Overview
This section discusses how messages and the Neo4j type system are represented by the protocol using a custom binary serialization format.
For details on the layout and meaning of specific messages, see messaging.
Types overview
| Type | Description |
|---|---|
Represents the absence of a value | |
Boolean true or false | |
64-bit signed integer | |
64-bit floating point number | |
Unicode string | |
Ordered collection of values | |
Unordered, keyed collection of values | |
A node in the graph with optional properties and labels | |
A directed, typed connection between two nodes. Each relationship may have properties and always has an identity | |
The record of a directed walk through the graph, a sequence of zero or more segments*. A path with zero segments consists of a single node. |
| Note A segment is the record of a single step traversal through a graph, encompassing a start node, a relationship traversed either forwards or backwards and an end node. |
Markers
Every value begins with a marker byte. The marker contains information on data type as well as direct or indirect size information for those types that require it. How that size information is encoded varies by marker type.
Some values, such as true, can be encoded within a single marker byte and many small integers (specifically between -16 and +127) are also encoded within a single byte.
A number of marker bytes are reserved for future expansion of the format itself. These bytes should not be used, and encountering them in a stream should treated as an error.
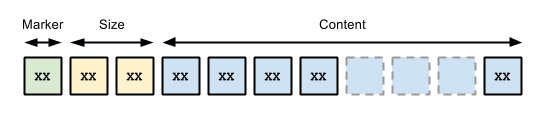
Sized Values
Some value types require variable length representations and, as such, have their size explicitly encoded. These values generally begin with a single marker byte followed by a size followed by the data content itself. Here, the marker denotes both type and scale and therefore determines the number of bytes used to represent the size of the data. The size itself is either an 8-bit, 16-bit or 32-bit big-endian unsigned integer.
The diagram below illustrates the general layout for a sized value, here with a 16-bit size:
Null
Null is always encoded using the single marker byte 0xC0.
Absence of value - null
Value: null C0
Booleans
Boolean values are encoded within a single marker byte, using 0xC3 to denote true and 0xC2 to denote false.
Boolean true
Value: true C3
Boolean false
Value: false C2
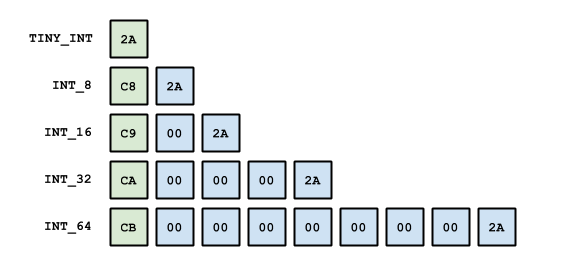
Integers
Integer values occupy either 1, 2, 3, 5 or 9 bytes depending on magnitude and are stored as big-endian signed values.
Several markers are designated specifically as TINY_INT values and can therefore be used to pass a small number in a single byte.
These markers can be identified by a zero high-order bit or by a high-order nibble containing only ones.
The available encodings are illustrated below and each shows a valid representation for the decimal value 42, with marker bytes in green:
Note that while encoding small numbers in wider formats is supported, it is generally recommended to use the most compact representation possible. The following table shows the optimal representation for every possible integer:
Simple integer
Value: 1 01
Min integer
Value: -9223372036854775808 CB 80 00 00 00 00 00 00 00
Max integer
Value: 9223372036854775807 CB 7F FF FF FF FF FF FF FF
Suggested integer representations
| Range Minimum | Range Maximum | Suggested representation |
|---|---|---|
-9 223 372 036 854 775 808 | -2 147 483 649 |
|
-2 147 483 648 | -32 769 |
|
-32 768 | -129 |
|
-128 | -17 |
|
-16 | +127 |
|
+128 | +32 767 |
|
+32 768 | +2 147 483 647 |
|
+2 147 483 648 | +9 223 372 036 854 775 807 |
|
Floating Point Numbers
These are double-precision floating points for approximations of any number, notably for representing fractions and decimal numbers.
Floats are encoded as a single 0xC1 marker byte followed by 8 bytes, formatted according to the IEEE 754 floating-point "double format" bit layout.
Bit 63 (the bit that is selected by the mask 0x8000000000000000) represents the sign of the number.
