path
system variable on the member joining the group with the path
to the public key for the rpl_user.
Optionally, a less secure approach is to set
group_replication_recovery_get_public_key=ON
on donors so that they provide the public key of the
rpl_user to members when they join the
group. There is no way to verify the identity of a server,
therefore only set
group_replication_recovery_get_public_key=ON
when you are sure there is no risk of server identity being
compromised, for example by a man-in-the-middle attack.
Once server s1 has been configured and started, install the Group Replication plugin. Connect to the server and issue the following command:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
The mysql.session user must exist before
you can load Group Replication.
mysql.session was added in MySQL version
8.0.2. If your data dictionary was initialized using an
earlier version you must perform the MySQL upgrade procedure
(see Section 2.11, “Upgrading MySQL”). If the upgrade is not run,
Group Replication fails to start with the error message
There was an error when trying to access the server
with user: mysql.session@localhost. Make sure the user is
present in the server and that mysql_upgrade was ran after a
server update..
To check that the plugin was installed successfully, issue
SHOW PLUGINS; and check the output. It should
show something like this:
mysql> SHOW PLUGINS;
+----------------------------+----------+--------------------+----------------------+-------------+
| Name | Status | Type | Library | License |
+----------------------------+----------+--------------------+----------------------+-------------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | PROPRIETARY |
(...)
| group_replication | ACTIVE | GROUP REPLICATION | group_replication.so | PROPRIETARY |
+----------------------------+----------+--------------------+----------------------+-------------+
To start the group, instruct server s1 to bootstrap the group
and then start Group Replication. This bootstrap should only be
done by a single server, the one that starts the group and only
once. This is why the value of the bootstrap configuration
option was not saved in the configuration file. If it is saved
in the configuration file, upon restart the server automatically
bootstraps a second group with the same name. This would result
in two distinct groups with the same name. The same reasoning
applies to stopping and restarting the plugin with this option
set to ON.
SET GLOBAL group_replication_bootstrap_group=ON; START GROUP_REPLICATION; SET GLOBAL group_replication_bootstrap_group=OFF;
Once the START GROUP_REPLICATION
statement returns, the group has been started. You can check
that the group is now created and that there is one member in
it:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| group_replication_applier | ce9be252-2b71-11e6-b8f4-00212844f856 | myhost | 24801 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
The information in this table confirms that there is a member in
the group with the unique identifier
ce9be252-2b71-11e6-b8f4-00212844f856, that it
is ONLINE and is at myhost
listening for client connections on port
24801.
For the purpose of demonstrating that the server is indeed in a group and that it is able to handle load, create a table and add some content to it.
mysql>CREATE DATABASE test;mysql>USE test;mysql>CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);mysql>INSERT INTO t1 VALUES (1, 'Luis');
Check the content of table t1 and the binary
log.
mysql>SELECT * FROM t1;+----+------+ | c1 | c2 | +----+------+ | 1 | Luis | +----+------+ mysql>SHOW BINLOG EVENTS;+---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+ | binlog.000001 | 4 | Format_desc | 1 | 123 | Server ver: 8.0.2-gr080-log, Binlog ver: 4 | | binlog.000001 | 123 | Previous_gtids | 1 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' | | binlog.000001 | 211 | Query | 1 | 270 | BEGIN | | binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724817264259180:1 | | binlog.000001 | 369 | Query | 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' | | binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test | | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' | | binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) | | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' | | binlog.000001 | 831 | Query | 1 | 899 | BEGIN | | binlog.000001 | 899 | Table_map | 1 | 942 | table_id: 108 (test.t1) | | binlog.000001 | 942 | Write_rows | 1 | 984 | table_id: 108 flags: STMT_END_F | | binlog.000001 | 984 | Xid | 1 | 1011 | COMMIT /* xid=38 */ | +---------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
As seen above, the database and the table objects were created and their corresponding DDL statements were written to the binary log. Also, the data was inserted into the table and written to the binary log. The importance of the binary log entries is illustrated in the following section when the group grows and distributed recovery is executed as new members try to catch up and become online.
At this point, the group has one member in it, server s1, which has some data in it. It is now time to expand the group by adding the other two servers configured previously.
In order to add a second instance, server s2, first create the
configuration file for it. The configuration is similar to the
one used for server s1, except for things such as the location
of the data directory, the ports that s2 is going to be
listening on or its
server_id. These different
lines are highlighted in the listing below.
[mysqld] # server configuration datadir=<full_path_to_data>/data/s2 basedir=<full_path_to_bin>/mysql-8.0/ port=24802 socket=<full_path_to_sock_dir>/s2.sock # # Replication configuration parameters # server_id=2 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE # # Group Replication configuration # transaction_write_set_extraction=XXHASH64 group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" group_replication_start_on_boot=off group_replication_local_address= "127.0.0.1:24902" group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903" group_replication_bootstrap_group= off
Similar to the procedure for server s1, with the option file in place you launch the server.
mysql-8.0/bin/mysqld --defaults-file=data/s2/s2.cnf
Then configure the recovery credentials as follows. The commands are the same as used when setting up server s1 as the user is shared within the group. Issue the following statements on s2.
SET SQL_LOG_BIN=0;CREATE USERrpl_user@'%' IDENTIFIED BY 'password';GRANT REPLICATION SLAVE ON *.* TOrpl_user@'%';SET SQL_LOG_BIN=1;CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' \\ FOR CHANNEL 'group_replication_recovery';
If you are using the caching SHA-2 authentication plugin, the default in MySQL 8, see Using Group Replication and the Caching SHA-2 User Credentials Plugin.
Install the Group Replication plugin and start the process of joining the server to the group. The following example installs the plugin in the same way as used while deploying server s1.
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
Add server s2 to the group.
mysql> START GROUP_REPLICATION;
Unlike the previous steps that were the same as those executed
on s1, here there is a difference in that you do
not issue SET GLOBAL
group_replication_bootstrap_group=ON; before
starting Group Replication, because the group has already been
created and bootstrapped by server s1. At this point server s2
only needs to be added to the already existing group.
When Group Replication starts successfully and the server
joins the group it checks the
super_read_only variable.
By setting super_read_only
to ON in the member's configuration file, you can
ensure that servers which fail when starting Group
Replication for any reason do not accept transactions. If
the server should join the group as read-write instance, for
example as the primary in a single-primary group or as a
member of a multi-primary group, when the
super_read_only variable is
set to ON then it is set to OFF upon joining the group.
Checking the
performance_schema.replication_group_members
table again shows that there are now two
ONLINE servers in the group.
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | myhost | 24801 | ONLINE |
| group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | myhost | 24802 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
As server s2 is also marked as ONLINE, it must have already caught up with server s1 automatically. Verify that it has indeed synchronized with server s1 as follows.
mysql>SHOW DATABASES LIKE 'test';+-----------------+ | Database (test) | +-----------------+ | test | +-----------------+ mysql>SELECT * FROM test.t1;+----+------+ | c1 | c2 | +----+------+ | 1 | Luis | +----+------+ mysql>SHOW BINLOG EVENTS;+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+ | binlog.000001 | 4 | Format_desc | 2 | 123 | Server ver: 8.0.3-log, Binlog ver: 4 | | binlog.000001 | 123 | Previous_gtids | 2 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' | | binlog.000001 | 211 | Query | 1 | 270 | BEGIN | | binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724832985483517:1 | | binlog.000001 | 369 | Query | 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' | | binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test | | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' | | binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) | | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' | | binlog.000001 | 831 | Query | 1 | 890 | BEGIN | | binlog.000001 | 890 | Table_map | 1 | 933 | table_id: 108 (test.t1) | | binlog.000001 | 933 | Write_rows | 1 | 975 | table_id: 108 flags: STMT_END_F | | binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT /* xid=30 */ | | binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:5' | | binlog.000001 | 1063 | Query | 1 | 1122 | BEGIN | | binlog.000001 | 1122 | View_change | 1 | 1261 | view_id=14724832985483517:2 | | binlog.000001 | 1261 | Query | 1 | 1326 | COMMIT | +---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
As seen above, the second server has been added to the group and it has replicated the changes from server s1 automatically. According to the distributed recovery procedure, this means that just after joining the group and immediately before being declared online, server s2 has connected to server s1 automatically and fetched the missing data from it. In other words, it copied transactions from the binary log of s1 that it was missing, up to the point in time that it joined the group.
Adding additional instances to the group is essentially the same sequence of steps as adding the second server, except that the configuration has to be changed as it had to be for server s2. To summarise the required commands:
1. Create the configuration file
[mysqld] # server configuration datadir=<full_path_to_data>/data/s3 basedir=<full_path_to_bin>/mysql-8.0/ port=24803 socket=<full_path_to_sock_dir>/s3.sock # # Replication configuration parameters # server_id=3 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE # # Group Replication configuration # group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" group_replication_start_on_boot=off group_replication_local_address= "127.0.0.1:24903" group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903" group_replication_bootstrap_group= off
2. Start the server
mysql-8.0/bin/mysqld --defaults-file=data/s3/s3.cnf
3. Configure the recovery credentials for the group_replication_recovery channel.
SET SQL_LOG_BIN=0; CREATE USERrpl_user@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TOrpl_user@'%'; FLUSH PRIVILEGES; SET SQL_LOG_BIN=1; CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='password' \\ FOR CHANNEL 'group_replication_recovery';
4. Install the Group Replication plugin and start it.
INSTALL PLUGIN group_replication SONAME 'group_replication.so'; START GROUP_REPLICATION;
At this point server s3 is booted and running, has joined the
group and caught up with the other servers in the group.
Consulting the
performance_schema.replication_group_members
table again confirms this is the case.
mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+---------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+-------------+-------------+---------------+ | group_replication_applier | 395409e1-6dfa-11e6-970b-00212844f856 | myhost | 24801 | ONLINE | | group_replication_applier | 7eb217ff-6df3-11e6-966c-00212844f856 | myhost | 24803 | ONLINE | | group_replication_applier | ac39f1e6-6dfa-11e6-a69d-00212844f856 | myhost | 24802 | ONLINE | +---------------------------+--------------------------------------+-------------+-------------+---------------+
Issuing this same query on server s2 or server s1 yields the same result. Also, you can verify that server s3 has also caught up:
mysql>SHOW DATABASES LIKE 'test';+-----------------+ | Database (test) | +-----------------+ | test | +-----------------+ mysql>SELECT * FROM test.t1;+----+------+ | c1 | c2 | +----+------+ | 1 | Luis | +----+------+ mysql>SHOW BINLOG EVENTS;+---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+ | binlog.000001 | 4 | Format_desc | 3 | 123 | Server ver: 8.0.3-log, Binlog ver: 4 | | binlog.000001 | 123 | Previous_gtids | 3 | 150 | | | binlog.000001 | 150 | Gtid | 1 | 211 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1' | | binlog.000001 | 211 | Query | 1 | 270 | BEGIN | | binlog.000001 | 270 | View_change | 1 | 369 | view_id=14724832985483517:1 | | binlog.000001 | 369 | Query | 1 | 434 | COMMIT | | binlog.000001 | 434 | Gtid | 1 | 495 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:2' | | binlog.000001 | 495 | Query | 1 | 585 | CREATE DATABASE test | | binlog.000001 | 585 | Gtid | 1 | 646 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:3' | | binlog.000001 | 646 | Query | 1 | 770 | use `test`; CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL) | | binlog.000001 | 770 | Gtid | 1 | 831 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:4' | | binlog.000001 | 831 | Query | 1 | 890 | BEGIN | | binlog.000001 | 890 | Table_map | 1 | 933 | table_id: 108 (test.t1) | | binlog.000001 | 933 | Write_rows | 1 | 975 | table_id: 108 flags: STMT_END_F | | binlog.000001 | 975 | Xid | 1 | 1002 | COMMIT /* xid=29 */ | | binlog.000001 | 1002 | Gtid | 1 | 1063 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:5' | | binlog.000001 | 1063 | Query | 1 | 1122 | BEGIN | | binlog.000001 | 1122 | View_change | 1 | 1261 | view_id=14724832985483517:2 | | binlog.000001 | 1261 | Query | 1 | 1326 | COMMIT | | binlog.000001 | 1326 | Gtid | 1 | 1387 | SET @@SESSION.GTID_NEXT= 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:6' | | binlog.000001 | 1387 | Query | 1 | 1446 | BEGIN | | binlog.000001 | 1446 | View_change | 1 | 1585 | view_id=14724832985483517:3 | | binlog.000001 | 1585 | Query | 1 | 1650 | COMMIT | +---------------+------+----------------+-----------+-------------+--------------------------------------------------------------------+
Use the Perfomance Schema tables to monitor Group Replication, assuming that the Performance Schema is enabled. Group Replication adds the following tables:
These Perfomance Schema replication tables also show information about Group Replication:
performance_schema.replication_connection_statusshows information regarding Group Replication, for example the transactions that have been received from the group and queued in the applier queue (the relay log).performance_schema.replication_applier_statusshows the state of the Group Replication related channels and threads If there are many different worker threads applying transactions, then the worker tables can also be used to monitor what each worker thread is doing.
The replication channels created by the Group Replication plugin are named:
group_replication_recovery- This channel is used for the replication changes that are related to the distributed recovery phase.group_replication_applier- This channel is used for the incoming changes from the group. This is the channel used to apply transactions coming directly from the group.
The following sections describe how to interpret the information available.
There are various states that a server instance can be in. If servers are communicating properly, all report the same states for all servers. However, if there is a network partition, or a server leaves the group, then different information could be reported, depending on which server is queried. If the server has left the group then it cannot report updated information about the other servers' states. If there is a partition, such that quorum is lost, servers are not able to coordinate between themselves. As a consequence, they cannot guess what the status of different servers is. Therefore, instead of guessing their state they report that some servers are unreachable.
Table 18.1 Server State
Field |
Description |
Group Synchronized |
|---|---|---|
|
The member is ready to serve as a fully functional group member, meaning that the client can connect and start executing transactions. |
Yes |
|
The member is in the process of becoming an active member of the group and is currently going through the recovery process, receiving state information from a donor. |
No |
|
The plugin is loaded but the member does not belong to any group. |
No |
|
The state of the member. Whenever there is an error on the recovery phase or while applying changes, the server enters this state. |
No |
|
Whenever the local failure detector suspects that a given
server is not reachable, because for example it was
disconnected involuntarily, it shows that server's state
as |
No |
Once an instance enters ERROR state, the
super_read_only option is set
to ON. To leave the ERROR
state you must manually configure the instance with
super_read_only=OFF.
Note that Group Replication is not synchronous, but eventually synchronous. More precisely, transactions are delivered to all group members in the same order, but their execution is not synchronized, meaning that after a transaction is accepted to be committed, each member commits at its own pace.
The
performance_schema.replication_group_members
table is used for monitoring the status of the different server
instances that are members of the group. The information in the
table is updated whenever there is a view change, for example when
the configuration of the group is dynamically changed when a new
member joins. At that point, servers exchange some of their
metadata to synchronize themselves and continue to cooperate
together. The information is shared between all the server
instances that are members of the replication group, so
information on all the group members can be queried from any
member. This table can be used to get a high level view of the
state of a replication group, for example by issuing:
SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 041f26d8-f3f3-11e8-adff-080027337932 | example1 | 3306 | ONLINE | SECONDARY | 8.0.13 |
| group_replication_applier | f60a3e10-f3f2-11e8-8258-080027337932 | example2 | 3306 | ONLINE | PRIMARY | 8.0.13 |
| group_replication_applier | fc890014-f3f2-11e8-a9fd-080027337932 | example3 | 3306 | ONLINE | SECONDARY | 8.0.13 |
+---------------------------+--------------------------------------+--------------+-------------+--------------+-------------+----------------+
Based on this result we can see that the group consists of three
members, each member's host and port number which clients use to
connect to the member, and the
server_uuid of the member. The
MEMBER_STATE column shows one of the
Section 18.3.1, “Group Replication Server States”, in this case it
shows that all three members in this group are
ONLINE, and the MEMBER_ROLE
column shows that there are two secondaries, and a single primary.
Therefore this group must be running in single-primary mode. The
MEMBER_VERSION column can be useful when you
are upgrading a group and are combining members running different
MySQL versions. See
Section 18.3.1, “Group Replication Server States” for more
information.
For more information about the Member_host
value and its impact on the distributed recovery process, see
Section 18.2.1.3, “User Credentials”.
Each member in a replication group certifies and applies transactions received by the group. Statistics regarding the certifier and applier procedures are useful to understand how the applier queue is growing, how many conflicts have been found, how many transactions were checked, which transactions are committed everywhere, and so on.
The
performance_schema.replication_group_member_stats
table provides group-level information related to the
certification process, and also statistics for the transactions
received and originated by each individual member of the
replication group. The information is shared between all the
server instances that are members of the replication group, so
information on all the group members can be queried from any
member. Note that refreshing of statistics for remote members is
controlled by the message period specified in the
group_replication_flow_control_period
option, so these can differ slightly from the locally collected
statistics for the member where the query is made.
Table 18.2 replication_group_member_stats
Field |
Description |
|---|---|
Channel_name |
The name of the Group Replication channel. |
View_id |
The current view identifier for this group. |
Member_id |
The member server UUID. This has a different value for each member in the group. This also serves as a key because it is unique to each member. |
Count_transactions_in_queue |
The number of transactions in the queue pending conflict detection checks. Once the transactions have been checked for conflicts, if they pass the check, they are queued to be applied as well. |
Count_transactions_checked |
The number of transactions that have been checked for conflicts. |
Count_conflicts_detected |
The number of transactions that did not pass the conflict detection check. |
Count_transactions_rows_validating |
The current size of the conflict detection database (against which each transaction is certified). |
Transactions_committed_all_members |
The transactions that have been successfully committed on all members of the replication group. This is updated at a fixed time interval. |
Last_conflict_free_transaction |
The transaction identifier of the last conflict free transaction checked. |
Count_transactions_remote_in_applier_queue |
The number of transactions that this member has received from the replication group which are waiting to be applied. |
Count_transactions_remote_applied |
The number of transactions that this member has received from the replication group which have been applied. |
Count_transactions_local_proposed |
The number of transactions that this member originated and sent to the replication group for coordination. |
Count_transactions_local_rollback |
The number of transactions that this member originated that were rolled back after being sent to the replication group. |
These fields are important for monitoring the performance of the members connected in the group. For example, suppose that one of the group’s members is delayed and is not able to keep up to date with the other members of the group. In this case you might see a large number of transactions in the queue. Based on this information, you could decide to either remove the member from the group, or delay the processing of transactions on the other members of the group in order to reduce the number of queued transactions. This information can also help you to decide how to adjust the flow control of the Group Replication plugin.
This section describes the different modes of deploying Group Replication, explains common operations for managing groups and provides information about how to tune your groups. .
Group Replication operates in the following different modes:
single-primary mode
multi-primary mode
The default mode is single-primary. It is not possible to have members of the group deployed in different modes, for example one configured in multi-primary mode while another one is in single-primary mode. To switch between modes, the group and not the server, needs to be restarted with a different operating configuration. Regardless of the deployed mode, Group Replication does not handle client-side fail-over, that must be handled by the application itself, a connector or a middleware framework such as a proxy or MySQL Router 8.0.
When deployed in multi-primary mode, statements are checked to ensure they are compatible with the mode. The following checks are made when Group Replication is deployed in multi-primary mode:
If a transaction is executed under the SERIALIZABLE isolation level, then its commit fails when synchronizing itself with the group.
If a transaction executes against a table that has foreign keys with cascading constraints, then the transaction fails to commit when synchronizing itself with the group.
These checks can be deactivated by setting the option
group_replication_enforce_update_everywhere_checks
to FALSE. When deploying in single-primary
mode, this option must be set to
FALSE.
In this mode the group has a single-primary server that is set
to read-write mode. All the other members in the group are set
to read-only mode (with
super-read-only=ON
). This happens automatically. The primary is typically the
first server to bootstrap the group, all other servers that join
automatically learn about the primary server and are set to read
only.
