blocksparse – Block sparse dot operations (gemv and outer)¶
-
class
theano.tensor.nnet.blocksparse.SparseBlockGemv(inplace=False)¶ This op computes the dot product of specified pieces of vectors and matrices, returning pieces of vectors:
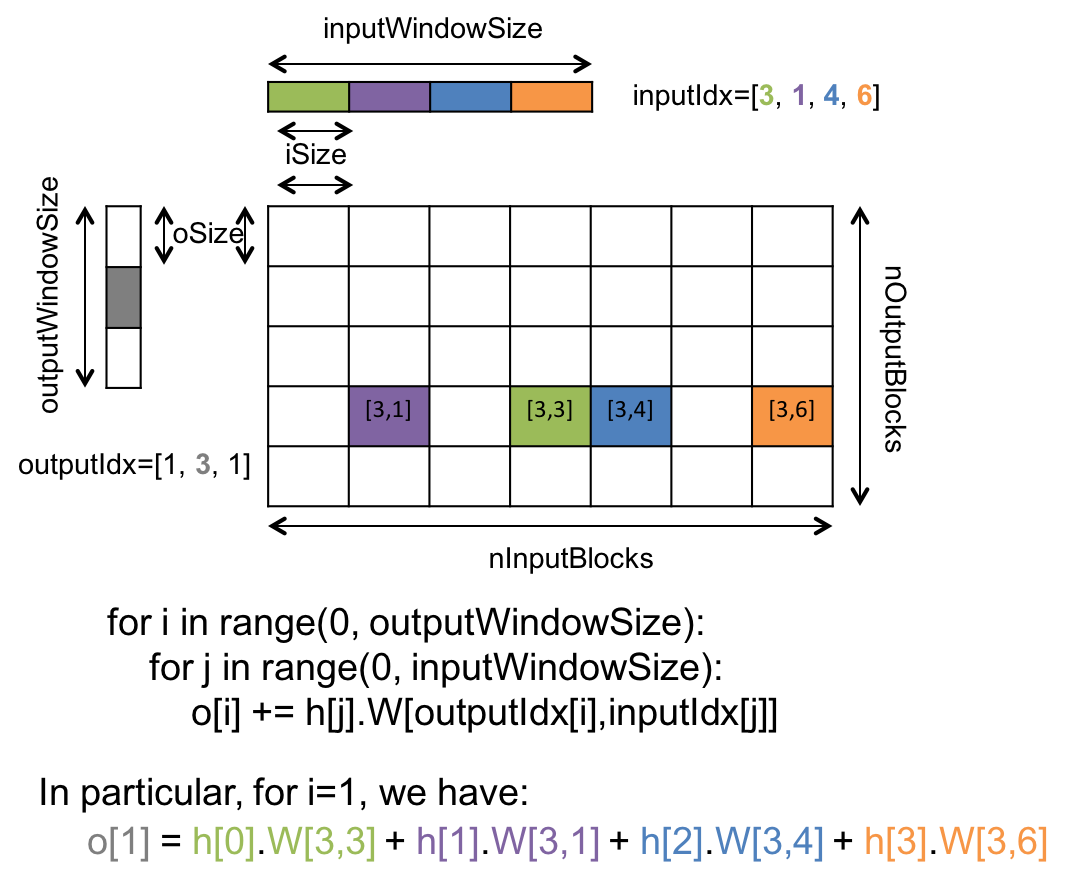
for b in range(batch_size): for j in range(o.shape[1]): for i in range(h.shape[1]): o[b, j, :] += numpy.dot(h[b, i], W[iIdx[b, i], oIdx[b, j]])
where b, h, W, o iIdx, oIdx are defined in the docstring of make_node.
-
make_node(o, W, h, inputIdx, outputIdx)¶ Compute the dot product of the specified pieces of vectors and matrices.
The parameter types are actually their expected shapes relative to each other.
Parameters: - o (batch, oWin, oSize) – output vector
- W (iBlocks, oBlocks, iSize, oSize) – weight matrix
- h (batch, iWin, iSize) – input from lower layer (sparse)
- inputIdx (batch, iWin) – indexes of the input blocks
- outputIdx (batch, oWin) – indexes of the output blocks
Returns: dot(W[i, j], h[i]) + o[j]
Return type: (batch, oWin, oSize)
Notes
batch is the number of examples in a minibatch (batch size).
- iBlocks is the total number of blocks in the input (from lower
layer).
iSize is the size of each of these input blocks.
- iWin is the number of blocks that will be used as inputs. Which
blocks will be used is specified in inputIdx.
oBlocks is the number or possible output blocks.
oSize is the size of each of these output blocks.
- oWin is the number of output blocks that will actually be computed.
Which blocks will be computed is specified in outputIdx.
-
-
class
theano.tensor.nnet.blocksparse.SparseBlockOuter(inplace=False)¶ This computes the outer product of two sets of pieces of vectors updating a full matrix with the results:
for b in range(batch_size): o[xIdx[b, i], yIdx[b, j]] += (alpha * outer(x[b, i], y[b, j]))
This op is involved in the gradient of SparseBlockGemv.
-
make_node(o, x, y, xIdx, yIdx, alpha=None)¶ Compute the dot product of the specified pieces of vectors and matrices.
The parameter types are actually their expected shapes relative to each other.
Parameters: - o (xBlocks, yBlocks, xSize, ySize) –
- x (batch, xWin, xSize) –
- y (batch, yWin, ySize) –
- xIdx (batch, iWin) – indexes of the x blocks
- yIdx (batch, oWin) – indexes of the y blocks
Returns: outer(x[i], y[j]) + o[i, j]
Return type: (xBlocks, yBlocks, xSize, ySize)
Notes
- batch is the number of examples in a minibatch (batch size).
- xBlocks is the total number of blocks in x.
- xSize is the size of each of these x blocks.
- xWin is the number of blocks that will be used as x. Which blocks will be used is specified in xIdx.
- yBlocks is the number or possible y blocks.
- ySize is the size of each of these y blocks.
- yWin is the number of y blocks that will actually be computed. Which blocks will be computed is specified in yIdx.
-
-
theano.tensor.nnet.blocksparse.sparse_block_dot(W, h, inputIdx, b, outputIdx)¶ Compute the dot product (plus bias) of the specified pieces of vectors and matrices. See SparseBlockGemv to get more information.
The parameter types are actually their expected shapes relative to each other.
Parameters: - W (iBlocks, oBlocks, iSize, oSize) – weight matrix
- h (batch, iWin, iSize) – input from lower layer (sparse)
- inputIdx (batch, iWin) – indexes of the input blocks
- b (oBlocks, oSize) – bias vector
- outputIdx (batch, oWin) – indexes of the output blocks
Returns: dot(W[i, j], h[i]) + b[j] but b[j] is only added once
Return type: (batch, oWin, oSize)
Notes
batch is the number of examples in a minibatch (batch size).
iBlocks is the total number of blocks in the input (from lower layer).
iSize is the size of each of these input blocks.
- iWin is the number of blocks that will be used as inputs. Which blocks
will be used is specified in inputIdx.
oBlocks is the number or possible output blocks.
oSize is the size of each of these output blocks.
- oWin is the number of output blocks that will actually be computed.
Which blocks will be computed is specified in outputIdx.