Bits 62-52 (the bits that are selected by the mask 0x7ff0000000000000) represent the exponent.
Bits 51-0 (the bits that are selected by the mask 0x000fffffffffffff) represent the significand (sometimes called the mantissa) of the number.
Simple floating point
Value: 1.1 C1 3F F1 99 99 99 99 99 9A
Negative floating point
Value: -1.1 C1 BF F1 99 99 99 99 99 9A
String
String data is represented as UTF-8 encoded binary data. Note that sizes used for string are the byte counts of the UTF-8 encoded data, not the character count of the original string.
String markers
| Marker | Size | Maximum data size |
|---|---|---|
| contained within low-order nibble of marker | 15 bytes |
| 8-bit unsigned integer | 255 bytes |
| 16-bit big-endian unsigned integer | 65 535 bytes |
| 32-bit big-endian unsigned integer | 4 294 967 295 bytes |
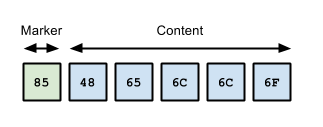
Tiny Strings & Empty Strings
For encoded string containing fewer than 16 bytes, including empty strings, the marker byte should contain the high-order nibble 1000 followed by a low-order nibble containing the size.
The encoded data then immediately follows the marker.
The example below shows how the string "Hello" would be represented:
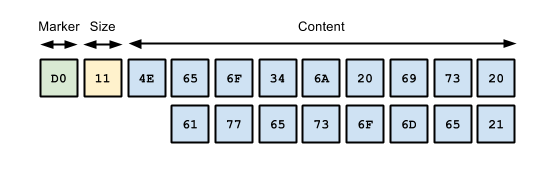
Regular Strings
For encoded string containing 16 bytes or more, the marker 0xD0, 0xD1 or 0xD2 should be used, depending on scale.
This marker is followed by the size and the UTF-8 encoded data as in the example below:
Examples
Tiny string
Value: "a" 81 61
Regular string
Value: "abcdefghijklmnopqrstuvwxyz" D0 1A 61 62 63 64 65 66 67 68 69 6A 6B 6C 6D 6E 6F 70 71 72 73 74 75 76 77 78 79 7A
String with special characters
Value: "En å flöt över ängen" D0 18 45 6E 20 C3 A5 20 66 6C C3 B6 74 20 C3 B6 76 65 72 20 C3 A4 6E 67 65 6E
Lists
Lists are heterogeneous sequences of values and permit a mixture of types within the same list. The size of a list denotes the number of items within that list, not the total packed byte size. The markers used to denote a list are described in the table below:
List markers
| Marker | Size | Maximum list size |
|---|---|---|
| contained within low-order nibble of marker | 15 bytes |
| 8-bit unsigned integer | 255 items |
| 16-bit big-endian unsigned integer | 65 535 items |
| 32-bit big-endian unsigned integer | 4 294 967 295 items |
Tiny Lists & Empty Lists
For lists containing fewer than 16 items, including empty lists, the marker byte should contain the high-order nibble 1001 followed by a low-order nibble containing the size.
The items within the list are then serialised in order immediately after the marker.
Regular Lists
For lists containing 16 items or more, the marker 0xD4, 0xD5 or 0xD6 should be used, depending on scale.
This marker is followed by the size and list items, serialized in order.
Examples
Empty list
Value: [] 90
Tiny list
Value: [1,2,3] 93 01 02 03
Regular list
Value: [1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0] D4 14 01 02 03 04 05 06 07 08 09 00 01 02 03 04 05 06 07 08 09 00
Maps
Maps are sized sequences of pairs of keys and values and permit a mixture of types within the same map. The size of a map denotes the number of pairs within that map, not the total packed byte size. Keys are unique within a map, however the serialization format notably technically allows duplicate keys to be sent. Though if duplicate keys are sent, this is a violation of the bolt protocol and an error will occur. The markers used to denote a map are described in the table below:
Map markers
| Marker | Size | Maximum map size |
|---|---|---|
| contained within low-order nibble of marker | 15 entries |
| 8-bit unsigned integer | 255 entries |
| 16-bit big-endian unsigned integer | 65 535 entries |
| 32-bit big-endian unsigned integer | 4 294 967 295 entries |
Tiny Maps & Empty Maps
For maps containing fewer than 16 key-value pairs, including empty maps, the marker byte should contain the high-order nibble 1010 followed by a low-order nibble containing the size.