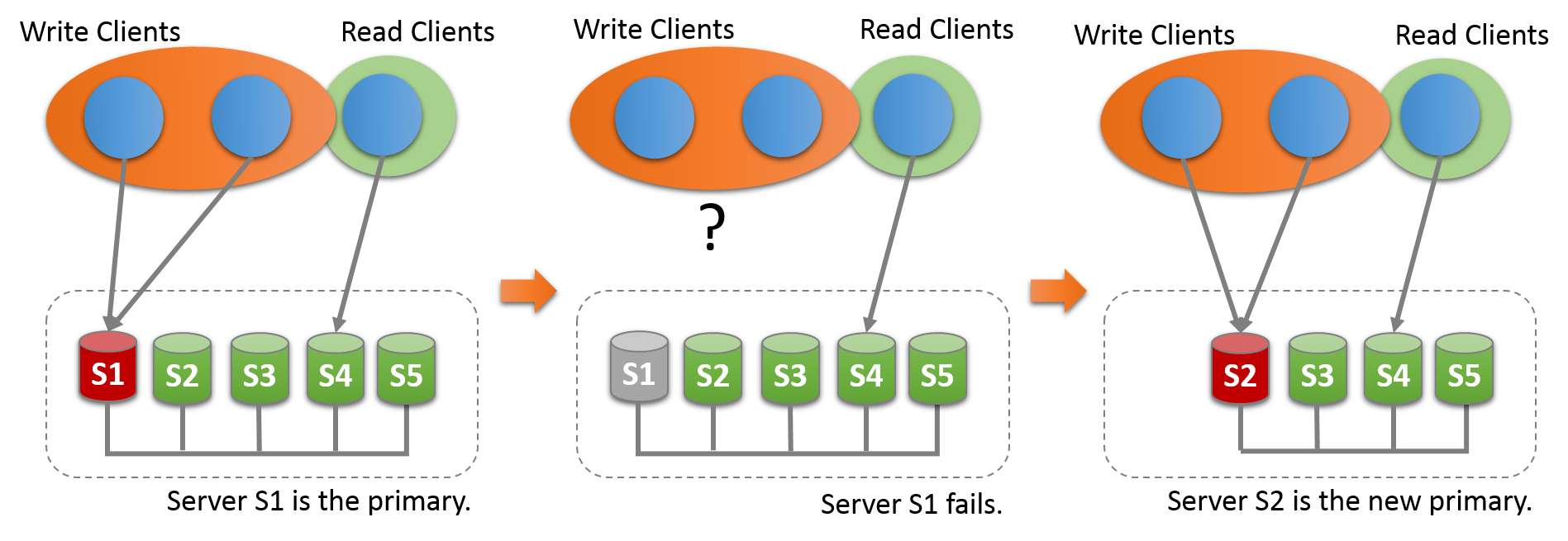
When in single-primary mode, some of the checks deployed in
multi-primary mode are disabled, because the system enforces
that only a single server writes to the group. For example,
changes to tables that have cascading foreign keys are allowed,
whereas in multi-primary mode they are not. Upon primary member
failure, an automatic primary election mechanism chooses the new
primary member. The election process is performed by looking at
the new view, and ordering the potential new primaries based on
the value of
group_replication_member_weight.
Assuming the group is operating with all members running the
same MySQL version, then the member with the highest value for
group_replication_member_weight
is elected as the new primary. In the event that multiple
servers have the same
group_replication_member_weight,
the servers are then prioritized based on their
server_uuid in lexicographical
order and by picking the first one. Once a new primary is
elected, it is automatically set to read-write and the other
secondaries remain as secondaries, and as such, read-only.
When a new primary is elected, it is only writable once it has processed all of the transactions that came from the old primary. This avoids possible concurrency issues between old transactions from the old primary and the new ones being executed on this member. It is a good practice to wait for the new primary to apply its replication related relay-log before re-routing client applications to it.
If the group is operating with members that are running
different versions of MySQL then the election process can be
impacted. For example, if any member does not support
group_replication_member_weight,
then the primary is chosen based on
server_uuid order from the
members of the lower major version. Alternatively, if all
members running different MySQL versions do support
group_replication_member_weight,
the primary is chosen based on
group_replication_member_weight
from the members of the lower major version.
In multi-primary mode, there is no notion of a single primary. There is no need to engage an election procedure because there is no server playing any special role.
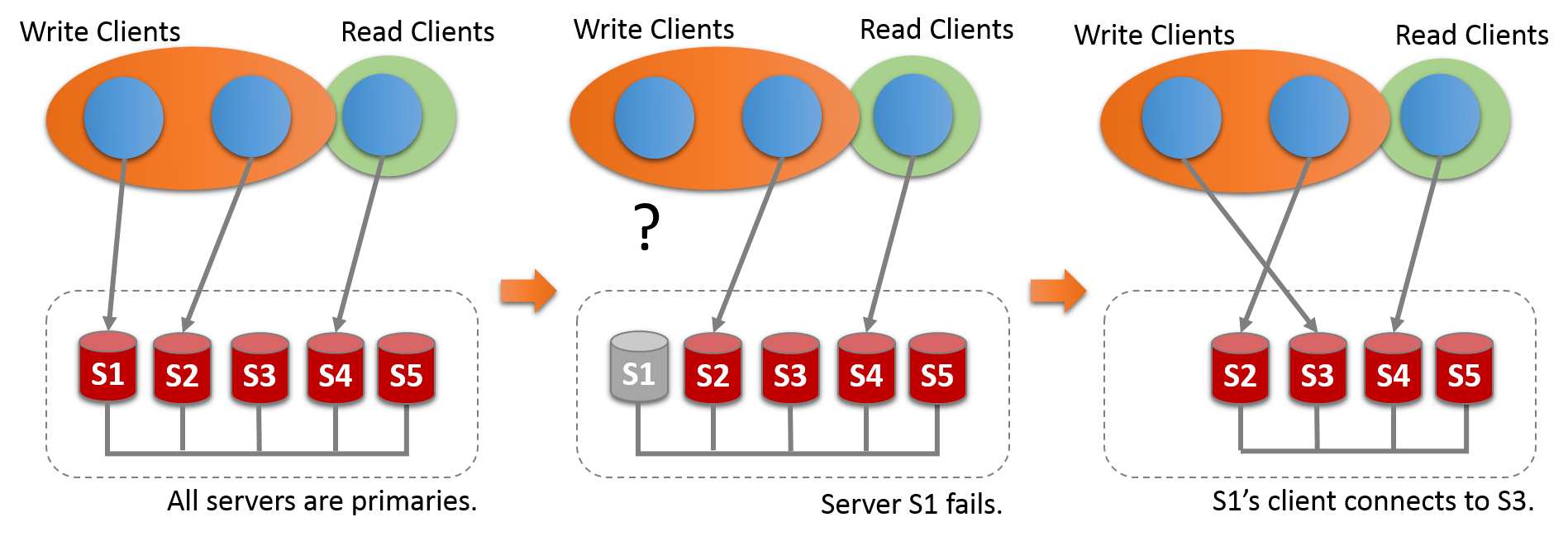
All servers are set to read-write mode when joining the group.
To find out which server is currently the primary when deployed
in single-primary mode, use the MEMBER_ROLE
column in the
performance_schema.replication_group_members
table. For example:
mysql> SELECT MEMBER_HOST, MEMBER_ROLE FROM performance_schema.replication_group_members;
+-------------------------+-------------+
| MEMBER_HOST | MEMBER_ROLE |
+-------------------------+-------------+
| remote1.example.com | PRIMARY |
| remote2.example.com | SECONDARY |
| remote3.example.com | SECONDARY |
+-------------------------+-------------+
The group_replication_primary_member status
variable has been deprecated and is scheduled to be removed in
a future version.
Alternatively use the
group_replication_primary_member
status variable.
mysql> SHOW STATUS LIKE 'group_replication_primary_member'
You can configure an online group while Group Replication is running by using a set of UDFs, which rely on a group action coordinator. These UDFs are installed by the Group Replication plugin in version 8.0.13 and higher. This section describes how changes are made to a running group, and the available UDFs.
For the coordinator to be able to configure group wide actions on a running group, all members must be running MySQL 8.0.13 or later and have the UDFs installed.
To use the UDFs, connect to a member of the running group and
issue the UDF with the SELECT
statement. The Group Replication plugin processes the action and
its parameters and the coordinator sends it to all members which
are visible to the member where you issued the UDF. If the action
is accepted, all members execute the action and send a termination
message when completed. Once all members declare the action as
finished, the invoking member returns the result to the client.
When configuring a whole group, the distributed nature of the operations means that they interact with many processes of the Group Replication plugin, and therefore you should observe the following:
You can issue configuration operations everywhere. If you want to make member A the new primary you do not need to invoke the operation on member A. All operations are sent and executed in a coordinated way on all group members. Also, this distributed execution of an operation has a different ramification: if the invoking member dies, any already running configuration process continues to run on other members. In the unlikely event that the invoking member dies, you can still use the monitoring features to ensure other members complete the operation successfully.
All members must be online. To simplify the migration or election processes and guarantee they are as fast as possible, the group must not contain any member in recovery, otherwise the configuration action is rejected by the member where you issue the statement.
No members can join a group during a configuration change. Any member that attempts to join the group during a coordinated configuration change leaves the group and cancels its join process.
Only one configuration at once. A group which is executing a configuration change cannot accept any other group configuration change, because concurrent configuration operations could lead to member divergence.
You cannot use configuration functions on mixed version groups. Due to the distributed nature of the these configuration actions, all members must recognize them in order to execute them. Therefore, no server of an older version can be present in the group, otherwise the operation is rejected.
This section explains how to change which member of a single-primary group is the primary. The function used to change a group's mode can be run on any member.
Use the
group_replication_set_as_primary()
UDF to change which member is the primary in a single-primary
group. This function has no effect if issued on a member of a
multi-primary group. Only a primary member can write to the
group, so if an asynchronous channel is running on that
member, no switch is allowed until the asynchronous channel is
stopped. Pass in the
server_uuid of the member
which you want to become the new primary of the group by
issuing:
SELECT group_replication_set_as_primary(member_uuid);
While the action runs, you can check its progress by issuing:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%";
+----------------------------------------------------------------------------------+----------------+----------------+
| event_name | work_completed | work_estimated |
+----------------------------------------------------------------------------------+----------------+----------------+
| stage/group_rpl/Primary Election: Waiting for members to turn on super_read_only | 3 | 5 |
+----------------------------------------------------------------------------------+----------------+----------------+
This section explains how to change the mode which a group is running in, either single or multi-primary. The functions used to change a group's mode can be run on any member.
Use the
group_replication_switch_to_single_primary_mode()
UDF to change a group running in multi-primary mode to
single-primary mode by issuing:
SELECT group_replication_switch_to_single_primary_mode()
If no string is passed in, the election of the new primary in the resulting single-primary group is controlled by the configured election weights, or UUID lexicographic order (see Section 18.4.1.1, “Single-Primary Mode”). While the action runs, you can check its progress by issuing:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%";
+----------------------------------------------------------------------------+----------------+----------------+
| event_name | work_completed | work_estimated |
+----------------------------------------------------------------------------+----------------+----------------+
| stage/group_rpl/Primary Switch: waiting for pending transactions to finish | 4 | 20 |
+----------------------------------------------------------------------------+----------------+----------------+
To override the election process and configure a specific
member of the multi-primary group as the new primary in the
process, get the server_uuid
of the member and pass it to
group_replication_switch_to_single_primary_mode().
For example issue:
SELECT group_replication_switch_to_single_primary_mode(member_uuid);
Use the
group_replication_switch_to_multi_primary_mode()
UDF to change a group running in single-primary mode to
multi-primary mode by issuing:
SELECT group_replication_switch_to_multi_primary_mode()
After some coordinated group operations to ensure the safety and consistency of your data, all members which belong to the group become primaries.
While the action runs, you can check its progress by issuing:
SELECT event_name, work_completed, work_estimated FROM performance_schema.events_stages_current WHERE event_name LIKE "%stage/group_rpl%"; +----------------------------------------------------------------------+----------------+----------------+ | event_name | work_completed | work_estimated | +----------------------------------------------------------------------+----------------+----------------+ | stage/group_rpl/Multi-primary Switch: applying buffered transactions | 0 | 1 | +----------------------------------------------------------------------+----------------+----------------+
This section explains how to inspect and configure the maximum number of consensus instances at any time for a group. This maximum is referred to as the event horizon for a group, and is the maximum number of consensus instances that the group can execute in parallel. This enables you to fine tune the performance of your Group Replication deployment. For example, the default value of 10 is suitable for a group running on a LAN, but for groups operating over a slower network such as a WAN, increase this number to improve performance.
Use the
group_replication_get_write_concurrency()
UDF to inspect a group's event horizon value at runtime by
issuing:
SELECT group_replication_get_write_concurrency();
Use the
group_replication_set_write_concurrency()
UDF to set the maximum number of consensus instances that the
system can execute in parallel by issuing:
SELECT group_replication_set_write_concurrency(instances);
where instances is the new maximum
number of consensus instances.
Whenever a new member joins a replication group, it connects to a suitable donor and fetches the data that it has missed up until the point it is declared online. This critical component in Group Replication is fault tolerant and configurable. The following section explains how recovery works and how to tune the settings
A random donor is selected from the existing online members in the group. This way there is a good chance that the same server is not selected more than once when multiple members enter the group.
If the connection to the selected donor fails, a new connection is automatically attempted to a new candidate donor. Once the connection retry limit is reached the recovery procedure terminates with an error.
A donor is picked randomly from the list of online members in the current view.
The other main point of concern in recovery as a whole is to make sure that it copes with failures. Hence, Group Replication provides robust error detection mechanisms. In earlier versions of Group Replication, when reaching out to a donor, recovery could only detect connection errors due to authentication issues or some other problem. The reaction to such problematic scenarios was to switch over to a new donor thus a new connection attempt was made to a different member.
This behavior was extended to also cover other failure scenarios:
Purged data scenarios - If the selected donor contains some purged data that is needed for the recovery process then an error occurs. Recovery detects this error and a new donor is selected.
Duplicated data - If a server joining the group already contains some data that conflicts with the data coming from the selected donor during recovery then an error occurs. This could be caused by some errant transactions present in the server joining the group.
One could argue that recovery should fail instead of switching over to another donor, but in heterogeneous groups there is chance that other members share the conflicting transactions and others do not. For that reason, upon error, recovery selects another donor from the group.
Other errors - If any of the recovery threads fail (receiver or applier threads fail) then an error occurs and recovery switches over to a new donor.
In case of some persistent failures or even transient failures recovery automatically retries connecting to the same or a new donor.
The recovery data transfer relies on the binary log and existing MySQL replication framework, therefore it is possible that some transient errors could cause errors in the receiver or applier threads. In such cases, the donor switch over process has retry functionality, similar to that found in regular replication.
The number of attempts a server joining the group makes when
trying to connect to a donor from the pool of donors is 10. This
is configured through the
group_replication_recovery_retry_count
plugin variable . The following command sets the maximum number
of attempts to connect to a donor to 10.
mysql> SET GLOBAL group_replication_recovery_retry_count= 10;
Note that this accounts for the global number of attempts that the server joining the group makes connecting to each one of the suitable donors.
The
group_replication_recovery_reconnect_interval
plugin variable defines how much time the recovery process
should sleep between donor connection attempts. This variable
has its default set to 60 seconds and you can change this value
dynamically. The following command sets the recovery donor
connection retry interval to 120 seconds.
mysql> SET GLOBAL group_replication_recovery_reconnect_interval= 120;
Note, however, that recovery does not sleep after every donor
connection attempt. As the server joining the group is
connecting to different servers and not to the same one over and
over again, it can assume that the problem that affects server A
does not affect server B. As such, recovery suspends only when
it has gone through all the possible donors. Once the server
joining the group has tried to connect to all the suitable
donors in the group and none remains, the recovery process
sleeps for the number of seconds configured by the
group_replication_recovery_reconnect_interval
variable.
The group needs to achieve consensus whenever a change that needs to be replicated happens. This is the case for regular transactions but is also required for group membership changes and some internal messaging that keeps the group consistent. Consensus requires a majority of group members to agree on a given decision. When a majority of group members is lost, the group is unable to progress and blocks because it cannot secure majority or quorum.
Quorum may be lost when there are multiple involuntary failures, causing a majority of servers to be removed abruptly from the group. For example in a group of 5 servers, if 3 of them become silent at once, the majority is compromised and thus no quorum can be achieved. In fact, the remaining two are not able to tell if the other 3 servers have crashed or whether a network partition has isolated these 2 alone and therefore the group cannot be reconfigured automatically.
On the other hand, if servers exit the group voluntarily, they instruct the group that it should reconfigure itself. In practice, this means that a server that is leaving tells others that it is going away. This means that other members can reconfigure the group properly, the consistency of the membership is maintained and the majority is recalculated. For example, in the above scenario of 5 servers where 3 leave at once, if the 3 leaving servers warn the group that they are leaving, one by one, then the membership is able to adjust itself from 5 to 2, and at the same time, securing quorum while that happens.
Loss of quorum is by itself a side-effect of bad planning. Plan the group size for the number of expected failures (regardless whether they are consecutive, happen all at once or are sporadic).
The following sections explain what to do if the system partitions in such a way that no quorum is automatically achieved by the servers in the group.
A primary that has been excluded from a group after a majority loss followed by a reconfiguration can contain extra transactions that are not included in the new group. If this happens, the attempt to add back the excluded member from the group results in an error with the message This member has more executed transactions than those present in the group.
The replication_group_members
performance schema table presents the status of each server in
the current view from the perspective of this server. The
majority of the time the system does not run into partitioning,
and therefore the table shows information that is consistent
across all servers in the group. In other words, the status of
each server on this table is agreed by all in the current view.
However, if there is network partitioning, and quorum is lost,
then the table shows the status UNREACHABLE
for those servers that it cannot contact. This information is
exported by the local failure detector built into Group
Replication.
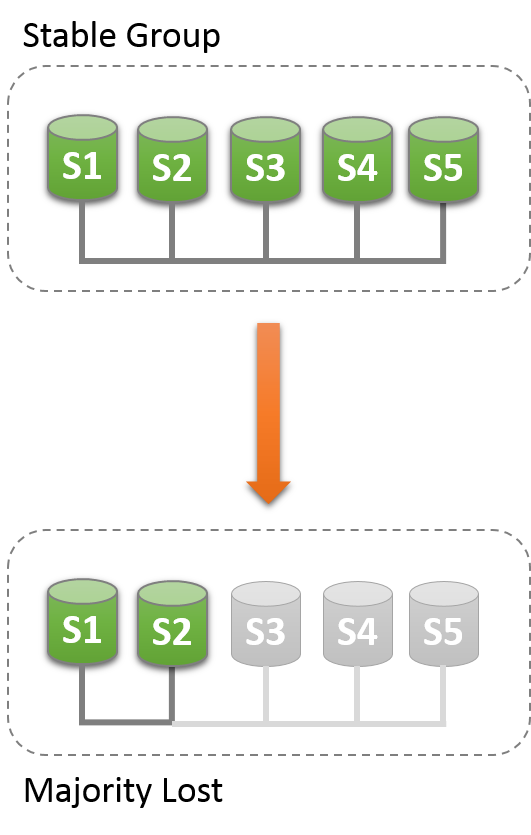
To understand this type of network partition the following section describes a scenario where there are initially 5 servers working together correctly, and the changes that then happen to the group once only 2 servers are online. The scenario is depicted in the figure.
As such, lets assume that there is a group with these 5 servers in it:
Server s1 with member identifier
199b2df7-4aaf-11e6-bb16-28b2bd168d07Server s2 with member identifier
199bb88e-4aaf-11e6-babe-28b2bd168d07Server s3 with member identifier
1999b9fb-4aaf-11e6-bb54-28b2bd168d07Server s4 with member identifier
19ab72fc-4aaf-11e6-bb51-28b2bd168d07Server s5 with member identifier
19b33846-4aaf-11e6-ba81-28b2bd168d07
Initially the group is running fine and the servers are happily
communicating with each other. You can verify this by logging
into s1 and looking at its
replication_group_members
performance schema table. For example:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | ONLINE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | ONLINE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
However, moments later there is a catastrophic failure and
servers s3, s4 and s5 stop unexpectedly. A few seconds after
this, looking again at the
replication_group_members table on
s1 shows that it is still online, but several others members are
not. In fact, as seen below they are marked as
UNREACHABLE. Moreover, the system could not
reconfigure itself to change the membership, because the
majority has been lost.
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
The table shows that s1 is now in a group that has no means of progressing without external intervention, because a majority of the servers are unreachable. In this particular case, the group membership list needs to be reset to allow the system to proceed, which is explained in this section. Alternatively, you could also choose to stop Group Replication on s1 and s2 (or stop completely s1 and s2), figure out what happened with s3, s4 and s5 and then restart Group Replication (or the servers).
Group replication enables you to reset the group membership list
by forcing a specific configuration. For instance in the case
above, where s1 and s2 are the only servers online, you could
chose to force a membership configuration consisting of only s1
and s2. This requires checking some information about s1 and s2
and then using the
group_replication_force_members
variable.
