
 HTML Overview¶
HTML Overview¶The wx.html library provides classes for parsing and displaying HTML.
It is not intended to be a high-end HTML browser. If you are looking for something like that try http://www.mozilla.org/.
wxhtml can be used as a generic rich text viewer - for example
to display a nice About Box (like those of GNOME apps) or to display
the result of database searching. There is a wx.FileSystem
class which allows you to use your own virtual file systems.
HtmlWindow supports tag handlers. This means that
you can easily extend html library with new, unsupported
tags. Not only that, you can even use your own application-specific
tags!
There is a generic HtmlParser class, independent of
HtmlWindow.
Class HtmlWindow (derived from
wx.ScrolledWindow) is used to display HTML documents.
It has two important methods: LoadPage and
SetPage. LoadPage loads and displays HTML
file while SetPage displays directly the passed string. See the
example:
mywin.LoadPage("test.htm")
mywin.SetPage("htmlbody" \
"h1Error/h1" \
"Some error occurred :-H)" \
"/body/hmtl")
Because HtmlWindow is derived from
wx.ScrolledWindow and not from wx.Frame, it doesn’t
have visible frame. But the user usually wants to see the title of
HTML page displayed somewhere and the frame’s titlebar is the ideal
place for it.
HtmlWindow provides 2 methods in order to handle
this: SetRelatedFrame and
SetRelatedStatusBar. See the example:
html = wx.html.HtmlWindow(self)
html.SetRelatedFrame(self, "HTML : %%s")
html.SetRelatedStatusBar(0)
The first command associates the HTML object with its parent frame
(this points to wx.Frame object there) and sets the format of
the title. Page title “Hello, world!” will be displayed as “HTML :
Hello, world!” in this example.
The second command sets which frame’s status bar should be used to display browser’s messages (such as “Loading...” or “Done” or hypertext links).
You can customize HtmlWindow by setting font size,
font face and borders (space between border of window and displayed
HTML). Related functions:
SetFontsSetBordersReadCustomizationWriteCustomizationThe last two functions are used to store user customization info
wx.ConfigBase stuff (for example in the registry under
Windows, or in a dotfile under Unix).
The wx.html library provides printing facilities with several
levels of complexity. The easiest way to print an HTML document is to
use the HtmlEasyPrinting class.
It lets you print HTML documents with only one command and you don’t
have to worry about deriving from the wx.Printout class at
all. It is only a simple wrapper around the
HtmlPrintout, normal wxPython printout class.
And finally there is the low level class
HtmlDCRenderer which you can use to render HTML into
a rectangular area on any DC.
It supports rendering into multiple rectangles with the same width. (The most common use of this is placing one rectangle on each page or printing into two columns.)
wx.html library can be used to show an help manual to the user; in
fact, it supports natively (through HtmlHelpController)
a reduced version of MS HTML Workshop format.
A book consists of three files: the header file, the contents file and the index file.
You can make a regular zip archive of these files, plus the HTML and any
image files, for HTML (or helpview) to read; and the ".zip" file can
optionally be renamed to ".htb".
The header file must contain these lines (and may contain additional lines which are ignored):
Contents file=filename.hhc
Index file=filename.hhk
Title=title of your book
Default topic=default page to be displayed.htm
All filenames (including the Default topic) are relative to the location of
the ".hhp" file.
Note
For localization, in addition the ".hhp" file may contain the line:
Charset=rfc_charset
which specifies what charset (e.g. “iso8859_1”) was used in contents and index files. Please note that this line is incompatible with MS HTML Help Workshop and it would either silently remove it or complain with some error.
Contents file has HTML syntax and it can be parsed by regular HTML parser. It
contains exactly one list (<ul> ... </ul> statement):
<ul>
<li><object type="text/sitemap">
<param name="Name" value="@topic name@">
<param name="ID" value=@numeric_id@>
<param name="Local" value="@filename.htm@">
</object></li>
<li><object type="text/sitemap">
<param name="Name" value="@topic name@">
<param name="ID" value=@numeric_id@>
<param name="Local" value="@filename.htm@">
</object></li>
</ul>
You can modify value attributes of param tags. The topic name is name of
chapter/topic as is displayed in contents, filename.htm is the HTML page
name (relative to the ".hhp" file) and numeric_id is optional - it is
used only when you use Display.