The items within the map are then serialised in key-value-key-value order immediately after the marker.
Regular Maps
For maps containing 16 pairs or more, the marker 0xD8, 0xD9 or 0xDA should be used, depending on scale.
This marker is followed by the size and map entries, serialised in key-value-key-value order.
Examples
Empty map
Value: {}
A0
Tiny map
Value: {"a":1}
A1 81 61 01
Regular map
Value: {"a":1,"b":1,"c":3,"d":4,"e":5,"f":6,"g":7,"h":8,"i":9,"j":0,"k":1,"l":2,"m":3,"n":4,"o":5,"p":6}
D8 10 81 61 01 81 62 01 81 63 03 81 64 04 81 65
05 81 66 06 81 67 07 81 68 08 81 69 09 81 6A 00
81 6B 01 81 6C 02 81 6D 03 81 6E 04 81 6F 05 81
70 06
Structures
Structures represent composite values and consist, beyond the marker, of a single byte signature followed by a sequence of fields, each an individual value. The size of a structure is measured as the number of fields, not the total packed byte size. The markers used to denote a structure are described in the table below:
Structure markers
| Marker | Size | Maximum structure size |
|---|---|---|
| contained within low-order nibble of marker | 15 fields |
| 8-bit unsigned integer | 255 fields |
| 16-bit big-endian unsigned integer | 65 535 fields |
Signature
The signature byte is used to identify the type or class of the structure. Refer to the Value Structures and Message Structures for structures used in the protocol.
Signature bytes may hold any value between 0 and +127. Bytes with the high bit set are reserved for future expansion.
Tiny Structures
For structures containing fewer than 16 fields, the marker byte should contain the high-order nibble 1011 followed by a low-order nibble containing the size.
The marker is immediately followed by the signature byte and the field values.
Regular Structures
For structures containing 16 fields or more, the marker 0xDC or 0xDD should be used, depending on scale.
This marker is followed by the size, the signature byte and the actual fields, serialised in order.
Examples
Assuming a struct with the signature 0x01 and three fields with values 1,2,3:
Tiny structure
Value: Struct (signature=0x01) { 1,2,3 }
B3 01 01 02 03
Regular structure
Value: Struct (signature=0x01) { 1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6 }
DC 10 01 01 02 03 04 05 06 07 08 09 00 01 02 03
04 05 06
Graph Type Stuctures
A number of key Neo4j types are represented as structures. These include nodes, relationships and paths.
Node
A Node represents a node from a Neo4j graph and consists of a unique identifier (within the scope of its origin graph), a list of labels and a map of properties. The general serialised structure is as follows:
Node (signature=0x4E) {
Integer nodeIdentity
List<String> labels
Map<String, Value> properties
}
Relationship
A Relationship represents a relationship from a Neo4j graph and consists of a unique identifier (within the scope of its origin graph), identifiers for the start and end nodes of that relationship, a type and a map of properties. The general serialised structure is as follows:
Relationship (signature=0x52) {
Integer relIdentity
Integer startNodeIdentity
Integer endNodeIdentity
String type
Map<String, Value> properties
}
Path
A Path is a sequence of alternating nodes and relationships corresponding to a walk in the graph. The path always begins and ends with a node. Its representation consists of a list of distinct nodes, a list of distinct relationships and a sequence of integers describing the path traversal. The general serialised structure is as follows:
Path (signature=0x50) {
List<Node> nodes
List<UnboundRelationship> relationships
List<Integer> sequence
}
The two lists N and R (short for nodes and relationships in the example above) are defined as follows:
-
Ncontains all the unique nodes in the path -
Rcontains all the unique relationships in the path -
For
N, the index is an integer commencing with 0 and incrementing by 1 -
For
R, the index is an integer commencing with 1 and incrementing by 1 -
The value component for both
NandRis the data corresponding to the node or relationship; this comprises the identifier, labels/type, properties etc -
In
N, the first element must always be the first node in the path (thus having 0 as the index) -
No other explicit rules apply as to either (i) the ordering of the other nodes in
N, or (ii) the ordering of any of the relationships inR. However, while not required, it is recommended that implementations aim to list entities (i.e. nodes and relationships) in the order in which they are first encountered while traversing the path. This may help with the efficiency of reading and writing
When transmitting a path between a server and a client, the path is represented as a sequence of integers; we define S (short for sequence in the example above) as the transmitted sequence, and S' as the full sequence.