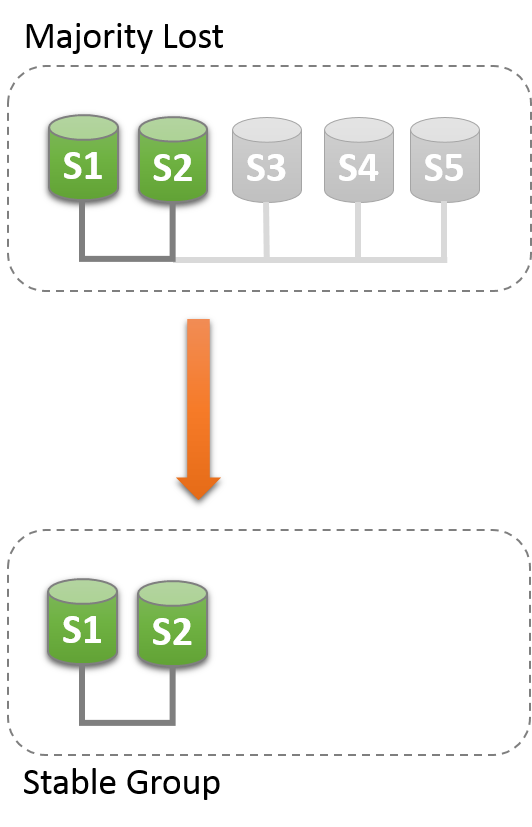
Suppose that you are back in the situation where s1 and s2 are the only servers left in the group. Servers s3, s4 and s5 have left the group unexpectedly. To make servers s1 and s2 continue, you want to force a membership configuration that contains only s1 and s2.
This procedure uses
group_replication_force_members
and should be considered a last resort remedy. It
must be used with extreme care and only
for overriding loss of quorum. If misused, it could create an
artificial split-brain scenario or block the entire system
altogether.
Recall that the system is blocked and the current configuration is the following (as perceived by the local failure detector on s1):
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
The first thing to do is to check what is the peer address (group communication identifier) for s1 and s2. Log in to s1 and s2 and get that information as follows.
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10000 |
+-----------------------------------+
Then log in to s2 and do the same thing:
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10001 |
+-----------------------------------+
Once you know the group communication addresses of s1
(127.0.0.1:10000) and s2
(127.0.0.1:10001), you can use that on one of
the two servers to inject a new membership configuration, thus
overriding the existing one that has lost quorum. To do that on
s1:
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";
This unblocks the group by forcing a different configuration.
Check replication_group_members on
both s1 and s2 to verify the group membership after this change.
First on s1.
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
And then on s2.
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
When forcing a new membership configuration, make sure that any servers are going to be forced out of the group are indeed stopped. In the scenario depicted above, if s3, s4 and s5 are not really unreachable but instead are online, they may have formed their own functional partition (they are 3 out of 5, hence they have the majority). In that case, forcing a group membership list with s1 and s2 could create an artificial split-brain situation. Therefore it is important before forcing a new membership configuration to ensure that the servers to be excluded are indeed shutdown and if they are not, shut them down before proceeding.
After you have used the
group_replication_force_members
system variable to successfully force a new group membership and
unblock the group, ensure that you clear the system variable.
group_replication_force_members
must be empty in order to issue a START
GROUP_REPLICATION statement.
From MySQL 8.0.14, Group Replication group members can use IPv6 addresses as an alternative to IPv4 addresses for communications within the group. To use IPv6 addresses, the operating system on the server host and the MySQL Server instance must both be configured to support IPv6. For instructions to set up IPv6 support for a server instance, see Section 5.1.12, “IPv6 Support”.
IPv6 addresses, or host names that resolve to them, can be
specified as the network address that the member provides in the
group_replication_local_address
option for connections from other members. When specified with a
port number, an IPv6 address must be specified in square brackets,
for example:
group_replication_local_address= "[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061"
The network address or host name specified in
group_replication_local_address
is used by Group Replication as the unique identifier for a group
member within the replication group. If a host name specified as
the Group Replication local address for a server instance resolves
to both an IPv4 and an IPv6 address, the IPv4 address is always
used for Group Replication connections. The address or host name
specified as the Group Replication local address is not the same
as the MySQL server SQL protocol host and port, and is not
specified in the bind_address
system variable for the server instance. For the purpose of IP
address whitelisting for Group Replication (see
Section 18.5.1, “IP Address Whitelisting”), the
address that you specify for each group member in
group_replication_local_address
must be added to the list for the
group_replication_ip_whitelist
option on the other servers in the replication group.
A replication group can contain a combination of members that
present an IPv6 address as their Group Replication local address,
and members that present an IPv4 address. When a server joins such
a mixed group, it must make the initial contact with the seed
member using the protocol that the seed member advertises in the
group_replication_group_seeds
option, whether that is IPv4 or IPv6. If any of the seed members
for the group are listed in the
group_replication_group_seeds
option with an IPv6 address when a joining member has an IPv4
Group Replication local address, or the reverse, you must also set
up and whitelist an alternative address for the joining member for
the required protocol (or a host name that resolves to an address
for that protocol). If a joining member does not have a
whitelisted address for the appropriate protocol, its connection
attempt is refused. The alternative address or host name only
needs to be added to the
group_replication_ip_whitelist
option on the other servers in the replication group, not to the
group_replication_local_address
value for the joining member (which can only contain a single
address).
For example, server A is a seed member for a group, and has the
following configuration settings for Group Replication, so that it
is advertising an IPv6 address in the
group_replication_group_seeds
option:
group_replication_bootstrap_group=on group_replication_local_address= "[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061" group_replication_group_seeds= "[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061"
Server B is a joining member for the group, and has the following configuration settings for Group Replication, so that it has an IPv4 Group Replication local address:
group_replication_bootstrap_group=off group_replication_local_address= "203.0.113.21:33061" group_replication_group_seeds= "[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061"
Server B also has an alternative IPv6 address
2001:db8:8b0:40:3d9c:cc43:e006:19e8. For Server
B to join the group successfully, both its IPv4 Group Replication
local address, and its alternative IPv6 address, must be listed in
Server A's whitelist, as in the following example:
group replication_ip_whitelist= "203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348, 2001:db8:8b0:40:3d9c:cc43:e006:19e8"
As a best practice for Group Replication IP whitelisting, Server B (and all other group members) should have the same whitelist as Server A, unless security requirements demand otherwise.
If any or all members of a replication group are using an older
MySQL Server version that does not support the use of IPv6
addresses for Group Replication, a member cannot participate in
the group using an IPv6 address (or a host name that resolves to
one) as its Group Replication local address. This applies both in
the case where at least one existing member uses an IPv6 address
and a new member that does not support this attempts to join, and
in the case where a new member attempts to join using an IPv6
address but the group includes at least one member that does not
support this. In each situation, the new member cannot join. To
make a joining member present an IPv4 address for group
communications, you can either change the value of
group_replication_local_address
to an IPv4 address, or configure your DNS to resolve the joining
member's existing host name to an IPv4 address. After you have
upgraded every group member to a MySQL Server version that
supports IPv6 for Group Replication, you can change the
group_replication_local_address
value for each member to an IPv6 address, or configure your DNS to
present an IPv6 address. Changing the value of
group_replication_local_address
takes effect only when you stop and restart Group Replication.
This section explains how to back up and subsequently restore a Group Replication member using MySQL Enterprise Backup; the same technique can be used to quickly add a new member to a group. Generally, backing up a Group Replication member is no different to backing up a stand-alone MySQL instance. The recommended process is to use MySQL Enterprise Backup image backups and a subsequent restore, for more information see Backup Operations.
The required steps can be summarized as:
Use MySQL Enterprise Backup to create a backup of the source server instance with simple timestamps.
Copy the backup to the destination server instance.
Use MySQL Enterprise Backup to restore the backup to the destination server instance.
The following procedure demonstrates this process. Consider the following group:
mysql> SELECT * member_host, member_port, member_state FROM performance_schema.replication_group_members;
+-------------+-------------+--------------+
| member_host | member_port | member_state |
+-------------+-------------+--------------+
| node1 | 3306 | ONLINE |
| node2 | 3306 | ONLINE |
| node3 | 3306 | ONLINE |
+-------------+-------------+--------------+
In this example the group is operating in single-primary mode and
the primary group member is node1. This means
that node2 and node3 are
secondaries, operating in read-only mode
(super_read_only=ON). Using
MySQL Enterprise Backup, a recent backup has been taken of node2
by issuing:
mysqlbackup --defaults-file=/etc/my.cnf --backup-image=/backups/my.mbi_`date +%d%m_%H%M` \
--backup-dir=/backups/backup_`date +%d%m_%H%M` --user=root -pmYsecr3t \
--host=127.0.0.1 --no-history-logging backup-to-image
The --no-history-logging option is used because
node2 is a secondary, and because it is
read-only MySQL Enterprise Backup cannot write status and metadata tables to the
instance.
Assume that the primary member, node1,
encounters irreconcilable corruption. After a period of time the
server instance is rebuilt but all the data on the member was
lost. The most recent backup of member node2
can be used to rebuild node1. This requires
copying the backup files from node2 to
node1 and then using MySQL Enterprise Backup to restore the
backup to node1. The exact way you copy the
backup files depends on the operating system and tools available
to you. In this example we assume Linux servers and use SCP to
copy the files between servers:
node2/backups# scp my.mbi_2206_1429 node1:/backups
Connect to the destination server, in this case
node1, and restore the backup using MySQL Enterprise Backup by
issuing:
mysqlbackup --defaults-file=/etc/my.cnf \
--backup-image=/backups/my.mbi_2206_1429 \
--backup-dir=/tmp/restore_`date +%d%m_%H%M` copy-back-and-apply-logThe backup is restored to the destination server.
If your group is using multi-primary mode, extra care must be taken to prevent writes to the database during the MySQL Enterprise Backup restore stage and the Group Replication recovery phase. Depending on how the group is accessed by clients, there is a possibility of DML being executed on the newly joined instance the moment it is accessible on the network, even prior to applying the binary log before rejoining the group. To avoid this, configure the member's option file with:
group_replication_start_on_boot=OFF super_read_only=ON event_scheduler=OFF
This ensures that Group Replication is not started on boot, that the member defaults to read-only and that the event_scheduler is turned off while the member catches up with the group during the recovery phase. Adequate error handling must be configured on the clients to recognise that they are, temporarily, prevented from performing DML during this period.
Start the server instance and connect an SQL client. The restored backup has old binary log files and related metadata that are specific to the instance that was backed up. To reset all of that issue:
mysql> RESET MASTER;
The restored backup has the relay log files associated with the
source instance, in this case node2. Therefore
reset the logs, metadata, and configuration for all replication
channels by issuing:
mysql> RESET SLAVE ALL;
For the restored instance to be able to be able to recover
automatically using Group Replication's built-in distributed
recovery (see
Section 18.10.5, “Distributed Recovery”),
configure the gtid_executed
variable. The MySQL Enterprise Backup backup from node2 includes
the backup_gtid_executed.sql file, usually at
the path
datadir/meta/node1. Disable binary logging and then use this
file to configure the
gtid_executed variable by
issuing:
mysql>SET SQL_LOG_BIN=OFF;mysql>SOURCEmysql>datadir/meta/backup_gtid_executed.sqlSET SQL_LOG_BIN=ON;
Configure the Section 18.2.1.3, “User Credentials” and start Group Replication, for example:
mysql>CHANGE MASTER TO MASTER_USER='mysql>rpl_user', MASTER_PASSWORD='password' / FOR CHANNEL 'group_replication_recovery';START GROUP_REPLICATION;
The instance attempts to join the group, executing the restored
binary logs from the correct location. Once the instance gains
synchrony with the group, it joins as a secondary, with
super_read_only=ON. Reset the
temporary configuration changes made during the restore. Turn the
event scheduler back on in the running process:
mysql> SET global event_scheduler=ON;
Edit the following system variables in the instance's option file:
group_replication_start_on_boot=ON super_read_only=ON event_scheduler=ON
This section explains how to secure a group, securing the connections between members of a group, or by establishing a security perimeter using address whitelisting.
The Group Replication plugin has a configuration option to
determine from which hosts an incoming Group Communication System
connection can be accepted. This option is called
group_replication_ip_whitelist.
If you set this option on a server s1, then when server s2 is
establishing a connection to s1 for the purpose of engaging group
communication, s1 first checks the whitelist before accepting the
connection from s2. If s2 is in the whitelist, then s1 accepts the
connection, otherwise s1 rejects the connection attempt by s2.
If you do not specify a whitelist explicitly, the group
communication engine (XCom) automatically scans active interfaces
on the host, and identifies those with addresses on private
subnetworks. These addresses and the localhost
IP address for IPv4 and (from MySQL 8.0.14) IPv6 are used to
create an automatic Group Replication whitelist. The automatic
whitelist therefore includes any IP addresses found for the host
in the following ranges:
IPv4 (as defined in RFC 1918) 10/8 prefix (10.0.0.0 - 10.255.255.255) - Class A 172.16/12 prefix (172.16.0.0 - 172.31.255.255) - Class B 192.168/16 prefix (192.168.0.0 - 192.168.255.255) - Class C IPv6 (as defined in RFC 4193 and RFC 5156) fc00:/7 prefix - unique-local addresses fe80::/10 prefix - link-local unicast addresses 127.0.0.1 - localhost for IPv4 ::1 - localhost for IPv6
An entry is added to the error log stating the addresses that have been whitelisted automatically for the host.
The automatic whitelist of private addresses cannot be used for
connections from servers outside the private network, so a server,
even if it has interfaces on public IPs, does not by default allow
Group Replication connections from external hosts. For Group
Replication connections between server instances that are on
different machines, you must provide public IP addresses and
specify these as an explicit whitelist. If you specify any entries
for the whitelist, the private and localhost
addresses are not added automatically, so if you use any of these,
you must specify them explicitly.
To specify a whitelist manually, use the
group_replication_ip_whitelist
option. You cannot change the whitelist on a server while it is an
active member of a replication group. If the member is active, you
must issue a STOP GROUP_REPLICATION
statement before changing the whitelist, and a
START GROUP_REPLICATION statement
afterwards.
In the whitelist, you can specify any combination of the following:
IPv4 addresses (for example,
198.51.100.44)IPv4 addresses with CIDR notation (for example,
192.0.2.21/24)IPv6 addresses, from MySQL 8.0.14 (for example,
2001:db8:85a3:8d3:1319:8a2e:370:7348)IPv6 addresses with CIDR notation, from MySQL 8.0.14 (for example,
2001:db8:85a3:8d3::/64)Host names (for example,
example.org)Host names with CIDR notation (for example,
www.example.com/24)
Before MySQL 8.0.14, host names could only resolve to IPv4 addresses. From MySQL 8.0.14, host names can resolve to IPv4 addresses, IPv6 addresses, or both. If a host name resolves to both an IPv4 and an IPv6 address, the IPv4 address is always used for Group Replication connections. You can use CIDR notation in combination with host names or IP addresses to whitelist a block of IP addresses with a particular network prefix, but do ensure that all the IP addresses in the specified subnet are under your control.
You must stop and restart Group Replication on a member in order to change its whitelist. A comma must separate each entry in the whitelist. For example:
mysql> STOP GROUP_REPLICATION; mysql> SET GLOBAL group_replication_ip_whitelist="192.0.2.21/24,198.51.100.44,203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348,example.org,www.example.com/24"; mysql> START GROUP_REPLICATION;
The whitelist must contain the IP address or host name that is
specified in each member's
group_replication_local_address
system variable. This address is not the same as the MySQL server
SQL protocol host and port, and is not specified in the
bind_address system variable for
the server instance. If a host name used as the Group Replication
local address for a server instance resolves to both an IPv4 and
an IPv6 address, the IPv4 address is preferred for Group
Replication connections.
To join a replication group, a server needs to be whitelisted on
the seed member to which it makes the request to join the group.
Typically, this would be the bootstrap member for the replication
group, but it can be any of the servers listed by the
group_replication_group_seeds
option in the configuration for the server joining the group. If
any of the seed members for the group are listed in the
group_replication_group_seeds
option with an IPv6 address when a joining member has an IPv4
group_replication_local_address,
or the reverse, you must also set up and whitelist an alternative
address for the joining member for the protocol offered by the
seed member (or a host name that resolves to an address for that
protocol). This is because when a server joins a replication
group, it must make the initial contact with the seed member using
the protocol that the seed member advertises in the
group_replication_group_seeds
option, whether that is IPv4 or IPv6. If a joining member does not
have a whitelisted address for the appropriate protocol, its
connection attempt is refused. For more information on managing
mixed IPv4 and IPv6 replication groups, see
Section 18.4.5, “Support For IPv6 And For Mixed IPv6 And IPv4 Groups”.
When a replication group is reconfigured (for example, when a new primary is elected or a member joins or leaves), the group members re-establish connections between themselves. If a group member is only whitelisted by servers that are no longer part of the replication group after the reconfiguration, it is unable to reconnect to the remaining servers in the replication group that do not whitelist it. To avoid this scenario entirely, specify the same whitelist for all servers that are members of the replication group.
It is possible to configure different whitelists on different group members according to your security requirements, for example, in order to keep different subnets separate. If you need to configure different whitelists to meet your security requirements, ensure that there is sufficient overlap between the whitelists in the replication group to maximize the possibility of servers being able to reconnect in the absence of their original seed member.
For host names, name resolution takes place only when a connection request is made by another server. A host name that cannot be resolved is not considered for whitelist validation, and a warning message is written to the error log. Forward-confirmed reverse DNS (FCrDNS) verification is carried out for resolved host names.
Host names are inherently less secure than IP addresses in a whitelist. FCrDNS verification provides a good level of protection, but can be compromised by certain types of attack. Specify host names in your whitelist only when strictly necessary, and ensure that all components used for name resolution, such as DNS servers, are maintained under your control. You can also implement name resolution locally using the hosts file, to avoid the use of external components.
MySQL Group Replication supports OpenSSL and wolfSSL builds of MySQL Server.
Group communication connections as well as recovery connections, are secured using SSL. The following sections explain how to configure connections.
Recovery is performed through a regular asynchronous replication connection. Once the donor is selected, the server joining the group establishes an asynchronous replication connection. This is all automatic.
However, a user that requires an SSL connection must have been created before the server joining the group connects to the donor. Typically, this is set up at the time one is provisioning a server to join the group.
donor> SET SQL_LOG_BIN=0; donor> CREATE USER 'rec_ssl_user'@'%' REQUIRE SSL; donor> GRANT replication slave ON *.* TO 'rec_ssl_user'@'%'; donor> SET SQL_LOG_BIN=1;
Assuming that all servers already in the group have a replication user set up to use SSL, you configure the server joining the group to use those credentials when connecting to the donor. That is done according to the values of the SSL options provided for the Group Replication plugin.
new_member> SET GLOBAL group_replication_recovery_use_ssl=1; new_member> SET GLOBAL group_replication_recovery_ssl_ca= '.../cacert.pem'; new_member> SET GLOBAL group_replication_recovery_ssl_cert= '.../client-cert.pem'; new_member> SET GLOBAL group_replication_recovery_ssl_key= '.../client-key.pem';
And by configuring the recovery channel to use the credentials of the user that requires an SSL connection.
new_member> CHANGE MASTER TO MASTER_USER="rec_ssl_user" FOR CHANNEL "group_replication_recovery"; new_member> START GROUP_REPLICATION;
Secure sockets can be used to establish communication between members in a group. The configuration for this depends on the server's SSL configuration. As such, if the server has SSL configured, the Group Replication plugin also has SSL configured. For more information on the options for configuring the server SSL, see Section 6.4.2, “Command Options for Encrypted Connections”. The options which configure Group Replication are shown in the following table.
Table 18.3 SSL Options
Server Configuration |
Plugin Configuration Description |
|---|---|
ssl_key |
Path of key file. To be used as client and server certificate. |
ssl_cert |
Path of certificate file. To be used as client and server certificate. |
ssl_ca |
Path of file with SSL Certificate Authorities that are trusted. |
ssl_capath |
Path of directory containing certificates for SSL Certificate Authorities that are trusted. |
ssl_crl |
Path of file containing the certificate revocation lists. |
ssl_crlpath |
Path of directory containing revoked certificate lists. |
ssl_cipher |
Permitted ciphers to use while encrypting data over the connection. |
tls_version |
Secure communication will use this version and its protocols. |
These options are MySQL Server configuration options which Group Replication relies on for its configuration. In addition there is the following Group Replication specific option to configure SSL on the plugin itself.
group_replication_ssl_mode- specifies the security state of the connection between Group Replication members.
Table 18.4 group_replication_ssl_mode configuration values
Value |
Description |
|---|---|
DISABLED |
Establish an unencrypted connection (default). |
REQUIRED |
Establish a secure connection if the server supports secure connections. |
VERIFY_CA |
Like REQUIRED, but additionally verify the server TLS certificate against the configured Certificate Authority (CA) certificates. |
VERIFY_IDENTITY |
Like VERIFY_CA, but additionally verify that the server certificate matches the host to which the connection is attempted. |
The following example shows an example my.cnf file section used to configure SSL on a server and how activate it for Group Replication.
[mysqld] ssl_ca = "cacert.pem" ssl_capath = "/.../ca_directory" ssl_cert = "server-cert.pem" ssl_cipher = "DHE-RSA-AEs256-SHA" ssl_crl = "crl-server-revoked.crl" ssl_crlpath = "/.../crl_directory" ssl_key = "server-key.pem" group_replication_ssl_mode= REQUIRED
The only plugin specific configuration option that is listed is
group_replication_ssl_mode.
This option activates the SSL communication between members of
the group, by configuring the SSL framework with the
ssl_* parameters that are provided to the
server.
