MLflow Tracking
The MLflow Tracking component is an API and UI for logging parameters, code versions, metrics, and output files when running your machine learning code and for later visualizing the results. MLflow Tracking lets you log and query experiments using Python, REST, R API, and Java API APIs.
Table of Contents
Concepts
MLflow Tracking is organized around the concept of runs, which are executions of some piece of data science code. Each run records the following information:
- Code Version
Git commit hash used for the run, if it was run from an MLflow Project.
- Start & End Time
Start and end time of the run
- Source
Name of the file to launch the run, or the project name and entry point for the run if run from an MLflow Project.
- Parameters
Key-value input parameters of your choice. Both keys and values are strings.
- Metrics
Key-value metrics, where the value is numeric. Each metric can be updated throughout the course of the run (for example, to track how your model’s loss function is converging), and MLflow records and lets you visualize the metric’s full history.
- Artifacts
Output files in any format. For example, you can record images (for example, PNGs), models (for example, a pickled scikit-learn model), and data files (for example, a Parquet file) as artifacts.
You can record runs using MLflow Python, R, Java, and REST APIs from anywhere you run your code. For example, you can record them in a standalone program, on a remote cloud machine, or in an interactive notebook. If you record runs in an MLflow Project, MLflow remembers the project URI and source version.
You can optionally organize runs into experiments, which group together runs for a
specific task. You can create an experiment using the mlflow experiments CLI, with
mlflow.create_experiment(), or using the corresponding REST parameters. The MLflow API and
UI let you create and search for experiments.
Once your runs have been recorded, you can query them using the Tracking UI or the MLflow API.
Where Runs Are Recorded
MLflow runs can be recorded to local files, to a SQLAlchemy compatible database, or remotely
to a tracking server. By default, the MLflow Python API logs runs locally to files in an mlruns directory wherever you
ran your program. You can then run mlflow ui to see the logged runs.
To log runs remotely, set the MLFLOW_TRACKING_URI environment variable to a tracking server’s URI or
call mlflow.set_tracking_uri().
There are different kinds of remote tracking URIs:
Local file path (specified as
file:/my/local/dir), where data is just directly stored locally.Database encoded as
<dialect>+<driver>://<username>:<password>@<host>:<port>/<database>. MLflow supports the dialectsmysql,mssql,sqlite, andpostgresql. For more details, see SQLAlchemy database uri.HTTP server (specified as
https://my-server:5000), which is a server hosting an MLflow tracking server.Databricks workspace (specified as
databricksor asdatabricks://<profileName>, a Databricks CLI profile. See docs on logging to Databricks-hosted MLflow, or the quickstart to easily get started with hosted MLflow on Databricks Community Edition.
Logging Data to Runs
You can log data to runs using the MLflow Python, R, Java, or REST API. This section shows the Python API.
In this section:
Logging Functions
mlflow.set_tracking_uri() connects to a tracking URI. You can also set the
MLFLOW_TRACKING_URI environment variable to have MLflow find a URI from there. In both cases,
the URI can either be a HTTP/HTTPS URI for a remote server, a database connection string, or a
local path to log data to a directory. The URI defaults to mlruns.
mlflow.tracking.get_tracking_uri() returns the current tracking URI.
mlflow.create_experiment() creates a new experiment and returns its ID. Runs can be
launched under the experiment by passing the experiment ID to mlflow.start_run.
mlflow.set_experiment() sets an experiment as active. If the experiment does not exist,
creates a new experiment. If you do not specify an experiment in mlflow.start_run(), new
runs are launched under this experiment.
mlflow.start_run() returns the currently active run (if one exists), or starts a new run
and returns a mlflow.ActiveRun object usable as a context manager for the
current run. You do not need to call start_run explicitly: calling one of the logging functions
with no active run automatically starts a new one.
mlflow.end_run() ends the currently active run, if any, taking an optional run status.
mlflow.active_run() returns a mlflow.entities.Run object corresponding to the
currently active run, if any.
Note: You cannot access currently-active run attributes
(parameters, metrics, etc.) through the run returned by mlflow.active_run. In order to access
such attributes, use the mlflow.tracking.MlflowClient as follows:
client = mlflow.tracking.MlflowClient()
data = client.get_run(mlflow.active_run().info.run_id).data
mlflow.log_param() logs a single key-value param in the currently active run. The key and
value are both strings. Use mlflow.log_params() to log multiple params at once.
mlflow.log_metric() logs a single key-value metric. The value must always be a number.