-
Smust always consist of an even number of integers, or be empty -
The first, third, … integer in
Shas a range encompassed by (..,-1] and [1,..). These represent the directed relationships in the path -
The second, fourth, … integer in
Shas a range encompassed by [0,..). These represent the nodes in the path -
By definition, the first node in the path will always have an index of 0, so we exclude this from
Supon transmission. The idea is to constructS'by prepending 0 toSon the completion of a successful transmission -
Let a path
Pbe given by the following transmitted sequence [1, 1, -2, 2]. It follows that the corresponding full sequence,S', is given by [0, 1, 1, -2, 2] -
The first integer in
S(1) is the index inRcorresponding to the first relationship inP -
The second integer in
S(1) is the index inNcorresponding to the second node inP -
The last integer in
S(2) is the index inNcorresponding to the last node inP -
When a relationship is represented by a positive integer in
S- such as the 1 in position 1 - this means that the relationship is being traversed in the direction of the underlying relationship in the data graph -
When a relationship is represented by a negative integer in
S- such as the -2 in position 3 - this means that the relationship is being traversed against the direction of the underlying relationship in the data graph. For loops - i.e. a relationship beginning and ending at the same node - a positive integer should be used
Example Consider the following path:
(A)-[:X]->(B)-[:Y]->(C)<-[:Z]-(B)<-[:X]-(A)
The elements transmitted would be as follows:
-
N:(A),(B),(C) -
R:[:X],[:Y],[:Z] -
S: [1, 1, 2, 2, -3, 1, -1, 0]
By definition, the following is also implied:
-
S': [0, 1, 1, 2, 2, -3, 1, -1, 0]
Similarly, consider the following zero-length path:
(A)
The elements transmitted would be as follows:
-
N:(A) -
R: <empty> -
S: <empty>
where the following is implied:
-
S': [0]
UnboundRelationship
An UnboundRelationship represents a relationship relative to a separately known start point and end point. The general serialised structure is as follows:
UnboundRelationship (signature=0x72) {
Integer relIdentity
String type // e.g. "KNOWS"
Map<String, Value> properties // e.g. {since:1999}
}
Marker table
These are all the marker bytes:
Marker table
| Marker | Binary | Type | Description |
|---|---|---|---|
|
|
| Integer 0 to 127 |
|
|
| UTF-8 encoded string (fewer than 24 bytes) |
|
|
| List (fewer than 24 items) |
|
|
| Map (fewer than 24 key-value pairs) |
|
|
| Structure (fewer than 24 fields) |
|
|
| Null |
|
|
| 64-bit floating point number (double) |
|
|
| Boolean false |
|
|
| Boolean true |
|
| Reserved | |
|
|
| 8-bit signed integer |
|
|
| 16-bit signed integer |
|
|
| 32-bit signed integer |
|
|
| 64-bit signed integer |
|
| Reserved | |
|
|
| UTF-8 encoded string (fewer than 28 bytes) |
|
|
| UTF-8 encoded string (fewer than 216 bytes) |
|
|
| UTF-8 encoded string (fewer than 232 bytes) |
|
| Reserved | |
|
|
| List (fewer than 28 items) |
|
|
| List (fewer than 216 items) |
|
|
| List (fewer than 232 items) |
|
| Reserved | |
|
|
| Map (fewer than 28 key-value pairs) |
|
|
| Map (fewer than 216 key-value pairs) |
|
|
| Map (fewer than 232 key-value pairs) |
|
| Reserved | |
|
|
| Structure (fewer than 28 fields) |
|
|
| Structure (fewer than 216 fields) |
|
| Reserved | |
|
|
| Integer -1 to -16 |