This section explains how to upgrade a group replication setup. The basic process of upgrading members of a group is the same as upgrading stand-alone instances, see Section 2.11, “Upgrading MySQL” for the actual process of doing upgrade and types available. Choosing between an in-place or logical upgrade depends on the amount of data stored in the group. Usually an in-place upgrade is faster, and therefore is recommended. Due to the distributed nature of Group Replication, there are considerations such as what order to upgrade members of a group, which are described in this section. You should also consult Section 17.4.3, “Upgrading a Replication Setup”.
If your group can be taken fully offline see Section 18.6.1, “Group Replication Offline Upgrade”. If your group needs to remain online, as is common with production deployments, see Section 18.6.2, “Group Replication Online Upgrade” for the different approaches available for upgrading a group with minimal downtime.
To perform an offline upgrade of a Group Replication group, you remove each member from the group, perform an upgrade of the member and then restart the group as usual. In a multi-primary group you can shutdown the members in any order. In a single-primary group, shutdown each secondary first and then finally the primary. See Section 18.6.2.3, “Upgrading a Group Replication Member” for how to remove members from a group and shutdown MySQL.
Once the group is offline, upgrade all of the members. See Section 2.11, “Upgrading MySQL” for how to perform an upgrade. When all members have been upgraded, restart the members.
When you have a group running which you want to upgrade but you need to keep the group online to serve your application, you need to consider your approach to the upgrade. This section describes the different elements involved in an online upgrade, and various methods of how to upgrade your group.
When upgrading an online group you should consider the following points:
Regardless of the way which you upgrade your group, it is important to disable any writes to group members until they are ready to rejoin the group.
When a member is stopped, the
super_read_onlyvariable is set to on automatically, but this change is not persisted.When MySQL 5.7.22 or MySQL 8.0.11 tries to join a group running MySQL 5.7.21 or lower it fails to join the group because MySQL 5.7.21 does not send its value of
lower_case_table_names.
When you upgrade an online group, you might need to run different versions of MySQL on members in the group at the same time. Depending on the changes made between the versions of MySQL, you could encounter incompatibilities. For example, if a feature has been deprecated between major versions then combining the versions in a group might cause members which rely on the deprecated feature to fail. This section describes the best practices for combining members running different versions of MySQL in the same group.
Group Replication is versioned according to the server version which the plugin was bundled with, for example if a member is running MySQL 5.7.19 then that is the version of the plugin. This version number is critical when upgrading a group, and specifically at the time of joining members to a group. See Section 2.1.1, “Which MySQL Version and Distribution to Install”.
To check the version of MySQL on a group member issue:
SELECT MEMBER_HOST,MEMBER_PORT,MEMBER_VERSION FROM performance_schema.replication_group_members;
+-------------+-------------+----------------+
| member_host | member_port | member_version |
+-------------+-------------+----------------+
| example.com | 3306 | 8.0.13 |
+-------------+-------------+----------------+
The rules for combining members in a group with different major versions are:
You cannot join a member to a group when it is running an older major version than the major version which the existing group members are running. For example if you have a group with members running MySQL version 8.0, you cannot add a member which is running an older version such as MySQL version 5.7.
You can join a member to group if it is running a newer major version than the major version which the existing group members are running. For example if you have a group with members running MySQL 5.7, you can add a member running MySQL version 8.0, but it remains in read-only mode. Writing to this member while there are read-write members running an older MySQL version is dangerous and must be avoided.
The rules for combining members in a group with different minor versions are:
You can add members running a newer or older minor version to a group, they are able to do writes. In a single-primary group, added members default to being read-only.
This section explains the steps required for upgrading a member of a group. This procedure is part of the methods described at Section 18.6.2.4, “Group Replication Online Upgrade Methods”. The process of upgrading a member of a group is common to all methods and is explained first. The way which you join upgraded members can depend on which method you are following, and other factors such as whether the group is operating in single-primary or multi-primary mode. How you upgrade the server instance, using either the in-place or provision approach, does not impact on the methods described here.
The process of upgrading a member consists of removing it from the group, following your chosen method of upgrading the member, and then rejoining the upgraded member to a group. The recommended order of upgrading members in a single-primary group is to upgrade all secondaries, and then upgrade the primary last. If the primary is upgraded before a secondary, a new primary using the older MySQL version is chosen, but there is no need for this step.
To upgrade a member of a group:
Connect a client to the group member and issue
STOP GROUP_REPLICATION. Before proceeding, ensure that the member's status isOFFLINEby monitoring thereplication_group_memberstable.Disable Group Replication from starting up automatically so that you can safely connect to the member after upgrading and configure it without it rejoining the group by setting
group_replication_start_on_boot=0.ImportantIf an upgraded member has
group_replication_start_on_boot=1then it could rejoin the group before you can perform the MySQL upgrade procedure and could result in issues. For example, if the upgrade fails and the server restarts again, then a possibly broken server could try to join the group.Stop the member, for example using mysqladmin shutdown or the
SHUTDOWNstatement. Any other members in the group continue running.Upgrade the member, using the in-place or provisioning approach. See Section 2.11, “Upgrading MySQL” for details. When restarting the upgraded member, because
group_replication_start_on_bootis set to 0, Group Replication does not start on the instance, and therefore it does not rejoin the group.Once the MySQL upgrade procedure has been performed on the member,
group_replication_start_on_bootmust be set to 1 to ensure Group Replication starts correctly after restart. Restart the member.Connect to the upgraded member and issue
START GROUP_REPLICATION. This rejoins the member to the group. The Group Replication metadata is in place on the upgraded server, therefore there is usually no need to reconfigure Group Replication. The server has to catch up with any transactions processed by the group while the server was offline. Once it has caught up with the group, it becomes an online member of the group.Notethe longer it takes to upgrade a server, the more time that member is offline and therefore the more time it takes for the server to catch up when added back to the group.
When an upgraded member joins a group which has any member
running an earlier version, the upgraded member joins with
super_read_only=on, regardless
of whether it was a primary or secondary. This ensures that no
writes are made to upgraded members until all members are
running the newer version. In a multi-primary group, once you
are sure the upgrade has been successful and the group is ready
to process transactions, it is necessary to manually configure
members which should become writeable primaries. Connect to each
member and issue:
SET GLOBAL read_only=off;Choose one of the following methods of upgrading a Group Replication group:
This method is supported provided that servers running a newer
major version are not generating workload to the group while
there are still servers with an older version in it. In other
words servers with a newer major version can join the group
only as secondaries. In this method there is only ever one
group, and each server instance is removed from the group,
upgraded and then rejoined to the group. Members running the
newer version join the group with
super_read_only=ON. This
method is well suited to single-primary groups. When the group
is operating in single-primary mode, the primary member should
be the last member to be upgraded. If the primary is upgraded
while there are still members running the old version, a new
primary is chosen from the members running the old version,
but there is no need for this.
For groups operating in single-primary mode, once all
secondaries are running the newer version, when the primary
member leaves the group to be upgraded, a new primary is
automatically chosen from the members running the new version.
For groups operating in multi-primary mode, once
all members are upgraded, you
must manually set
super_read_only=OFF on each
member that should function as a primary. For groups operating
in multi-primary mode, during this process the number of
primaries is decreased, causing a reduction in write
availability. This does not impact groups operating in
single-primary mode.
In this method you remove members from the group, upgrade them and then create a second group using the upgraded members. For groups operating in multi-primary mode, during this process the number of primaries is decreased, causing a reduction in write availability. This does not impact groups operating in single-primary mode.
Because the group running the older version is online while you are upgrading the members, you need the group running the newer version to catch up with any transactions executed while the members were being upgraded. Therefore one of the servers in the new group is configured as a replication slave of a primary from the older group. This ensures that the new group catches up with the older group. Because this method relies on an asynchronous replication channel which is used to replicate data from one group to another, it is supported under the same assumptions and requirements of master-slave replication, see Chapter 17, Replication. For groups operating in single-primary mode, the asynchronous replication connection to the old group must send data to the primary in the new group, for a multi-primary group the asynchronous replication channel can connect to any primary.
The process is to:
remove members from the original group running the older server version one by one, see Section 18.6.2.3, “Upgrading a Group Replication Member”
upgrade the server version running on the member, see Section 2.11, “Upgrading MySQL”. You can either follow an in-place or provision approach to upgrading.
create a new group with the upgraded members, see Chapter 18, Group Replication. In this case you need to configure a new group name on each member (because the old group is still running and using the old name), bootstrap an initial upgraded member, and then add the remaining upgraded members.
set up an asynchronous replication channel between the old group and the new group, see Section 17.1.3.4, “Setting Up Replication Using GTIDs”. Configure the older primary to function as the asynchronous replication master and the new group member as a GTID-based replication slave.
Before you can redirect your application to the new group, you
must ensure that the new group has a suitable number of
members, for example so that the group can handle the failure
of a member. Issue SELECT * FROM
performance_schema.replication_group_members and
compare the initial group size and the new group size. Wait
until all data from the old group is propagated to the new
group and then drop the asynchronous replication connection
and upgrade any missing members.
In this method you create a second group consisting of members which are running the newer version, and the data missing from the older group is replicated to the newer group. This assumes that you have enough servers to run both groups simultaneously. Due to the fact that during this process the number of primaries is not decreased, for groups operating in multi-primary mode there is no reduction in write availability. This makes rolling duplication upgrade well suited to groups operating in multi-primary mode. This does not impact groups operating in single-primary mode.
Because the group running the older version is online while you are provisioning the members in the new group, you need the group running the newer version to catch up with any transactions executed while the members were being provisioned. Therefore one of the servers in the new group is configured as a replication slave of a primary from the older group. This ensures that the new group catches up with the older group. Because this method relies on an asynchronous replication channel which is used to replicate data from one group to another, it is supported under the same assumptions and requirements of master-slave replication, see Chapter 17, Replication. For groups operating in single-primary mode, the asynchronous replication connection to the old group must send data to the primary in the new group, for a multi-primary group the asynchronous replication channel can connect to any primary.
The process is to:
deploy a suitable number of members so that the group running the newer version can handle failure of a member
take a backup of the existing data from a member of the group
use the backup from the older member to provision the members of the new group, see Section 18.6.2.5, “Group Replication Upgrade with mysqlbackup” for one method.
NoteYou must restore the backup to the same version of MySQL which the backup was taken from, and then perform an in-place upgrade. For instructions, see Section 2.11, “Upgrading MySQL”.
create a new group with the upgraded members, see Chapter 18, Group Replication. In this case you need to configure a new group name on each member (because the old group is still running and using the old name), bootstrap an initial upgraded member, and then add the remaining upgraded members.
set up an asynchronous replication channel between the old group and the new group, see Section 17.1.3.4, “Setting Up Replication Using GTIDs”. Configure the older primary to function as the asynchronous replication master and the new group member as a GTID-based replication slave.
Once the ongoing data missing from the newer group is small enough to be quickly transferred, you must redirect write operations to the new group. Wait until all data from the old group is propagated to the new group and then drop the asynchronous replication connection.
As part of a provisioning approach you can use MySQL Enterprise Backup to copy and restore the data from a group member to new members. However you cannot use this technique to directly restore a backup taken from a member running an older version of MySQL to a member running a newer version of MySQL. The solution is to restore the backup to a new server instance which is running the same version of MySQL as the member which the backup was taken from, and then upgrade the instance. This process consists of:
Take a backup from a member of the older group using mysqlbackup. See Section 18.4.6, “Using MySQL Enterprise Backup with Group Replication”.
Deploy a new server instance, which must be running the same version of MySQL as the older member where the backup was taken.
Restore the backup from the older member to the new instance using mysqlbackup.
Upgrade MySQL on the new instance, see Section 2.11, “Upgrading MySQL”.
Repeat this process to create a suitable number of new instances, for example to be able to handle a failover. Then join the instances to a group based on the Section 18.6.2.4, “Group Replication Online Upgrade Methods”.`
These are the system variables that are specific to the Group Replication plugin. Every configuration option is prefixed with "group_replication".
Although most variables are described as dynamic and can be changed while the server is running, most changes only take effect upon restarting the Group Replication plugin. Variables which can be changed without requiring a restart of the plugin are specifically noted as such in this section.
Variables that specify IP addresses or host names for group members are not validated until a
START GROUP_REPLICATIONstatement is issued. The Group Communication System (GCS) is not available to validate the values until that point.A number of variables for Group Replication are not completely validated during server startup if they are passed as command line arguments to the server. These variables include
group_replication_group_name,group_replication_single_primary_mode,group_replication_force_members, the SSL variables, and the flow control variables. They are only fully validated after the server has started.
group_replication_allow_local_disjoint_gtids_joinProperty Value Command-Line Format --group-replication-allow-local-disjoint-gtids-join=valueDeprecated Yes (removed in 8.0.4) System Variable group_replication_allow_local_disjoint_gtids_joinScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFRemoved in version 8.0.4. Allow the current server to join the group even if it has transactions not present in the group.
WarningUse caution when enabling this option as incorrect usage could lead to inconsistencies in the group.
group_replication_allow_local_lower_version_joinProperty Value Command-Line Format --group-replication-allow-local-lower-version-join=valueSystem Variable group_replication_allow_local_lower_version_joinScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFAllow the current server to join the group even if it has a lower plugin version than the group.
group_replication_auto_increment_incrementProperty Value Command-Line Format --group-replication-auto-increment-increment=valueSystem Variable group_replication_auto_increment_incrementScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 7Minimum Value 1Maximum Value 65535Determines the interval between successive column values for transactions that execute on this server instance.
group_replication_bootstrap_groupProperty Value Command-Line Format --group-replication-bootstrap-group=valueSystem Variable group_replication_bootstrap_groupScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFConfigure this server to bootstrap the group. This option must only be set on one server and only when starting the group for the first time or restarting the entire group. After the group has been bootstrapped, set this option to
OFF. It should be set toOFFboth dynamically and in the configuration files. Starting two servers or restarting one server with this option set while the group is running may lead to an artificial split brain situation, where two independent groups with the same name are bootstrapped.group_replication_communication_debug_optionsProperty Value Command-Line Format --group-replication-communication-debug-options=valueIntroduced 8.0.3 System Variable group_replication_communication_debug_optionsScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value GCS_DEBUG_NONEValid Values GCS_DEBUG_NONEGCS_DEBUG_BASICGCS_DEBUG_TRACEXCOM_DEBUG_BASICXCOM_DEBUG_TRACEGCS_DEBUG_ALLConfigures the level of debugging messages to provide for the different Group Replication components, such as Group Communication System (GCS) and the group communication engine (XCom, a Paxos variant). The debug information is stored in the
GCS_DEBUG_TRACEfile in the data directory.The set of available options, specified as strings, can be combined. The following options are available:
GCS_DEBUG_NONEdisables all debugging levels for both GCS and XCOMGCS_DEBUG_BASICenables basic debugging information in GCSGCS_DEBUG_TRACEenables trace information in GCSXCOM_DEBUG_BASICenables basic debugging information in XCOMXCOM_DEBUG_TRACEenables trace information in XCOMGCS_DEBUG_ALLenables all debugging levels for both GCS and XCOM
Setting the debug level to
GCS_DEBUG_NONEonly has an effect when provided without any other option. Setting the debug level toGCS_DEBUG_ALLoverrides all other options.group_replication_components_stop_timeoutProperty Value Command-Line Format --group-replication-components-stop-timeout=valueSystem Variable group_replication_components_stop_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 31536000Minimum Value 2Maximum Value 31536000Timeout, in seconds, that Group Replication waits for each of the components when shutting down.
group_replication_compression_thresholdProperty Value Command-Line Format --group-replication-compression-threshold=valueSystem Variable group_replication_compression_thresholdScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1000000Minimum Value 0Maximum Value 4294967295The value in bytes above which (LZ4) compression is enforced. When set to zero, deactivates compression.
-
Property Value Command-Line Format --group-replication-consistency=valueIntroduced 8.0.14 System Variable group_replication_consistencyScope Global, Session Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value EVENTUALValid Values EVENTUALBEFORE_ON_PRIMARY_FAILOVERBEFOREAFTERBEFORE_AND_AFTERControls the transaction consistency guarantee which a group provides. You can configure the consistency globally or per transaction. Also configures the fencing mechanism used by newly elected primaries in single primary groups. The effect of the variable must be considered for both read only (RO) and read write (RW) transactions. The following list shows the possible values of this variable, in order of increasing transaction consistency guarantee:
EVENTUALBoth RO and RW transactions do not wait for preceding transactions to be applied before executing. This was the behavior of Group Replication before this variable was added. A RW transaction does not wait for other members to apply a transaction. This means that a transaction could be externalized on one member before the others. This also means that in the event of a primary failover, the new primary can accept new RO and RW transactions before the previous primary transactions are all applied. RO transactions could result in outdated values, RW transactions could result in a rollback due to conflicts.
BEFORE_ON_PRIMARY_FAILOVERNew RO or RW transactions with a newly elected primary that is applying backlog from the old primary are held (not applied) until any backlog has been applied. This ensures that when a primary failover happens, intentionally or not, clients always see the latest value on the primary. This guarantees consistency, but means that clients must be able to handle the delay in the event that a backlog is being applied. Usually this delay should be minimal, but does depend on the size of the backlog.
BEFOREA RW transaction waits for all preceding transactions to complete before being applied. A RO transaction waits for all preceding transactions to complete before being executed. This ensures that this transaction reads the latest value by only affecting the latency of the transaction. This reduces the overhead of synchronization on every RW transaction, by ensuring synchronization is used only on RO transactions.
AFTERA RW transaction waits until its changes have been applied to all of the other members. This value has no effect on RO transactions. This mode ensures that when a transaction is committed on the local member, any subsequent transaction reads the written value or a more recent value on any group member. Use this mode with a group that is used for predominantly RO operations to ensure that applied RW transactions are applied everywhere once they commit. This could be used by your application to ensure that subsequent reads fetch the latest data which includes the latest writes. This reduces the overhead of synchronization on every RO transaction, by ensuring synchronization is used only on RW transactions.