MLflow remembers the history of values for each metric. Use mlflow.log_metrics() to log
multiple metrics at once.
mlflow.set_tag() sets a single key-value tag in the currently active run. The key and
value are both strings. Use mlflow.set_tags() to set multiple tags at once.
mlflow.log_artifact() logs a local file or directory as an artifact, optionally taking an
artifact_path to place it in within the run’s artifact URI. Run artifacts can be organized into
directories, so you can place the artifact in a directory this way.
mlflow.log_artifacts() logs all the files in a given directory as artifacts, again taking
an optional artifact_path.
mlflow.get_artifact_uri() returns the URI that artifacts from the current run should be
logged to.
Launching Multiple Runs in One Program
Sometimes you want to launch multiple MLflow runs in the same program: for example, maybe you are
performing a hyperparameter search locally or your experiments are just very fast to run. This is
easy to do because the ActiveRun object returned by mlflow.start_run() is a Python
context manager. You can “scope” each run to
just one block of code as follows:
with mlflow.start_run():
mlflow.log_param("x", 1)
mlflow.log_metric("y", 2)
...
The run remains open throughout the with statement, and is automatically closed when the
statement exits, even if it exits due to an exception.
Performance Tracking with Metrics
You log MLflow metrics with log methods in the Tracking API. The log methods support two alternative methods for distinguishing metric values on the x-axis: timestamp and step.
timestamp is an optional long value that represents the time that the metric was logged. timestamp defaults to the current time. step is an optional integer that represents any measurement of training progress (number of training iterations, number of epochs, and so on). step defaults to 0 and has the following requirements and properties:
Must be a valid 64-bit integer value.
Can be negative.
Can be out of order in successive write calls. For example, (1, 3, 2) is a valid sequence.
Can have “gaps” in the sequence of values specified in successive write calls. For example, (1, 5, 75, -20) is a valid sequence.