Items in the list may be nested - one <li> statement may contain a
<ul> sub-statement:
<ul>
<li><object type="text/sitemap">
<param name="Name" value="Top node">
<param name="Local" value="top.htm">
</object></li>
<ul>
<li><object type="text/sitemap">
<param name="Name" value="subnode in
topnode">
<param name="Local" value="subnode1.htm">
</object></li>
</ul>
<li><object type="text/sitemap">
<param name="Name" value="Another Top">
<param name="Local" value="top2.htm">
</object></li>
</ul>
Index files have same format as contents files except that ID params are ignored and sublists are not allowed.
The wx.html library provides a mechanism for reading and displaying files of
many different file formats.
LoadPage can load not only HTML files but any known file. To
make a file type known to HtmlWindow you must create a HtmlFilter
filter and register it using AddFilter.
This article describes mechanism used by HtmlWinParser and
HtmlWindow to parse and display HTML documents.
You can divide any text (or HTML) into small fragments. Let’s call these
fragments cells. Cell is for example one word, horizontal line, image or
any other part of document. Each cell has width and height (except special
“magic” cells with zero dimensions - e.g. colour changers or font changers).
See HtmlCell.
Container is kind of cell that may contain sub-cells. Its size depends on
number and sizes of its sub-cells (and also depends on width of window). See
HtmlContainerCell, Layout. This image shows the cells and
containers:

HtmlWinParser provides a user-friendly way of managing containers. It is
based on the idea of opening and closing containers.
Use OpenContainer to open new a container within an
already opened container. This new container is a sub-container of the old
one. (If you want to create a new container with the same depth level you can
call CloseContainer(); OpenContainer(); ).
Use CloseContainer to close the container. This doesn’t
create a new container with same depth level but it returns “control” to the
parent container. See explanation:
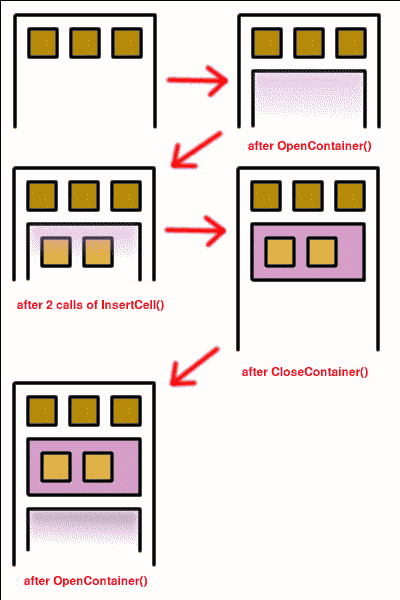
There clearly must be same number of calls to OpenContainer as to CloseContainer.
This code creates a new paragraph (container at same depth level) with “Hello, world!”:
myParser.CloseContainer()
c = myParser.OpenContainer()
myParser.AddText("Hello, ")
myParser.AddText("world!")
myParser.CloseContainer()
myParser.OpenContainer()
and here is image of the situation:
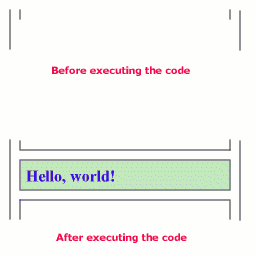
You can see that there was an opened container before the code was executed. We closed it, created our own container, then closed our container and opened new container.
The result was that we had same depth level after executing. This is
general rule that should be followed by tag handlers: leave depth level of
containers unmodified (in other words, number of OpenContainer and
CloseContainer calls should be same within HandleTag ‘s
body).
Note
Notice that it would be usually better to use
InsertCell instead of adding text to the parser
directly.
The wx.html library provides architecture of pluggable tag handlers. Tag
handler is class that understands particular HTML tag (or tags) and is able
to interpret it.
HtmlWinParser has a static table of modules. Each module contains
one or more tag handlers. Each time a new HtmlWinParser object is
constructed all modules are scanned and handlers are added to HtmlParser’s
list of available handlers.
Common tag handler’s HandleTag method works in four
steps:
See HtmlWinParser for methods for modifying parser’s state. In general
you can do things like opening/closing containers, changing colors, fonts etc...
See the wx.lib.wxpTag on how to provide your own tag handlers.