BEFORE_AND_AFTERA RW transaction waits for 1) all preceding transactions to complete before being applied and 2) until its changes have been applied on other members. A RO transaction waits for all preceding transactions to complete before execution takes place.
group_replication_enforce_update_everywhere_checksProperty Value Command-Line Format --group-replication-enforce-update-everywhere-checks=valueSystem Variable group_replication_enforce_update_everywhere_checksScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFEnable or disable strict consistency checks for multi-primary update everywhere.
group_replication_exit_state_actionProperty Value Command-Line Format --group-replication-exit-state-action=valueIntroduced 8.0.12 System Variable group_replication_exit_state_actionScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value (>= 8.0.12, <= 8.0.15) ABORT_SERVERDefault Value READ_ONLYValid Values ABORT_SERVERREAD_ONLYConfigures how Group Replication behaves when a server instance leaves the group unintentionally, for example after encountering an applier error, or in the case of a loss of majority, or when another member of the group expels it due to a suspicion timing out. The timeout period for a member to leave the group in the case of a loss of majority is set by the
group_replication_unreachable_majority_timeoutsystem variable, and the timeout period for suspicions is set by thegroup_replication_member_expel_timeoutsystem variable. Note that an expelled group member does not know that it was expelled until it reconnects to the group, so the specified action is only taken if the member manages to reconnect, or if the member raises a suspicion on itself and expels itself.When
group_replication_exit_state_actionis set toABORT_SERVER, if the member exits the group unintentionally, the instance shuts down MySQL. This setting was the default from MySQL 8.0.12, when the system variable was added, to MySQL 8.0.15 inclusive.When
group_replication_exit_state_actionis set toREAD_ONLY, if the member exits the group unintentionally, the instance switches MySQL to super read only mode (by setting the system variablesuper_read_onlytoON). This setting was the behavior for MySQL 8.0 releases before the system variable was introduced, and became the default again from MySQL 8.0.16. It is also the default from MySQL 5.7.24, when the system variable was added to that release, and the behavior for earlier MySQL 5.7 releases.ImportantThe specified exit action is not taken if a failure occurs during the local configuration check, or if there is a mismatch between the configuration of the joining member and the configuration of the group. In these situations, the
START GROUP_REPLICATIONcommand fails, thesuper_read_onlysystem variable is left with its original value, and the server does not shut down MySQL. To ensure that the server cannot accept updates when Group Replication did not start, we therefore recommend thatsuper_read_only=ONis set in the server's configuration file at startup, and then changed toOFFafter Group Replication has been started successfully.group_replication_flow_control_applier_thresholdProperty Value Command-Line Format --group-replication-flow-control-applier-threshold=valueSystem Variable group_replication_flow_control_applier_thresholdScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 25000Minimum Value 0Maximum Value 2147483647Specifies the number of waiting transactions in the applier queue that trigger flow control. This variable can be changed without resetting Group Replication.
group_replication_flow_control_certifier_thresholdProperty Value Command-Line Format --group-replication-flow-control-certifier-threshold=valueSystem Variable group_replication_flow_control_certifier_thresholdScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 25000Minimum Value 0Maximum Value 2147483647Specifies the number of waiting transactions in the certifier queue that trigger flow control. This variable can be changed without resetting Group Replication.
group_replication_flow_control_hold_percentProperty Value Command-Line Format --group-replication-flow-control-hold-percent=valueIntroduced 8.0.2 System Variable group_replication_flow_control_hold_percentScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 10Minimum Value 0Maximum Value 100Defines what percentage of the group quota remains unused to allow a cluster under flow control to catch up on backlog. A value of 0 implies that no part of the quota is reserved for catching up on the work backlog.
group_replication_flow_control_max_commit_quotaProperty Value Command-Line Format --group-replication-flow-control-max-commit-quota=valueIntroduced 8.0.2 System Variable group_replication_flow_control_max_commit_quotaScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 2147483647Defines the maximum flow control quota of the group, or the maximum available quota for any period while flow control is enabled. A value of 0 implies that there is no maximum quota set. Cannot be smaller than
group_replication_flow_control_min_quotaandgroup_replication_flow_control_min_recovery_quota.group_replication_flow_control_member_quota_percentProperty Value Command-Line Format --group-replication-flow-control-member-quota-percent=valueIntroduced 8.0.2 System Variable group_replication_flow_control_member_quota_percentScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 100Defines the percentage of the quota that a member should assume is available for itself when calculating the quotas. A value of 0 implies that the quota should be split equally between members that were writers in the last period.
group_replication_flow_control_min_quotaProperty Value Command-Line Format --group-replication-flow-control-min-quota=valueIntroduced 8.0.2 System Variable group_replication_flow_control_min_quotaScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 2147483647Controls the lowest flow control quota that can be assigned to a member, independently of the calculated minimum quota executed in the last period. A value of 0 implies that there is no minimum quota. Cannot be larger than
group_replication_flow_control_max_commit_quota.group_replication_flow_control_min_recovery_quotaProperty Value Command-Line Format --group-replication-flow-control-min-recovery-quota=valueIntroduced 8.0.2 System Variable group_replication_flow_control_min_recovery_quotaScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 2147483647Controls the lowest quota that can be assigned to a member because of another recovering member in the group, independently of the calculated minimum quota executed in the last period. A value of 0 implies that there is no minimum quota. Cannot be larger than
group_replication_flow_control_max_commit_quota.group_replication_flow_control_modeProperty Value Command-Line Format --group-replication-flow-control-mode=valueSystem Variable group_replication_flow_control_modeScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value QUOTAValid Values DISABLEDQUOTASpecifies the mode used for flow control. This variable can be changed without resetting Group Replication.
group_replication_flow_control_periodProperty Value Command-Line Format --group-replication-flow-control-period=valueIntroduced 8.0.2 System Variable group_replication_flow_control_periodScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1Minimum Value 1Maximum Value 60Defines how many seconds to wait between flow control iterations, in which flow control messages are sent and flow control management tasks are run.
group_replication_flow_control_release_percentProperty Value Command-Line Format --group-replication-flow-control-release-percent=valueIntroduced 8.0.2 System Variable group_replication_flow_control_release_percentScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 50Minimum Value 0Maximum Value 1000Defines how the group quota should be released when flow control no longer needs to throttle the writer members, with this percentage being the quota increase per flow control period. A value of 0 implies that once the flow control thresholds are within limits the quota is released in a single flow control iteration. The range allows the quota to be released at up to 10 times current quota, as that allows a greater degree of adaptation, mainly when the flow control period is large and the quotas are very small.
group_replication_force_membersProperty Value Command-Line Format --group-replication-force-members=valueSystem Variable group_replication_force_membersScope Global Dynamic Yes SET_VARHint AppliesNo Type String A list of peer addresses as a comma separated list such as
host1:port1,host2:port2. This option is used to force a new group membership, in which the excluded members do not receive a new view and are blocked.You must specify the address or host name and port as they are given in the
group_replication_local_addressoption for each member. An IPv6 address must be specified in square brackets. For example:"198.51.100.44:33061,[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061,example.org:33061"
The group communication engine (XCom) checks that the supplied IP addresses are in a valid format, and checks that you have not included any group members that are currently unreachable. Otherwise, the new configuration is not validated, so you must be careful to include only online servers that are reachable members of the group. Any incorrect values or invalid host names in the list could cause the group to be blocked with an invalid configuration.
It is important before forcing a new membership configuration to ensure that the servers to be excluded have been shut down. If they are not, shut them down before proceeding. Group members that are still online can automatically form new configurations, and if this has already taken place, forcing a further new configuration could create an artificial split-brain situation for the group.
After you have used the
group_replication_force_memberssystem variable to successfully force a new group membership and unblock the group, ensure that you clear the system variable.group_replication_force_membersmust be empty in order to issue aSTART GROUP_REPLICATIONstatement.For details of the procedure to follow, see Section 18.4.4, “Network Partitioning”.
-
Property Value Command-Line Format --group-replication-group-name=valueSystem Variable group_replication_group_nameScope Global Dynamic Yes SET_VARHint AppliesNo Type String The name of the group which this server instance belongs to. Must be a valid UUID. This UUID is used internally when setting GTIDs for Group Replication events in the binary log.
ImportantA unique UUID must be used.
-
Property Value Command-Line Format --group-replication-group-seeds=valueSystem Variable group_replication_group_seedsScope Global Dynamic Yes SET_VARHint AppliesNo Type String A list of group members that provide a member which joins the group with the data required for the joining member to gain synchrony with the group. The list consists of a single internal network address or host name for each included seed member, as configured in the seed member's
group_replication_local_addresssystem variable (not the seed member's SQL hostname and port). The addresses of the seed members are specified as a comma separated list, such ashost1:port1,host2:port2. An IPv6 address must be specified in square brackets. For example:group_replication_group_seeds= "198.51.100.44:33061,[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061, example.org:33061"
Note that the value you specify for this variable is not validated until a
START GROUP_REPLICATIONstatement is issued and the Group Communication System (GCS) is available.Usually this list consists of all members of the group, but you can choose a subset of the group members to be seeds. The list must contain at least one valid member address. Each address is validated when starting Group Replication. If the list does not contain any valid member addresses, issuing
START GROUP_REPLICATIONfails.When a server is joining a replication group, it attempts to connect to the first seed member listed in its
group_replication_group_seedssystem variable. If the connection is refused, the joining member tries to connect to each of the other seed members in the list in order. If the joining member connects to a seed member but does not get added to the replication group as a result (for example, because the seed member does not have the joining member's address in its whitelist and closes the connection), the joining member continues to try the remaining seed members in the list in order.A joining member must communicate with the seed member using the same protocol (IPv4 or IPv6) that the seed member advertises in the
group_replication_group_seedsoption. For the purpose of IP address whitelisting for Group Replication, the whitelist on the seed member must include an IP address for the joining member for the protocol offered by the seed member, or a host name that resolves to an address for that protocol. This address or host name must be set up and whitelisted in addition to the joining member'sgroup_replication_local_addressif the protocol for that address does not match the seed member's advertised protocol. If a joining member does not have a whitelisted address for the appropriate protocol, its connection attempt is refused. For more information, see Section 18.5.1, “IP Address Whitelisting”. group_replication_gtid_assignment_block_sizeProperty Value Command-Line Format --group-replication-gtid-assignment-block-size=valueSystem Variable group_replication_gtid_assignment_block_sizeScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 1000000Minimum Value 1Maximum Value (64-bit platforms) 9223372036854775807Maximum Value (32-bit platforms) 4294967295The number of consecutive GTIDs that are reserved for each member. Each member consumes its blocks and reserves more when needed.
group_replication_ip_whitelistProperty Value Command-Line Format --group-replication-ip-whitelist=valueSystem Variable group_replication_ip_whitelistScope Global Dynamic Yes SET_VARHint AppliesNo Type String Default Value AUTOMATICSpecifies which hosts are permitted to connect to the group. The address that you specify for each group member in
group_replication_local_addressmust be whitelisted on the other servers in the replication group. Note that the value you specify for this variable is not validated until aSTART GROUP_REPLICATIONstatement is issued and the Group Communication System (GCS) is available.By default, this system variable is set to
AUTOMATIC, which permits connections from private subnetworks active on the host. The group communication engine (XCom) automatically scans active interfaces on the host, and identifies those with addresses on private subnetworks. These addresses and thelocalhostIP address for IPv4 and (from MySQL 8.0.14) IPv6 are used to create the Group Replication whitelist. For a list of the ranges from which addresses are automatically whitelisted, see Section 18.5.1, “IP Address Whitelisting”.The automatic whitelist of private addresses cannot be used for connections from servers outside the private network. For Group Replication connections between server instances that are on different machines, you must provide public IP addresses and specify these as an explicit whitelist. If you specify any entries for the whitelist, the private and
localhostaddresses are not added automatically, so if you use any of these, you must specify them explicitly.As the value of the
group_replication_ip_whitelistoption, you can specify any combination of the following:IPv4 addresses (for example,
198.51.100.44)IPv4 addresses with CIDR notation (for example,
192.0.2.21/24)IPv6 addresses, from MySQL 8.0.14 (for example,
2001:db8:85a3:8d3:1319:8a2e:370:7348)IPv6 addresses with CIDR notation, from MySQL 8.0.14 (for example,
2001:db8:85a3:8d3::/64)Host names (for example,
example.org)Host names with CIDR notation (for example,
www.example.com/24)
Before MySQL 8.0.14, host names could only resolve to IPv4 addresses. From MySQL 8.0.14, host names can resolve to IPv4 addresses, IPv6 addresses, or both. If a host name resolves to both an IPv4 and an IPv6 address, the IPv4 address is always used for Group Replication connections. You can use CIDR notation in combination with host names or IP addresses to whitelist a block of IP addresses with a particular network prefix, but do ensure that all the IP addresses in the specified subnet are under your control.
A comma must separate each entry in the whitelist. For example:
"192.0.2.21/24,198.51.100.44,203.0.113.0/24,2001:db8:85a3:8d3:1319:8a2e:370:7348,example.org,www.example.com/24"
If any of the seed members for the group are listed in the
group_replication_group_seedsoption with an IPv6 address when a joining member has an IPv4group_replication_local_address, or the reverse, you must also set up and whitelist an alternative address for the joining member for the protocol offered by the seed member (or a host name that resolves to an address for that protocol). For more information, see Section 18.5.1, “IP Address Whitelisting”.It is possible to configure different whitelists on different group members according to your security requirements, for example, in order to keep different subnets separate. However, this can cause issues when a group is reconfigured. If you do not have a specific security requirement to do otherwise, use the same whitelist on all members of a group. For more details, see Section 18.5.1, “IP Address Whitelisting”.
For host names, name resolution takes place only when a connection request is made by another server. A host name that cannot be resolved is not considered for whitelist validation, and a warning message is written to the error log. Forward-confirmed reverse DNS (FCrDNS) verification is carried out for resolved host names.
WarningHost names are inherently less secure than IP addresses in a whitelist. FCrDNS verification provides a good level of protection, but can be compromised by certain types of attack. Specify host names in your whitelist only when strictly necessary, and ensure that all components used for name resolution, such as DNS servers, are maintained under your control. You can also implement name resolution locally using the hosts file, to avoid the use of external components.
group_replication_local_addressProperty Value Command-Line Format --group-replication-local-address=valueSystem Variable group_replication_local_addressScope Global Dynamic Yes SET_VARHint AppliesNo Type String The network address which the member provides for connections from other members, specified as a
host:portformatted string. This address must be reachable by all members of the group because it is used by the group communication engine (XCom, a Paxos variant) for TCP communication between remote XCom instances. Communication with the local instance is over an input channel using shared memory.WarningDo not use this address for communication with the member. This is not the MySQL server SQL protocol host and port.
The address or host name that you specify in
group_replication_local_addressis used by Group Replication as the unique identifier for a group member within the replication group. You can use the same port for all members of a replication group as long as the host names or IP addresses are all different, and you can use the same host name or IP address for all members as long as the ports are all different. The recommended port forgroup_replication_local_addressis 33061. Note that the value you specify for this variable is not validated until theSTART GROUP_REPLICATIONstatement is issued and the Group Communication System (GCS) is available.The network address configured by
group_replication_local_addressmust be resolvable by all group members. For example, if each server instance is on a different machine with a fixed network address, you could use the IP address of the machine, such as 10.0.0.1. If you use a host name, you must use a fully qualified name, and ensure it is resolvable through DNS, correctly configured/etc/hostsfiles, or other name resolution processes. From MySQL 8.0.14, IPv6 addresses (or host names that resolve to them) can be used as well as IPv4 addresses. An IPv6 address must be specified in square brackets in order to distinguish the port number, for example:group_replication_local_address= "[2001:db8:85a3:8d3:1319:8a2e:370:7348]:33061"
If a host name specified as the Group Replication local address for a server instance resolves to both an IPv4 and an IPv6 address, the IPv4 address is always used for Group Replication connections. For more information on Group Replication support for IPv6 networks and on replication groups with a mix of members using IPv4 and members using IPv6, see Section 18.4.5, “Support For IPv6 And For Mixed IPv6 And IPv4 Groups”.
For the purpose of IP address whitelisting for Group Replication, the address that you specify for each group member in
group_replication_local_addressmust be added to the list for thegroup_replication_ip_whitelistoption on the other servers in the replication group. If any of the seed members for the group are listed in thegroup_replication_group_seedsoption with an IPv6 address when this member has an IPv4group_replication_local_address, or the reverse, you must also set up and whitelist an alternative address for this member for the required protocol (or a host name that resolves to an address for that protocol). For more information, see Section 18.5.1, “IP Address Whitelisting”.group_replication_member_weightProperty Value Command-Line Format --group-replication-member-weight=valueIntroduced 8.0.2 System Variable group_replication_member_weightScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 50Minimum Value 0Maximum Value 100A percentage weight that can be assigned to members to influence the chance of the member being elected as primary in the event of failover, for example when the existing primary leaves a single-primary group. Assign numeric weights to members to ensure that specific members are elected, for example during scheduled maintenance of the primary or to ensure certain hardware is prioritized in the event of failover.
For a group with members configured as follows:
member-1: group_replication_member_weight=30, server_uuid=aaaamember-2: group_replication_member_weight=40, server_uuid=bbbbmember-3: group_replication_member_weight=40, server_uuid=ccccmember-4: group_replication_member_weight=40, server_uuid=dddd
during election of a new primary the members above would be sorted as
member-2,member-3,member-4, andmember-1. This results inmember-2 being chosen as the new primary in the event of failover. For more information, see Section 18.4.1.1, “Single-Primary Mode”.group_replication_member_expel_timeoutProperty Value Command-Line Format --group-replication-member-expel-timeout=valueIntroduced 8.0.13 System Variable group_replication_member_expel_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value (>= 8.0.14) 3600Maximum Value (<= 8.0.13) 31536000The period of time in seconds that a Group Replication group member waits after creating a suspicion before expelling from the group the member suspected of having failed. The initial 5-second detection period before a suspicion is created does not count as part of this time. Changing the value of
group_replication_member_expel_timeouton a group member takes effect immediately for existing as well as future suspicions on that group member. It is not mandatory for all members of a group to have the same setting, but it is recommended in order to avoid unexpected expulsions.A group member is expelled when another member's suspicion of it (or its own suspicion of itself) times out. By default,
group_replication_member_expel_timeoutis set to 0, meaning that there is no waiting period and a suspected member is liable for expulsion immediately after the 5-second detection period ends. An additional short period of time might elapse before the expelling mechanism detects and implements the expulsion. If a group member is at an older MySQL Server version that does not support this setting, this is its behavior towards other members or itself.To avoid unnecessary expulsions on slower networks, or in the case of expected transient network failures or machine slowdowns, you can specify a timeout value greater than zero, up to a maximum of 3600 seconds (1 hour). If a suspect member becomes active again before the suspicion times out, it rejoins the group, applies all the messages that were buffered by the remaining group members, and enters
ONLINEstate. Otherwise, it is liable for expulsion immediately after the suspicion times out. For alternative mitigation strategies where this system variable is not available, see Section 18.8.2, “Group Replication Limitations”.The waiting period before expelling a member only applies to members that have previously been active in the group. Non-members that were never active in the group do not get this waiting period and are removed after the initial detection period because they took too long to join.
If any members in a group are currently under suspicion, the group membership cannot be reconfigured (by adding or removing members or electing a new leader). If group membership changes need to be implemented while one or more members are under suspicion, and you want the suspect members to remain in the group, take any actions required to make the members active again, if that is possible. If you cannot make the members active again and you want them to be expelled from the group, you can force the suspicions to time out immediately. Do this by changing the value of
group_replication_member_expel_timeouton any active members to a value lower than the time that has already elapsed since the suspicions were created. The suspect members then become liable for expulsion immediately.An expelled member is not allowed to rejoin the group normally. If the expelled member does reconnect to the group and so becomes aware that it was expelled, it follows the action specified by the system variable
group_replication_exit_state_action. If this system variable is set toABORT_SERVER, which is the default, the expelled member shuts itself down. If it is set toREAD_ONLY, the expelled member remains online but switches itself to super read only mode.group_replication_poll_spin_loopsProperty Value Command-Line Format --group-replication-poll-spin-loops=valueSystem Variable group_replication_poll_spin_loopsScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value (64-bit platforms) 18446744073709551615Maximum Value (32-bit platforms) 4294967295The number of times the group communication thread waits for the communication engine mutex to be released before the thread waits for more incoming network messages.
group_replication_recovery_complete_atProperty Value Command-Line Format --group-replication-recovery-complete-at=valueSystem Variable group_replication_recovery_complete_atScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value TRANSACTIONS_APPLIEDValid Values TRANSACTIONS_CERTIFIEDTRANSACTIONS_APPLIEDRecovery policies when handling cached transactions after state transfer. This option specifies whether a member is marked online after it has received all transactions that it missed before it joined the group (
TRANSACTIONS_CERTIFIED) or after it has received and applied them (TRANSACTIONS_APPLIED).group_replication_recovery_get_public_keyProperty Value Command-Line Format --group-replication-recovery-get-public-keyIntroduced 8.0.4 System Variable group_replication_recovery_get_public_keyScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether to request from the master the public key required for RSA key pair-based password exchange. This variable applies to slaves that authenticate with the
caching_sha2_passwordauthentication plugin. For that plugin, the master does not send the public key unless requested.If
group_replication_recovery_public_key_pathis set to a valid public key file, it takes precedence overgroup_replication_recovery_get_public_key.group_replication_recovery_public_key_pathProperty Value Command-Line Format --group-replication-recovery-public-key-pathIntroduced 8.0.4 System Variable group_replication_recovery_public_key_pathScope Global Dynamic Yes SET_VARHint AppliesNo Type File name Default Value NULLThe path name to a file containing a slave-side copy of the public key required by the master for RSA key pair-based password exchange. The file must be in PEM format. This variable applies to slaves that authenticate with the
sha256_passwordorcaching_sha2_passwordauthentication plugin. (Forsha256_password, settinggroup_replication_recovery_public_key_pathapplies only if MySQL was built using OpenSSL.)If
group_replication_recovery_public_key_pathis set to a valid public key file, it takes precedence overgroup_replication_recovery_get_public_key.group_replication_recovery_reconnect_intervalProperty Value Command-Line Format --group-replication-recovery-reconnect-interval=valueSystem Variable group_replication_recovery_reconnect_intervalScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 60Minimum Value 0Maximum Value 31536000The sleep time, in seconds, between reconnection attempts when no donor was found in the group.
group_replication_recovery_retry_countProperty Value Command-Line Format --group-replication-recovery-retry-count=valueSystem Variable group_replication_recovery_retry_countScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 10Minimum Value 0Maximum Value 31536000The number of times that the member that is joining tries to connect to the available donors before giving up.
group_replication_recovery_ssl_caProperty Value Command-Line Format --group-replication-recovery-ssl-ca=valueSystem Variable group_replication_recovery_ssl_caScope Global Dynamic Yes SET_VARHint AppliesNo Type String The path to a file that contains a list of trusted SSL certificate authorities.
group_replication_recovery_ssl_capathProperty Value Command-Line Format --group-replication-recovery-ssl-capath=valueSystem Variable group_replication_recovery_ssl_capathScope Global Dynamic Yes SET_VARHint AppliesNo Type String The path to a directory that contains trusted SSL certificate authority certificates.
group_replication_recovery_ssl_certProperty Value Command-Line Format --group-replication-recovery-ssl-cert=valueSystem Variable group_replication_recovery_ssl_certScope Global Dynamic Yes SET_VARHint AppliesNo Type String The name of the SSL certificate file to use for establishing a secure connection.
group_replication_recovery_ssl_cipherProperty Value Command-Line Format --group-replication-recovery-ssl-cipher=valueSystem Variable group_replication_recovery_ssl_cipherScope Global Dynamic Yes SET_VARHint AppliesNo Type String The list of permitted ciphers for SSL encryption.
group_replication_recovery_ssl_crlProperty Value Command-Line Format --group-replication-recovery-ssl-crl=valueSystem Variable group_replication_recovery_ssl_crlScope Global Dynamic Yes SET_VARHint AppliesNo Type File name The path to a directory that contains files containing certificate revocation lists.
group_replication_recovery_ssl_crlpathProperty Value Command-Line Format --group-replication-recovery-ssl-crlpath=valueSystem Variable group_replication_recovery_ssl_crlpathScope Global Dynamic Yes SET_VARHint AppliesNo Type Directory name The path to a directory that contains files containing certificate revocation lists.
group_replication_recovery_ssl_keyProperty Value Command-Line Format --group-replication-recovery-ssl-key=valueSystem Variable group_replication_recovery_ssl_keyScope Global Dynamic Yes SET_VARHint AppliesNo Type String The name of the SSL key file to use for establishing a secure connection.
group_replication_recovery_ssl_verify_server_certProperty Value Command-Line Format --group-replication-recovery-ssl-verify-server-cert=valueSystem Variable group_replication_recovery_ssl_verify_server_certScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFMake the recovery process check the server's Common Name value in the donor sent certificate.
group_replication_recovery_use_sslProperty Value Command-Line Format --group-replication-recovery-use-ssl=valueSystem Variable group_replication_recovery_use_sslScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value OFFWhether Group Replication recovery connection should use SSL or not.
group_replication_single_primary_modeProperty Value Command-Line Format --group-replication-single-primary-mode=valueSystem Variable group_replication_single_primary_modeScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONInstructs the group to automatically pick a single server to be the one that handles read/write workload. This server is the PRIMARY and all others are SECONDARIES.