If you specify both a timestamp and a step, metrics are recorded against both axes independently.
Examples
- Python
with mlflow.start_run(): for epoch in range(0, 3): mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
- Java and Scala
MlflowClient client = new MlflowClient(); RunInfo run = client.createRun(); for (int epoch = 0; epoch < 3; epoch ++) { client.logMetric(run.getRunId(), "quality", 2 * epoch, System.currentTimeMillis(), epoch); }
Visualizing Metrics
Here is an example plot of the quick start tutorial with the step x-axis and two timestamp axes:
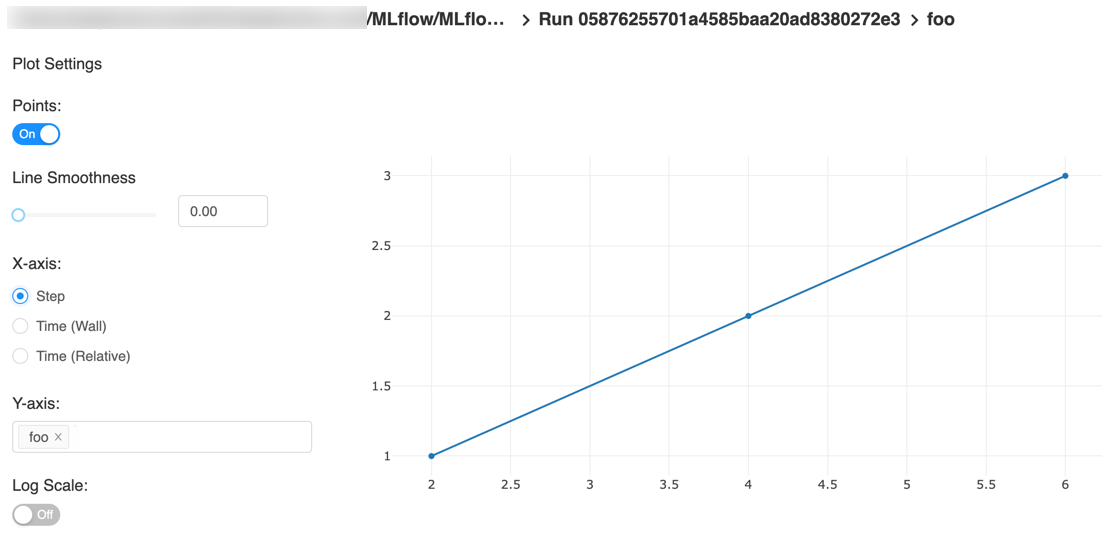
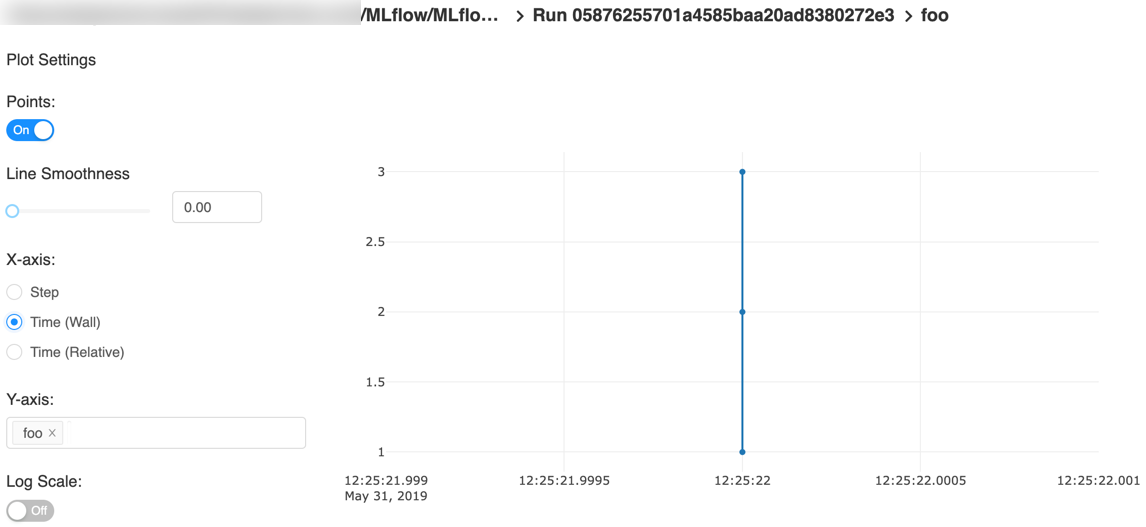
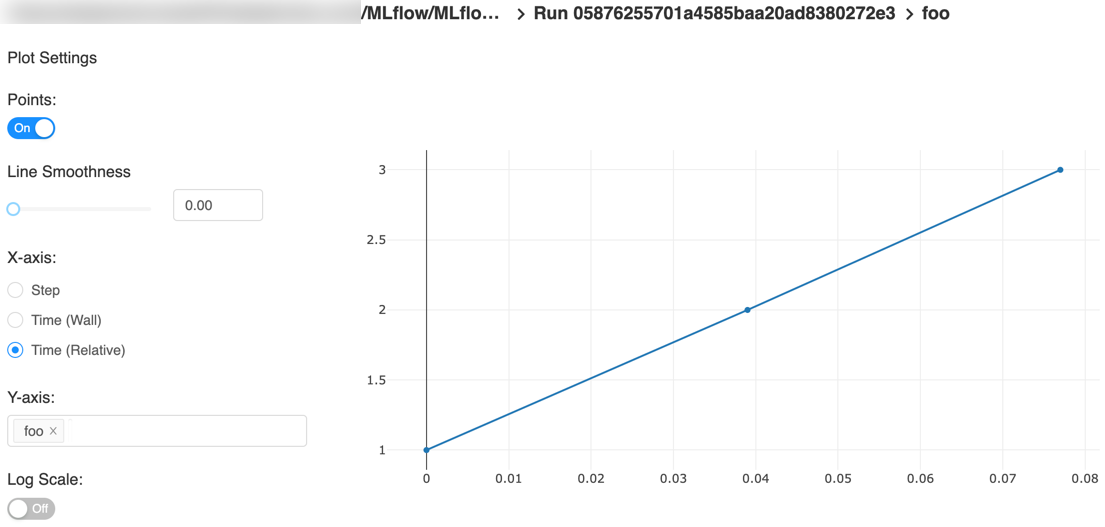
Automatic Logging
Automatic logging allows you to log metrics, parameters, and models without the need for explicit log statements, and is currently supported for:
TensorFlow and Keras (experimental)
Call mlflow.tensorflow.autolog() or mlflow.keras.autolog() before your training code to enable automatic logging of metrics and parameters. See example usages with Keras and
TensorFlow.
Autologging captures the following information:
Framework |
Metrics |
Parameters |
Tags |
Artifacts |
Keras |
Training loss; validation loss; user-specified metrics |
|
– |
Model summary on training start; MLflow Model (Keras model) on training end |
|
Training loss; validation loss; user-specified metrics |
|
– |
Model summary on training start; MLflow Model (Keras model), TensorBoard logs on training end |
|
TensorBoard metrics |
steps, max_steps |
– |
MLflow Model (TF saved model) on call to |
TensorFlow Core |
All |
– |
– |
– |
Note that autologging for tf.keras is handled by mlflow.tensorflow.autolog(), not mlflow.keras.autolog().
If no active run exists when autolog() captures data, MLflow will automatically create a run to log information to.
Once training ends via calls to tf.estimator.train(), tf.keras.fit(), tf.keras.fit_generator(), keras.fit() or keras.fit_generator(),
or once tf.estimator models are exported via tf.estimator.export_saved_model(), MLflow will automatically end that run.