The handler is derived from HtmlWinTagHandler (or directly from
HtmlTagHandler).
html¶wx.html is not a full implementation of HTML standard. Instead, it supports most
common tags so that it is possible to display simple HTML documents with
it. (For example it works fine with pages created in Netscape Composer or
generated by tex2rtf).
Following tables list all tags known to wx.html, together with supported
parameters.
A tag has general form of tagname param_1 param_2 ... param_n where
param_i is either paramname="paramvalue" or paramname=paramvalue -
these two are equivalent. Unless stated otherwise, wx.html is case-
insensitive.
We will use these substitutions in tags descriptions:
| [alignment] | CENTER |
| LEFT | |
| RIGHT | |
| JUSTIFY | |
| [v_alignment] | TOP |
| BOTTOM | |
| CENTER | |
| [color] | HTML 4.0-compliant colour specification |
| [fontsize] | -2 |
| -1 | |
| +0 | |
| +1 | |
| +2 | |
| +3 | |
| +4 | |
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| [pixels] | integer value that represents dimension in pixels |
| [percent] | i% |
| where i is integer | |
| [url] | an URL |
| [string] | text string |
| [coords] | c(1),c(2),c(3),...,c(n) |
| where c(i) is integer |
| A | NAME=[string] |
| HREF=[url] | |
| TARGET=[target window spec] | |
| ADDRESS | |
| AREA | SHAPE=POLY |
| SHAPE=CIRCLE | |
| SHAPE=RECT | |
| COORDS=[coords] | |
| HREF=[url] | |
| BIG | |
| BLOCKQUOTE | |
| BODY | TEXT=[color] |
| LINK=[color] | |
| BGCOLOR=[color] | |
| BR | ALIGN=[alignment] |
| CENTER | |
| CITE | |
| CODE | |
| DD | |
| DIV | ALIGN=[alignment] |
| DL | |
| DT | |
| EM | |
| FONT | COLOR=[color] |
| SIZE=[fontsize] | |
| FACE=[comma-separated list of facenames] | |
| HR | ALIGN=[alignment] |
| SIZE=[pixels] | |
| WIDTH=[percent|pixels] | |
| NOSHADE | |
| H1 | |
| H2 | |
| H3 | |
| H4 | |
| H5 | |
| H6 | |
| I | |
| IMG | SRC=[url] |
| WIDTH=[percent|pixels] | |
| HEIGHT=[pixels] | |
| ALIGN=TEXTTOP | |
| ALIGN=CENTER | |
| ALIGN=ABSCENTER | |
| ALIGN=BOTTOM | |
| USEMAP=[url] | |
| KBD | |
| LI | |
| MAP | NAME=[string] |
| META | HTTP-EQUIV=”Content-Type” |
| CONTENT=[string] | |
| OL | |
| P | ALIGN=[alignment] |
| PRE | |
| SAMP | |
| SMALL | |
| SPAN | |
| STRIKE | |
| STRONG | |
| SUB | |
| SUP | |
| TABLE | ALIGN=[alignment] |
| WIDTH=[percent|pixels] | |
| BORDER=[pixels] | |
| VALIGN=[v_alignment] | |
| BGCOLOR=[color] | |
| CELLSPACING=[pixels] | |
| CELLPADDING=[pixels] | |
| TD | ALIGN=[alignment] |
| VALIGN=[v_alignment] | |
| BGCOLOR=[color] | |
| WIDTH=[percent|pixels] | |
| COLSPAN=[pixels] | |
| ROWSPAN=[pixels] | |
| NOWRAP | |
| TH | ALIGN=[alignment] |
| VALIGN=[v_alignment] | |
| BGCOLOR=[color] | |
| WIDTH=[percent|pixels] | |
| COLSPAN=[pixels] | |
| ROWSPAN=[pixels] | |
| TITLE | |
| TR | ALIGN=[alignment] |
| VALIGN=[v_alignment] | |
| BGCOLOR=[color] | |
| TT | |
| U | |
| UL |
wx.html doesn’t really have CSS support but it does support a few simple
styles: you can use "text-align", "width", "vertical-align" and
"background" with all elements and for SPAN elements a few other
styles are additionally recognized:
colorfont-familyfont-size (only in point units)font-style (only “oblique”, “italic” and “normal” values are supported)font-weight (only “bold” and “normal” values are supported)text-decoration (only “underline” value is supported)