-
Property Value Command-Line Format --group-replication-ssl-mode=valueSystem Variable group_replication_ssl_modeScope Global Dynamic Yes SET_VARHint AppliesNo Type Enumeration Default Value DISABLEDValid Values DISABLEDREQUIREDVERIFY_CAVERIFY_IDENTITYSpecifies the security state of the connection between Group Replication members.
group_replication_start_on_bootProperty Value Command-Line Format --group-replication-start-on-boot=valueSystem Variable group_replication_start_on_bootScope Global Dynamic Yes SET_VARHint AppliesNo Type Boolean Default Value ONWhether the server should start Group Replication or not during server start.
group_replication_transaction_size_limitProperty Value Command-Line Format --group-replication-transaction-size-limit=valueSystem Variable group_replication_transaction_size_limitScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value (>= 8.0.2) 150000000Default Value (<= 8.0.1) 0Minimum Value 0Maximum Value 2147483647Configures the maximum transaction size in bytes which the replication group accepts. Transactions larger than this size are rolled back by the receiving member and are not broadcast to the group. Large transactions can cause problems for a replication group in terms of memory allocation, which can cause the system to slow down, or in terms of network bandwidth consumption, which can cause a member to be suspected of having failed because it is busy processing the large transaction.
When this system variable is set to 0 there is no limit to the size of transactions the group accepts. From MySQL 8.0, the default setting for this system variable is 150000000 bytes (approximately 143 MB). Adjust the value of this system variable depending on the maximum message size that you need the group to tolerate, bearing in mind that the time taken to process a transaction is proportional to its size. For further mitigation strategies, see Section 18.8.2, “Group Replication Limitations”.
group_replication_unreachable_majority_timeoutProperty Value Command-Line Format --group-replication-unreachable-majority-timeout=valueIntroduced 8.0.2 System Variable group_replication_unreachable_majority_timeoutScope Global Dynamic Yes SET_VARHint AppliesNo Type Integer Default Value 0Minimum Value 0Maximum Value 31536000Configures how long members that suffer a network partition and cannot connect to the majority wait before leaving the group.
In a group of 5 servers (S1,S2,S3,S4,S5), if there is a disconnection between (S1,S2) and (S3,S4,S5) there is a network partition. The first group (S1,S2) is now in a minority because it cannot contact more than half of the group. While the majority group (S3,S4,S5) remains running, the minority group waits for the specified time for a network reconnection. Any transactions processed by the minority group are blocked until Group Replication is stopped using
STOP GROUP REPLICATIONon the members of the minority. Note thatgroup_replication_unreachable_majority_timeouthas no effect if it is set on the servers in the minority group after the loss of majority has been detected.By default, this system variable is set to 0, which means that members that find themselves in a minority due to a network partition wait forever to leave the group. If configured to a number of seconds, members wait for this amount of time after losing contact with the majority of members before leaving the group. When the specified time elapses, all pending transactions processed by the minority are rolled back, and the servers in the minority partition move to the
ERRORstate. These servers then follow the action specified by the system variablegroup_replication_exit_state_action, which can be to set themselves to super read only mode or shut down MySQL.WarningWhen you have a symmetric group, with just two members for example (S0,S2), if there is a network partition and there is no majority, after the configured timeout all members enter
ERRORstate.
This section describes the status variables which provide information about Group Replication. The variable has the following meaning:
group_replication_primary_memberShows the primary member's UUID when the group is operating in single-primary mode. If the group is operating in multi-primary mode, shows an empty string.
WarningThe
group_replication_primary_memberstatus variable has been deprecated and is scheduled to be removed in a future version.
This section lists and explains the requirements and limitations of Group Replication.
Server instances that you want to use for Group Replication must satisfy the following requirements.
InnoDB Storage Engine. Data must be stored in the
InnoDBtransactional storage engine. Transactions are executed optimistically and then, at commit time, are checked for conflicts. If there are conflicts, in order to maintain consistency across the group, some transactions are rolled back. This means that a transactional storage engine is required. Moreover,InnoDBprovides some additional functionality that enables better management and handling of conflicts when operating together with Group Replication.Primary Keys. Every table that is to be replicated by the group must have a defined primary key, or primary key equivalent where the equivalent is a non-null unique key. Such keys are required as a unique identifier for every row within a table, enabling the system to determine which transactions conflict by identifying exactly which rows each transaction has modified.
Network Performance. MySQL Group Replication is designed to be deployed in a cluster environment where server instances are very close to each other. The performance and stabiity of a group can be impacted by both network latency and network bandwidth. Bi-directional communication must be maintained at all times between all group members. If either inbound or outbound communication is blocked for a server instance (for example, by a firewall, or by connectivity issues), the member cannot function in the group, and the group members (including the member with issues) might not be able to report the correct member status for the affected server instance.
From MySQL 8.0.14, you can use an IPv4 or IPv6 network infrastructure, or a mix of the two, for TCP communication between remote Group Replication servers. There is also nothing preventing Group Replication from operating over a virtual private network (VPN).
Also from MySQL 8.0.14, where Group Replication server instances are co-located and share a local group communication engine (XCom) instance, a dedicated input channel with lower overhead is used for communication where possible instead of the TCP socket. For certain Group Replication tasks that require communication between remote XCom instances, such as joining a group, the TCP network is still used, so network performance influences the group's performance.
The following options must be configured on server instances that are members of a group.
Binary Log Active. Set
--log-bin[=log_file_name]. MySQL Group Replication replicates binary log contents, therefore the binary log needs to be on for it to operate. This option is enabled by default. See Section 5.4.4, “The Binary Log”.Slave Updates Logged. Set
--log-slave-updates. Servers need to log binary logs that are applied through the replication applier. Servers in the group need to log all transactions that they receive and apply from the group. This is required because recovery is conducted by relying on binary logs form participants in the group. Therefore, copies of each transaction need to exist on every server, even for those transactions that were not initiated on the server itself. This option is enabled by default.Binary Log Row Format. Set
--binlog-format=row. Group Replication relies on row-based replication format to propagate changes consistently among the servers in the group. It relies on row-based infrastructure to be able to extract the necessary information to detect conflicts among transactions that execute concurrently in different servers in the group. See Section 17.2.1, “Replication Formats”.Global Transaction Identifiers On. Set
--gtid-mode=ON. Group Replication uses global transaction identifiers to track exactly which transactions have been committed on every server instance and thus be able to infer which servers have executed transactions that could conflict with already committed transactions elsewhere. In other words, explicit transaction identifiers are a fundamental part of the framework to be able to determine which transactions may conflict. See Section 17.1.3, “Replication with Global Transaction Identifiers”.Replication Information Repositories. Set
--master-info-repository=TABLEand--relay-log-info-repository=TABLE. The replication applier needs to have the master information and relay log metadata written to themysql.slave_master_infoandmysql.slave_relay_log_infosystem tables. This ensures the Group Replication plugin has consistent recoverability and transactional management of the replication metadata. From MySQL 8.0.2, these options are set toTABLEby default, and from MySQL 8.0.3, theFILEsetting is deprecated. See Section 17.2.4.2, “Slave Status Logs”.Transaction Write Set Extraction. Set
--transaction-write-set-extraction=XXHASH64so that while collecting rows to log them to the binary log, the server collects the write set as well. The write set is based on the primary keys of each row and is a simplified and compact view of a tag that uniquely identifies the row that was changed. This tag is then used for detecting conflicts. This option is enabled by default.Multithreaded Appliers. Group Replication members can be configured as multithreaded slaves, enabling transactions to be applied in parallel. A nonzero value for
slave_parallel_workersenables the multithreaded applier on the member, and up to 1024 parallel applier threads can be specified. Settingslave_preserve_commit_order=1ensures that the final commit of parallel transactions is in the same order as the original transactions, as required for Group Replication, which relies on consistency mechanisms built around the guarantee that all participating members receive and apply committed transaction in the same order. Finally, the settingslave_parallel_type=LOGICAL_CLOCK, which specifies the policy used to decide which transactions are allowed to execute in parallel on the slave, is required withslave_preserve_commit_order=1. Settingslave_parallel_workers=0disables parallel execution and gives the slave a single applier thread and no coordinator thread. With that setting, theslave_parallel_typeandslave_preserve_commit_orderoptions have no effect and are ignored.
The following known limitations exist for Group Replication. Note that the limitations and issues described for multi-primary mode groups can also apply in single-primary mode clusters during a failover event, while the newly elected primary flushes out its applier queue from the old primary.
Group Replication is built on GTID based replication, therefore you should also be aware of Section 17.1.3.6, “Restrictions on Replication with GTIDs”.
Replication Event Checksums. Due to a design limitation of replication event checksums, Group Replication cannot currently make use of them. Therefore set
--binlog-checksum=NONE.Gap Locks. The certification process does not take into account gap locks, as information about gap locks is not available outside of
InnoDB. See Gap Locks for more information.NoteUnless you rely on
REPEATABLE READsemantics in your applications, we recommend using theREAD COMMITTEDisolation level with Group Replication. InnoDB does not use gap locks inREAD COMMITTED, which aligns the local conflict detection within InnoDB with the distributed conflict detection performed by Group Replication.Table Locks and Named Locks. The certification process does not take into account table locks (see Section 13.3.6, “LOCK TABLES and UNLOCK TABLES Syntax”) or named locks (see
GET_LOCK()).SERIALIZABLE Isolation Level.
SERIALIZABLEisolation level is not supported in multi-primary groups by default. Setting a transaction isolation level toSERIALIZABLEconfigures Group Replication to refuse to commit the transaction.Concurrent DDL versus DML Operations. Concurrent data definition statements and data manipulation statements executing against the same object but on different servers is not supported when using multi-primary mode. During execution of Data Definition Language (DDL) statements on an object, executing concurrent Data Manipulation Language (DML) on the same object but on a different server instance has the risk of conflicting DDL executing on different instances not being detected.
Foreign Keys with Cascading Constraints. Multi-primary mode groups (members all configured with
group_replication_single_primary_mode=OFF) do not support tables with multi-level foreign key dependencies, specifically tables that have definedCASCADINGforeign key constraints. This is because foreign key constraints that result in cascading operations executed by a multi-primary mode group can result in undetected conflicts and lead to inconsistent data across the members of the group. Therefore we recommend settinggroup_replication_enforce_update_everywhere_checks=ONon server instances used in multi-primary mode groups to avoid undetected conflicts.In single-primary mode this is not a problem as it does not allow concurrent writes to multiple members of the group and thus there is no risk of undetected conflicts.
Very Large Transactions. If an individual transaction results in GTID contents which are large enough that the message cannot be copied between group members over the network within a 5-second window, members can be suspected of having failed, and then expelled, just because they are busy processing the transaction. Large transactions can also cause the system to slow due to problems with memory allocation. To avoid these issues use the following mitigations:
Where possible, try and limit the size of your transactions. For example, split up files used with
LOAD DATAinto smaller chunks.Use the system variable
group_replication_transaction_size_limitto specify a maximum transaction size that the group will accept. Transactions above this size are rolled back and are not sent to the group. In MySQL 8.0, this system variable defaults to a maximum transaction size of 150000000 bytes (approximately 143 MB). Adjust the value of this variable depending on the maximum message size that you need the group to tolerate, bearing in mind that the time taken to process a transaction is proportional to its size.From MySQL 8.0.13, you can use the system variable
group_replication_member_expel_timeoutto allow additional time before a member under suspicion of having failed is expelled. You can allow up to an hour after the initial 5-second detection period before a suspect member is expelled from the group.
Multi-primary Mode Deadlock. When a group is operating in multi-primary mode,
SELECT .. FOR UPDATEstatements can result in a deadlock. This is because the lock is not shared across the members of the group, therefore the expectation for such a statement might not be reached.Replication Filters. Global replication filters cannot be used on a MySQL server instance that is configured for Group Replication, because filtering transactions on some servers would make the group unable to reach agreement on a consistent state. Channel specific replication filters can be used on replication channels that are not directly involved with Group Replication, such as where a group member also acts as a replication slave to a master that is outside the group. They cannot be used on the
group_replication_applierorgroup_replication_recoverychannels.Encrypted Connections. Support for the TLSv1.3 protocol is available in MySQL Server as of MySQL 8.0.16, and requires compiling MySQL using OpenSSL 1.1.1 or higher. Group Replication does not currently support TLSv1.3, and if the server was compiled with this support, it is explicitly disabled in the group communication engine.
This section provides answers to frequently asked questions.
A group can consist of maximum 9 servers. Attempting to add another server to a group with 9 members causes the request to join to be refused.
Servers in a group connect to the other servers in the group by
opening a peer-to-peer TCP connection. These connections are only
used for internal communication and message passing between
servers in the group. This address is configured by the
group_replication_local_address
variable.
The bootstrap flag instructs a member to create a group and act as the initial seed server. The second member joining the group needs to ask the member that bootstrapped the group to dynamically change the configuration in order for it to be added to the group.
A member needs to bootstrap the group in two scenarios. When the group is originally created, or when shutting down and restarting the entire group.
You pre-configure the Group Replication recovery channel
credentials using the CHANGE MASTER
TO statement.
Not directly, but MySQL Group replication is a shared nothing full replication solution, where all servers in the group replicate the same amount of data. Therefore if one member in the group writes N bytes to storage as the result of a transaction commit operation, then roughly N bytes are written to storage on other members as well, because the transaction is replicated everywhere.
However, given that other members do not have to do the same amount of processing that the original member had to do when it originally executed the transaction, they apply the changes faster. Transactions are replicated in a format that is used to apply row transformations only, without having to re-execute transactions again (row-based format).
Furthermore, given that changes are propagated and applied in row-based format, this means that they are received in an optimized and compact format, and likely reducing the number of IO operations required when compared to the originating member.
To summarize, you can scale-out processing, by spreading conflict free transactions throughout different members in the group. And you can likely scale-out a small fraction of your IO operations, since remote servers receive only the necessary changes to read-modify-write changes to stable storage.
Some additional load is expected because servers need to be constantly interacting with each other for synchronization purposes. It is difficult to quantify how much more data. It also depends on the size of the group (three servers puts less stress on the bandwidth requirements than nine servers in the group).
Also the memory and CPU footprint are larger, because more complex work is done for the server synchronization part and for the group messaging.
Yes, but the network connection between each member must be reliable and have suitable perfomance. Low latency, high bandwidth network connections are a requirement for optimal performance.
If network bandwidth alone is an issue, then Section 18.10.7.2, “Message Compression” can be used to lower the bandwidth required. However, if the network drops packets, leading to re-transmissions and higher end-to-end latency, throughput and latency are both negatively affected.
When the network round-trip time (RTT) between any group members is 2 seconds or more you could encounter problems as the built-in failure detection mechanism could be incorrectly triggered.
This depends on the reason for the connectivity problem. If the connectivity problem is transient and the reconnection is quick enough that the failure detector is not aware of it, then the server may not be removed from the group. If it is a "long" connectivity problem, then the failure detector eventually suspects a problem and the server is removed from the group.
Once a server is removed from the group, you need to join it back again. In other words, after a server is removed explicitly from the group you need to rejoin it manually (or have a script doing it automatically).
If the member becomes silent, the other members remove it from the group configuration. In practice this may happen when the member has crashed or there is a network disconnection.
The failure is detected after a given timeout elapses for a given member and a new configuration without the silent member in it is created.
There is no method for defining policies for when to expel members automatically from the group. You need to find out why a member is lagging behind and fix that or remove the member from the group. Otherwise, if the server is so slow that it triggers the flow control, then the entire group slows down as well. The flow control can be configured according to the your needs.
No, there is no special member in the group in charge of triggering a reconfiguration.
Any member can suspect that there is a problem. All members need to (automatically) agree that a given member has failed. One member is in charge of expelling it from the group, by triggering a reconfiguration. Which member is responsible for expelling the member is not something you can control or set.
Group Replication is designed to provide highly available replica sets; data and writes are duplicated on each member in the group. For scaling beyond what a single system can provide, you need an orchestration and sharding framework built around a number of Group Replication sets, where each replica set maintains and manages a given shard or partition of your total dataset. This type of setup, often called a “sharded cluster”, allows you to scale reads and writes linearly and without limit.
If SELinux is enabled, which you can verify using
sestatus -v, then you need to enable the use of
the Group Replication communication port, configured by
group_replication_local_address,
for mysqld so that it can bind to it and listen
there. To see which ports MySQL is currently allowed to use, issue
semanage port -l | grep mysqld. Assuming the
port configured is 33061, add the necessary port to those
permitted by SELinux by issuing semanage port -a -t
mysqld_port_t -p tcp 33061.
If iptables is enabled, then you need to open up the Group Replication port for communication between the machines. To see the current rules in place on each machine, issue iptables -L. Assuming the port configured is 33061, enable communication over the necessary port by issuing iptables -A INPUT -p tcp --dport 33061 -j ACCEPT.
The replication channels used by Group Replication behave in the
same way as replication channels used in master to slave
replication, and as such rely on the relay log. In the event of a
change of the relay_log variable,
or when the option is not set and the host name changes, there is
a chance of errors. See Section 17.2.4.1, “The Slave Relay Log” for
a recovery procedure in this situation. Alternatively, another way
of fixing the issue specifically in Group Replication is to issue
a STOP GROUP_REPLICATION statement
and then a START GROUP_REPLICATION
statement to restart the instance. The Group Replication plugin
creates the group_replication_applier channel
again.
Group Replication uses two bind addresses in order to split
network traffic between the SQL address, used by clients to
communicate with the member, and the
group_replication_local_address,
used internally by the group members to communicate. For example,
assume a server with two network interfaces assigned to the
network addresses 203.0.113.1 and
198.51.100.179. In such a situation you could
use 203.0.113.1:33061 for the internal group
network address by setting
group_replication_local_address=203.0.113.1:33061.
Then you could use 198.51.100.179 for
hostname and
3306 for the
port. Client SQL applications
would then connect to the member at
198.51.100.179:3306. This enables you to
configure different rules on the different networks. Similarly,
the internal group communication can be separated from the network
connection used for client applications, for increased security.
Group Replication uses network connections between members and
therefore its functionality is directly impacted by how you
configure hostnames and ports. For example, the Group Replication
recovery procedure is based on asynchronous replication which uses
the server's hostname and port. When a member joins a group it
receives the group membership information, using the network
address information that is listed at
performance_schema.replication_group_members.
One of the members listed in that table is selected as the donor
of the missing data from the group to the new member.
This means that any value you configure using a hostname, such as
the SQL network address or the group seeds address, must be a
fully qualified name and resolvable by each member of the group.
You can ensure this for example through DNS, or correctly
configured /etc/hosts files, or other local
processes. If a you want to configure the
MEMBER_HOST value on a server, specify it using
the --report-host option on the
server before joining it to the group.
The assigned value is used directly and is not affected by the
--skip-name-resolve option.
To configure MEMBER_PORT on a server, specify
it using the --report-port option.
If the group is operating in single-primary mode, it can be useful to find out which member is the primary. See Section 18.4.1.3, “Finding the Primary”
This section provides more technical details about MySQL Group Replication.
MySQL Group Replication is a MySQL plugin and it builds on the existing MySQL replication infrastructure, taking advantage of features such as the binary log, row-based logging, and global transaction identifiers. It integrates with current MySQL frameworks, such as the performance schema or plugin and service infrastructures. The following figure presents a block diagram depicting the overall architecture of MySQL Group Replication.
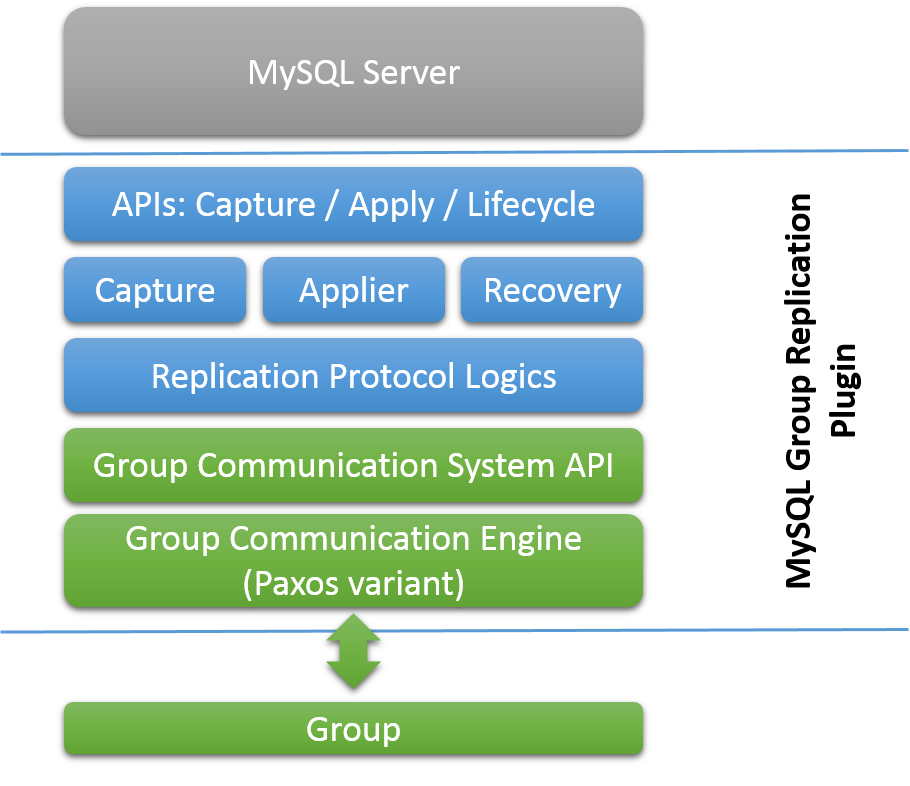
The MySQL Group Replication plugin includes a set of APIs for capture, apply, and lifecycle, which control how the plugin interacts with MySQL Server. There are interfaces to make information flow from the server to the plugin and vice versa. These interfaces isolate the MySQL Server core from the Group Replication plugin, and are mostly hooks placed in the transaction execution pipeline. In one direction, from server to the plugin, there are notifications for events such as the server starting, the server recovering, the server being ready to accept connections, and the server being about to commit a transaction. In the other direction, the plugin instructs the server to perform actions such as committing or aborting ongoing transactions, or queuing transactions in the relay log.
The next layer of the Group Replication plugin architecture is a set of components that react when a notification is routed to them. The capture component is responsible for keeping track of context related to transactions that are executing. The applier component is responsible for executing remote transactions on the database. The recovery component manages distributed recovery, and is responsible for getting a server that is joining the group up to date by selecting the donor, orchestrating the catch up procedure and reacting to donor failures.
Continuing down the stack, the replication protocol module contains the specific logic of the replication protocol. It handles conflict detection, and receives and propagates transactions to the group.
The final two layers of the Group Replication plugin architecture are the Group Communication System (GCS) API, and an implementation of a Paxos-based group communication engine (XCom). The GCS API is a high level API that abstracts the properties required to build a replicated state machine (see Section 18.1, “Group Replication Background”). It therefore decouples the implementation of the messaging layer from the remaining upper layers of the plugin. The group communication engine handles communications with the members of the replication group.
In MySQL Group Replication, a set of servers forms a replication group. A group has a name, which takes the form of a UUID. The group is dynamic and servers can leave (either voluntarily or involuntarily) and join it at any time. The group adjusts itself whenever servers join or leave.
If a server joins the group, it automatically brings itself up to date by fetching the missing state from an existing server. This state is transferred by means of Asynchronous MySQL replication. If a server leaves the group, for instance it was taken down for maintenance, the remaining servers notice that it has left and reconfigure the group automatically. The group membership service described at Section 18.1.3.2, “Group Membership” powers all of this.
As there are no primary servers (masters) for any particular data set, every server in the group is allowed to execute transactions at any time, even transactions that change state (RW transactions).
Any server may execute a transaction without any a priori coordination. But, at commit time, it coordinates with the rest of the servers in the group to reach a decision on the fate of that transaction. This coordination serves two purposes: (i) check whether the transaction should commit or not; (ii) and propagate the changes so that other servers can apply the transaction as well.
As a transaction is sent through an atomic broadcast, either all servers in the group receive the transaction or none do. If they receive it, then they all receive it in the same order with respect to other transactions that were sent before. Conflict detection is carried out by inspecting and comparing write sets of transactions. Thus, they are detected at the row level. Conflict resolution follows the first committer wins rule. If t1 and t2 execute concurrently at different sites, because t2 is ordered before t1, and both changed the same row, then t2 wins the conflict and t1 aborts. In other words, t1 was trying to change data that had been rendered stale by t2.
If two transactions are bound to conflict more often than not, then it is a good practice to start them on the same server. They then have a chance to synchronize on the local lock manager instead of aborting later in the replication protocol.
In a Group Replication topology, care needs to be taken when executing data definition statements, also commonly known as data definition language (DDL).
MySQL 8.0 introduces support for atomic Data Definition Language
(DDL) statements, where the complete DDL statement is either
committed or rolled back as a single atomic transaction. However,
DDL statements, atomic or otherwise, implicitly end any
transaction that is active in the current session, as if you had
done a COMMIT before
executing the statement. This means that DDL statements cannot be
performed within another transaction, within transaction control
statements such as START
TRANSACTION ... COMMIT, or combined with other
statements within the same transaction.
Group Replication is based on an optimistic replication paradigm, where statements are optimistically executed and rolled back later if necessary. Each server executes and commits without securing group agreement first. Therefore, more care needs to be taken when replicating DDL statements in multi-primary mode. If you make schema changes (using DDL) and changes to the data that an object contains (using DML) for the same object, the changes need to be handled through the same server while the schema operation has not yet completed and replicated everywhere. Failure to do so can result in data inconsistency when operations are interrupted or only partially completed. If the group is deployed in single-primary mode this issue does not occur, because all changes are performed through the same server, the primary.
For details on atomic DDL support in MySQL 8.0, and the resulting changes in behavior for the replication of certain statements, see Section 13.1.1, “Atomic Data Definition Statement Support”.
This section describes the process through which a member joining a group catches up with the remaining servers in the group, called distributed recovery.
This section is a high level summary. The following sections provide additional detail, by describing the phases of the procedure in more detail.
Group Replication distributed recovery can be summarized as the process through which a server gets missing transactions from the group so that it can then join the group having processed the same set of transactions as the other group members. During distributed recovery, the server joining the group buffers any transactions and membership events that happen while the server joining the group is receiving the transactions required from the group. Once the server joining the group has received all of the group's transactions, it applies the transactions that were buffered during the recovery process. At the end of this process the server then joins the group as an online member.
In the first phase, the server joining the group selects one of the online servers on the group to be the donor of the state that it is missing. The donor is responsible for providing the server joining the group all the data it is missing up to the moment it has joined the group. This is achieved by relying on a standard asynchronous replication channel, established between the donor and the server joining the group, see Section 17.2.3, “Replication Channels”. Through this replication channel, the donor's binary logs are replicated until the point that the view change happened when the server joining the group became part of the group. The server joining the group applies the donor's binary logs as it receives them.
While the binary log is being replicated, the server joining the group also caches every transaction that is exchanged within the group. In other words it is listening for transactions that are happening after it joined the group and while it is applying the missing state from the donor. When the first phase ends and the replication channel to the donor is closed, the server joining the group then starts phase two: the catch up.
In this phase, the server joining the group proceeds to the execution of the cached transactions. When the number of transactions queued for execution finally reaches zero, the member is declared online.
The recovery procedure withstands donor failures while the server joining the group is fetching binary logs from it. In such cases, whenever a donor fails during phase 1, the server joining the group fails over to a new donor and resumes from that one. When that happens the server joining the group closes the connection to the failed server joining the group explicitly and opens a connection to a new donor. This happens automatically.
To synchronize the server joining the group with the donor up to a specific point in time, the server joining the group and donor make use of the MySQL Global Transaction Identifiers (GTIDs) mechanism. See Section 17.1.3, “Replication with Global Transaction Identifiers”. However, GTIDS only provide a means to realize which transactions the server joining the group is missing, they do not help marking a specific point in time to which the server joining the group must catch up, nor do they help conveying certification information. This is the job of binary log view markers, which mark view changes in the binary log stream, and also contain additional metadata information, provisioning the server joining the group with missing certification related data.
To explain the concept of view change markers, it is important to understand what a view and a view change are.
A view corresponds to a group of members participating actively in the current configuration, in other words at a specific point in time. They are correct and online in the system.
A view change occurs when a modification to the group configuration happens, such as a member joining or leaving. Any group membership change results in an independent view change communicated to all members at the same logical point in time.
A view identifier uniquely identifies a view. It is generated whenever a view change happens
At the group communication layer, view changes with their associated view ids are then boundaries between the data exchanged before and after a member joins. This concept is implemented through a new binary log event: the"view change log event". The view id thus becomes a marker as well for transactions transmitted before and after changes happen in the group membership.
The view identifier itself is built from two parts: (i) one that is randomly generated and (ii) a monotonically increasing integer. The first part is generated when the group is created, and remains unchanged while there is at least one member in the group. The second part is incremented every time a view change happens.
The reason for this heterogeneous pair that makes up the view id is the need to unambiguously mark group changes whenever a member joins or leaves but also whenever all members leave the group and no information remains of what view the group was in. In fact, the sole use of monotonic increasing identifiers could lead to the reuse of the same id after full group shutdowns, destroying the uniqueness of the binary log data markers that recovery depends on. To summarize, the first part identifies whenever the group was started from the beginning and the incremental part when the group changed from that point on.
This section explains the process which controls how the view change identifier is incorporated into a binary log event and written to the log, The following steps are taken:
All servers are online and processing incoming transactions from the group. Some servers may be a little behind in terms of transactions replicated, but eventually they converge. The group acts as one distributed and replicated database.
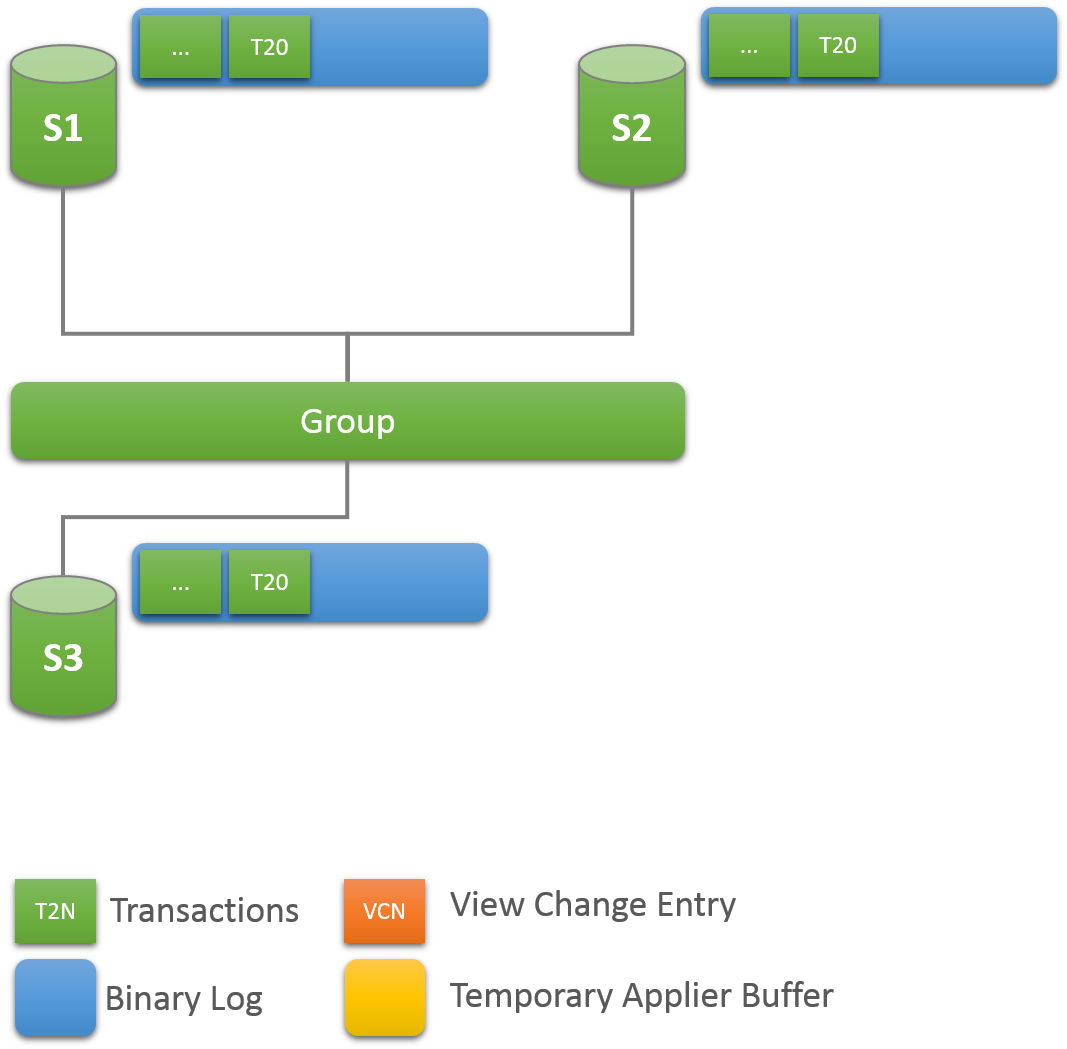
Whenever a new member joins the group and therefore a view change is performed, every online server queues a view change log event for execution. This is queued because before the view change, several transactions can be queued on the server to be applied and as such, these belong to the old view. Queuing the view change event after them guarantees a correct marking of when this happened.
Meanwhile, the server joining the group selects the donor from the list of online servers as stated by the membership service through the view abstraction. A member joins on view 4 and the online members write a View change event to the binary log.
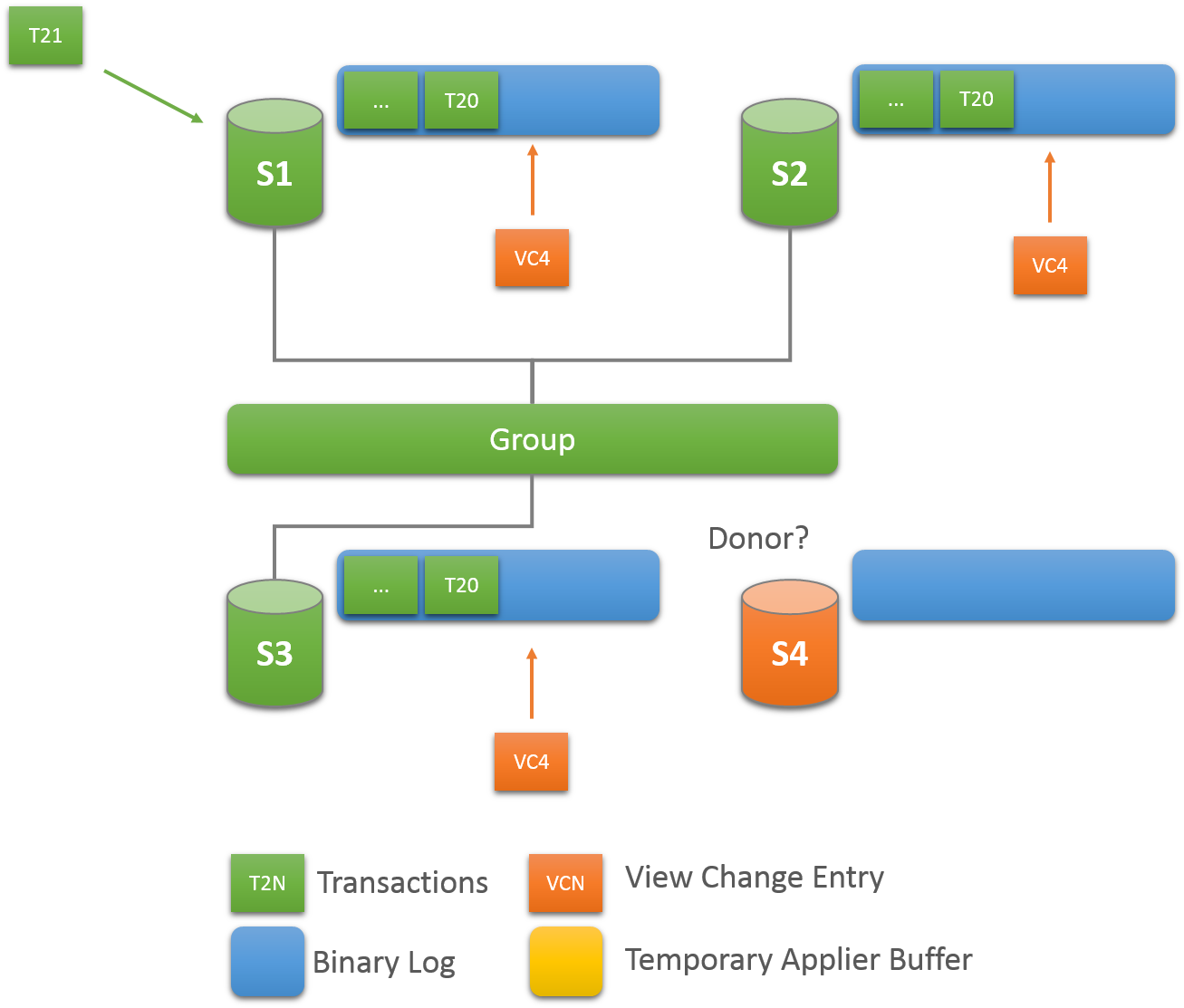
Once the server joining the group has chosen which server in the group is to be the donor, a new asynchronous replication connection is established between the two and the state transfer begins (phase 1). This interaction with the donor continues until the server joining the group's applier thread processes the view change log event that corresponds to the view change triggered when the server joining the group came into the group. In other words, the server joining the group replicates from the donor, until it gets to the marker with the view identifier which matches the view marker it is already in.
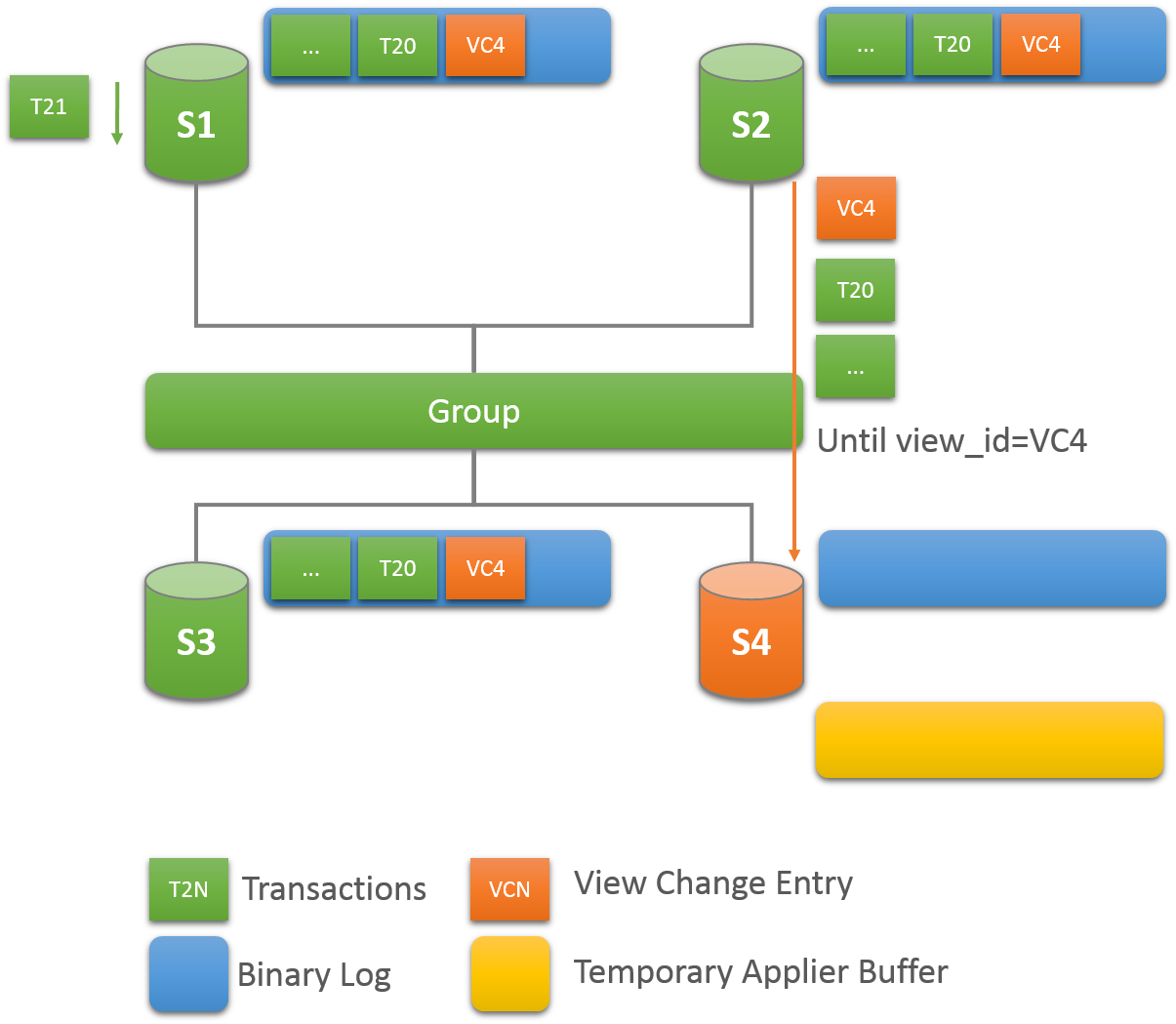
As view identifiers are transmitted to all members in the group at the same logical time, the server joining the group knows at which view identifier it should stop replicating. This avoids complex GTID set calculations because the view id clearly marks which data belongs to each group view.
While the server joining the group is replicating from the donor, it is also caching incoming transactions from the group. Eventually, it stops replicating from the donor and switches to applying those that are cached.
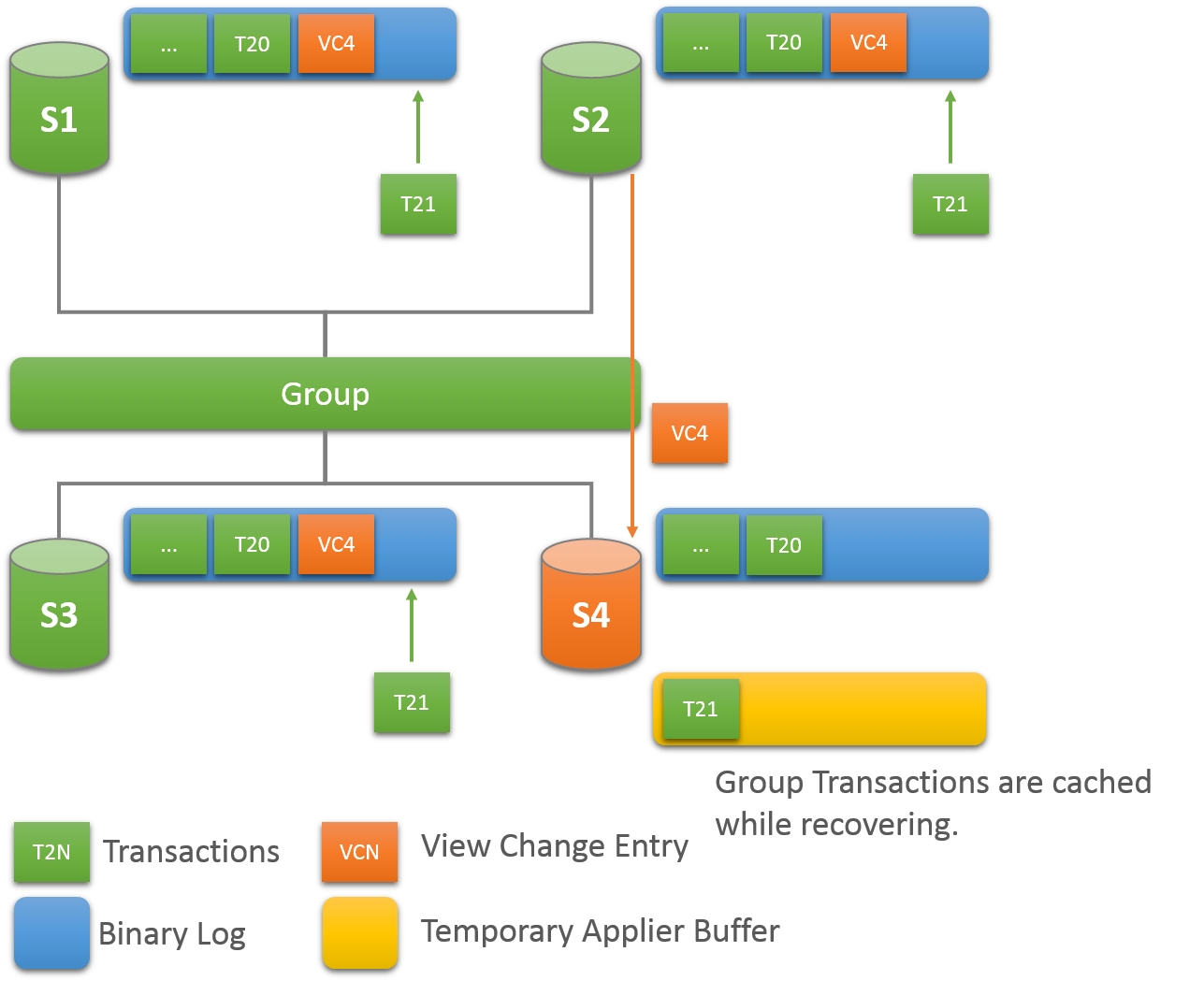
When the server joining the group recognizes a view change log event with the expected view identifier, the connection to the donor is terminated and it starts applying the cached transactions. An important point to understand is the final recovery procedure. Although it acts as a marker in the binary log, delimiting view changes, the view change log event also plays another role. It conveys the certification information as perceived by all servers when the server joining the group entered the group, in other words the last view change. Without it, the server joining the group would not have the necessary information to be able to certify (detect conflicts) subsequent transactions.
The duration of the catch up (phase 2) is not deterministic, because it depends on the workload and the rate of incoming transactions to the group. This process is completely online and the server joining the group does not block any other server in the group while it is catching up. Therefore the number of transactions the server joining the group is behind when it moves to phase 2 can, for this reason, vary and thus increase or decrease according to the workload.
When the server joining the group reaches zero queued transactions and its stored data is equal to the other members, its public state changes to online.
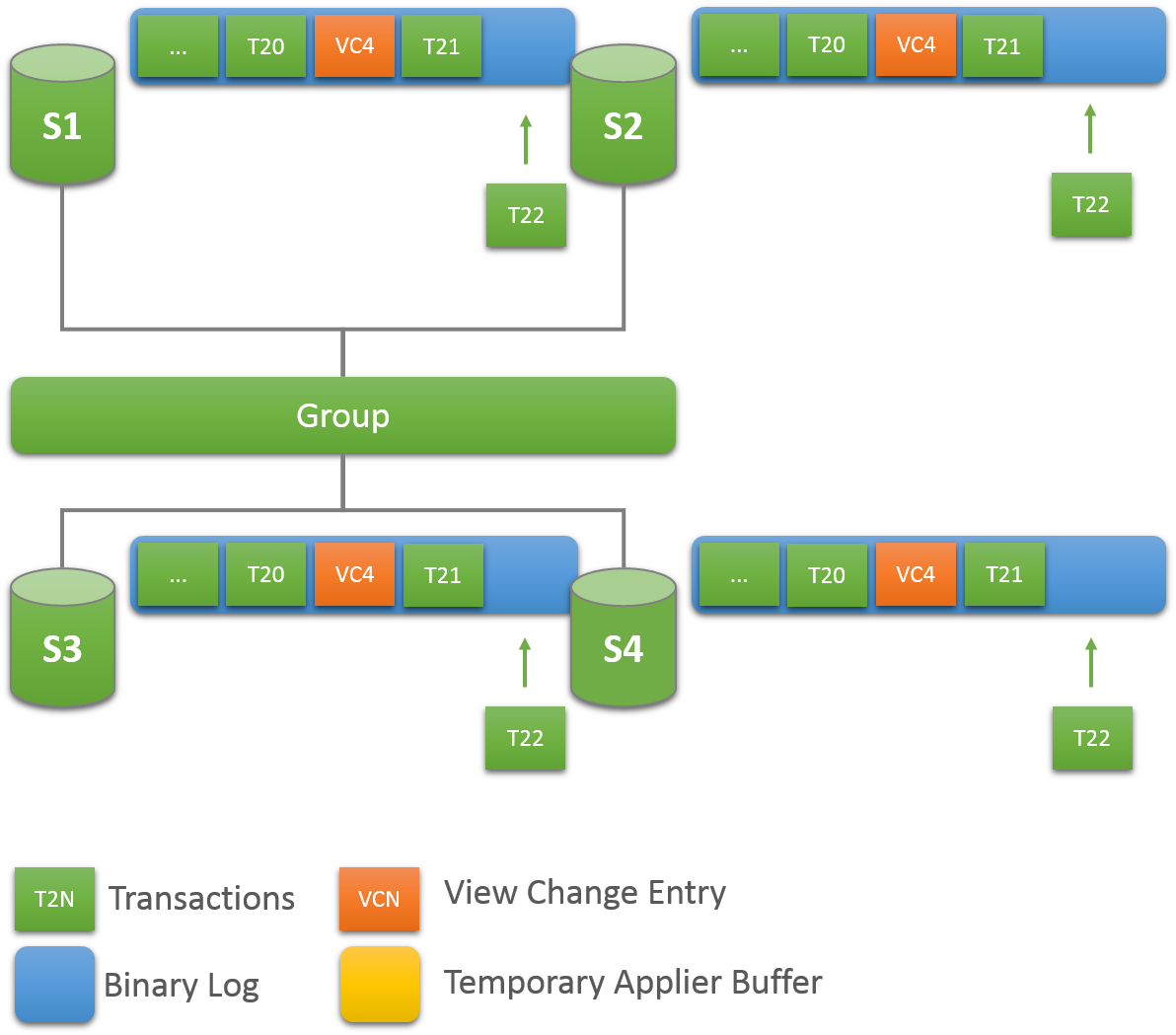
Distributed recovery does have some limitations. It is based on classic asynchronous replication and as such it may be slow if the server joining the group is not provisioned at all or is provisioned with a very old backup image. This means that if the data to transfer is too big at phase 1, the server may take a very long time to recover. As such, the recommendation is that before adding a server to the group, one should provision it with a fairly recent snapshot of a server already in the group. This minimizes the length of phase 1 and reduces the impact on the donor server, since it has to save and transfer less binary logs.
It is recommended that a server is provisioned before it is added to a group. That way, one minimizes the time spent on the recovery step.
There is a lot of automation built into the Group Replication plugin. Nonetheless, you might sometimes need to understand what is happening behind the scenes. This is where the instrumentation of Group Replication and Performance Schema becomes important. The entire state of the system (including the view, conflict statistics and service states) can be queried through performance_schema tables. The distributed nature of the replication protocol and the fact that server instances agree and thus synchronize on transactions and metadata makes it simpler to inspect the state of the group. For example, you can connect to a single server in the group and obtain both local and global information by issuing select statements on the Group Replication related Performance Schema tables. For more information, see Section 18.3, “Monitoring Group Replication”.
This section explains how to use the available configuration options to gain the best performance from your group.
The group communication thread (GCT) runs in a loop while the Group Replication plugin is loaded. The GCT receives messages from the group and from the plugin, handles quorum and failure detection related tasks, sends out some keep alive messages and also handles the incoming and outgoing transactions from/to the server/group. The GCT waits for incoming messages in a queue. When there are no messages, the GCT waits. By configuring this wait to be a little longer (doing an active wait) before actually going to sleep can prove to be beneficial in some cases. This is because the alternative is for the operating system to switch out the GCT from the processor and do a context switch.
To force the GCT to do an active wait, use the
group_replication_poll_spin_loops
option, which makes the GCT loop, doing nothing relevant for the
configured number of loops, before actually polling the queue
for the next message.
For example:
mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
When network bandwidth is a bottleneck, message compression can provide up to 30-40% throughput improvement at the group communication level. This is especially important within the context of large groups of servers under load.
Table 18.5 LZ4 Compression Ratios for Different Binary Log Formats
Workload |
Ratio for ROW |
Ratio for STMT |
|---|---|---|
mysqlslapd |
4,5 |
4,1 |
sysbench |
3,4 |
2,9 |
The TCP peer-to-peer nature of the interconnections between N participants on the group makes the sender send the same amount of data N times. Furthermore, binary logs are likely to exhibit a high compression ratio (see table above). This makes compression a compelling feature for workloads that contain large transaction.
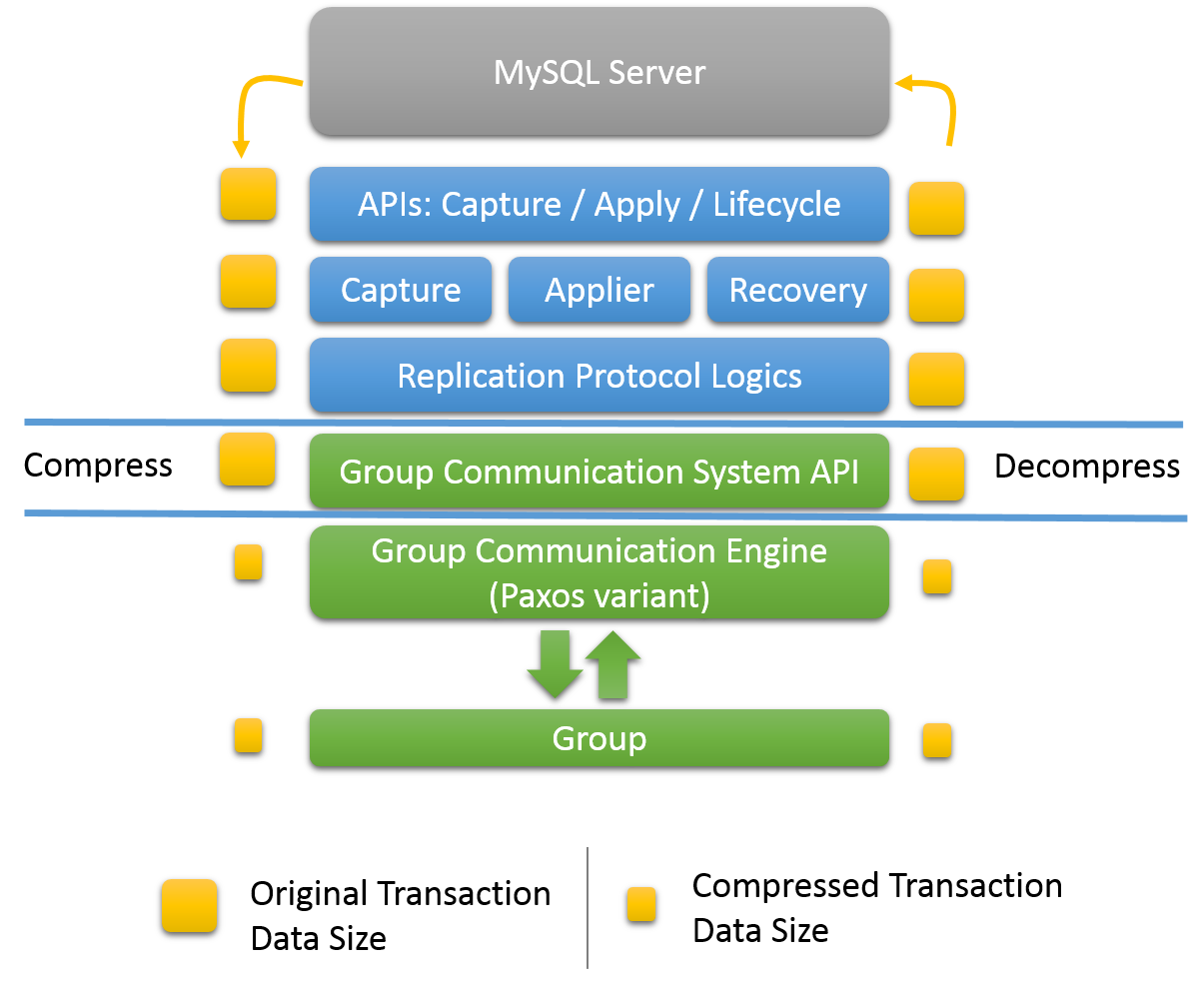
Compression happens at the group communication engine level, before the data is handed over to the group communication thread, so it happens within the context of the mysql user session thread. Transaction payloads may be compressed before being sent out to the group and decompressed when received. Compression is conditional and depends on a configured threshold. By default compression is enabled.
In addition, there is no requirement that all servers in the group have compression enabled to be able to work together. Upon receiving a message, the member checks the message envelope to verify whether it is compressed or not. If needed, then the member decompresses the transaction, before delivering it to the upper layer.
The compression algorithm used is LZ4. Compression is enabled by default with threshold of 1000000 bytes. The compression threshold, in bytes, may be set to something larger than default. In that case, only transactions that have a payload larger than the threshold are compressed. Below is an example of how to set a compression threshold.
STOP GROUP_REPLICATION; SET GLOBAL group_replication_compression_threshold= 2097152; START GROUP_REPLICATION;
This sets the compression threshold to 2MB. If a transaction generates a replication message with a payload larger than 2MB, for example a binary log transaction entry larger than 2MB, then it is compressed. To disable compression set threshold to 0.
Group Replication ensures that a transaction only commits after a majority of the members in a group have received it and agreed on the relative order between all transactions that were sent concurrently.
This approach works well if the total number of writes to the group does not exceed the write capacity of any member in the group. If it does and some of the members have less write throughput than others, particularly less than the writer members, those members can start lagging behind of the writers.
Having some members lagging behind the group brings some problematic consequences, particularly, the reads on such members may externalize very old data. Depending on why the member is lagging behind, other members in the group may have to save more or less replication context to be able to fulfil potential data transfer requests from the slow member.
There is however a mechanism in the replication protocol to avoid having too much distance, in terms of transactions applied, between fast and slow members. This is known as the flow control mechanism. It tries to address several goals:
to keep the members close enough to make buffering and de-synchronization between members a small problem;
to adapt quickly to changing conditions like different workloads or more writers in the group;
to give each member a fair share of the available write capacity;
to not reduce throughput more than strictly necessary to avoid wasting resources.
Given the design of Group Replication, the decision whether to throttle or not may be decided taking into account two work queues: (i) the certification queue; (ii) and on the binary log applier queue. Whenever the size of one of these queues exceeds the user-defined threshold, the throttling mechanism is triggered. Only configure: (i) whether to do flow control at the certifier or at the applier level, or both; and (ii) what is the threshold for each queue.
The flow control depends on two basic mechanisms:
the monitoring of members to collect some statistics on throughput and queue sizes of all group members to make educated guesses on what is the maximum write pressure each member should be subjected to;
the throttling of members that are trying to write beyond their fair-share of the available capacity at each moment in time.
The monitoring mechanism works by having each member deploying a set of probes to collect information about its work queues and throughput. It then propagates that information to the group periodically to share that data with the other members.
Such probes are scattered throughout the plugin stack and allow one to establish metrics, such as:
the certifier queue size;
the replication applier queue size;
the total number of transactions certified;
the total number of remote transactions applied in the member;
the total number of local transactions.
Once a member receives a message with statistics from another member, it calculates additional metrics regarding how many transactions were certified, applied and locally executed in the last monitoring period.
Monitoring data is shared with others in the group periodically. The monitoring period must be high enough to allow the other members to decide on the current write requests, but low enough that it has minimal impact on group bandwidth. The information is shared every second, and this period is sufficient to address both concerns.
Based on the metrics gathered across all servers in the group, a throttling mechanism kicks in and decides whether to limit the rate a member is able to execute/commit new transactions.
Therefore, metrics acquired from all members are the basis for calculating the capacity of each member: if a member has a large queue (for certification or the applier thread), then the capacity to execute new transactions should be close to ones certified or applied in the last period.
The lowest capacity of all the members in the group determines the real capacity of the group, while the number of local transactions determines how many members are writing to it, and, consequently, how many members should that available capacity be shared with.
This means that every member has an established write quota based on the available capacity, in other words a number of transactions it can safely issue for the next period. The writer-quota will be enforced by the throttling mechanism if the queue size of the certifier or the binary log applier exceeds a user-defined threshold.
The quota is reduced by the number of transactions that were delayed in the last period, and then also further reduced by 10% to allow the queue that triggered the problem to reduce its size. In order to avoid large jumps in throughput once the queue size goes beyond the threshold, the throughput is only allowed to grow by the same 10% per period after that.
The current throttling mechanism does not penalize transactions below quota, but delays finishing those transactions that exceed it until the end of the monitoring period. As a consequence, if the quota is very small for the write requests issued some transactions may have latencies close to the monitoring period.