If a run exists when autolog() captures data, MLflow will log to that run and not automatically end that run after training.
Note
Parameters not explicitly passed by users (parameters that use default values) while using
keras.Model.fit_generator()are not currently automatically logged.This feature is experimental - the API and format of the logged data are subject to change.
Gluon (experimental)
Call mlflow.gluon.autolog() before your training code to enable automatic logging of metrics and parameters.
See example usages with Gluon .
Autologging captures the following information:
Framework |
Metrics |
Parameters |
Tags |
Artifacts |
Gluon |
Training loss; validation loss; user-specified metrics |
Number of layers; optimizer name; learning rate; epsilon |
– |
MLflow Model (Gluon model); on training end |
Note
This feature is experimental - the API and format of the logged data are subject to change.
XGBoost (experimental)
Call mlflow.xgboost.autolog() before your training code to enable automatic logging of metrics and parameters.
Autologging captures the following information:
Framework |
Metrics |
Parameters |
Tags |
Artifacts |
XGBoost |
user-specified metrics |
xgboost.train parameters |
– |
MLflow Model (XGBoost model) on training end; feature importance |
If early stopping is activated, metrics at the best iteration will be logged as an extra step/iteration.
Note
This feature is experimental - the API and format of the logged data are subject to change.
The scikit-learn API is not supported.
LightGBM (experimental)
Call mlflow.lightgbm.autolog() before your training code to enable automatic logging of metrics and parameters.
Autologging captures the following information:
Framework |
Metrics |
Parameters |
Tags |
Artifacts |
LightGBM |
user-specified metrics |
lightgbm.train parameters |
– |
MLflow Model (LightGBM model) on training end; feature importance |
If early stopping is activated, metrics at the best iteration will be logged as an extra step/iteration.
Note
This feature is experimental - the API and format of the logged data are subject to change.
The scikit-learn API is not supported.
Spark (experimental)
Initialize a SparkSession with the mlflow-spark JAR attached (e.g.
SparkSession.builder.config("spark.jars.packages", "org.mlflow.mlflow-spark")) and then
call mlflow.spark.autolog() to enable automatic logging of Spark datasource
information at read-time, without the need for explicit
log statements. Note that autologging of Spark ML (MLlib) models is not yet supported.
Autologging captures the following information:
Framework |
Metrics |
Parameters |
Tags |
Artifacts |
Spark |
– |
– |
Single tag containing source path, version, format. The tag contains one line per datasource |
– |
Note: this feature is experimental - the API and format of the logged data are subject to change. Moreover, Spark datasource autologging occurs asynchronously - as such, it’s possible (though unlikely) to see race conditions when launching short-lived MLflow runs that result in datasource information not being logged.
Organizing Runs in Experiments
MLflow allows you to group runs under experiments, which can be useful for comparing runs intended
to tackle a particular task. You can create experiments using the Command-Line Interface (mlflow experiments) or
the mlflow.create_experiment() Python API. You can pass the experiment name for a individual run
using the CLI (for example, mlflow run ... --experiment-name [name]) or the MLFLOW_EXPERIMENT_NAME
environment variable. Alternatively, you can use the experiment ID instead, via the
--experiment-id CLI flag or the MLFLOW_EXPERIMENT_ID environment variable.
# Set the experiment via environment variables
export MLFLOW_EXPERIMENT_NAME=fraud-detection
mlflow experiments create --experiment-name fraud-detection
# Launch a run. The experiment is inferred from the MLFLOW_EXPERIMENT_NAME environment
# variable, or from the --experiment-name parameter passed to the MLflow CLI (the latter
# taking precedence)
with mlflow.start_run():
mlflow.log_param("a", 1)
mlflow.log_metric("b", 2)
Managing Experiments and Runs with the Tracking Service API
MLflow provides a more detailed Tracking Service API for managing experiments and runs directly,
which is available through client SDK in the mlflow.tracking module.
This makes it possible to query data about past runs, log additional information about them, create experiments,
add tags to a run, and more.
Example
from mlflow.tracking import MlflowClient
client = MlflowClient()
experiments = client.list_experiments() # returns a list of mlflow.entities.Experiment
run = client.create_run(experiments[0].experiment_id) # returns mlflow.entities.Run
client.log_param(run.info.run_id, "hello", "world")
client.set_terminated(run.info.run_id)
Adding Tags to Runs
The mlflow.tracking.MlflowClient.set_tag() function lets you add custom tags to runs. A tag can only have a single unique value mapped to it at a time. For example:
client.set_tag(run.info.run_id, "tag_key", "tag_value")
Important
Do not use the prefix mlflow for a tag. This prefix is reserved for use by MLflow.
Tracking UI
The Tracking UI lets you visualize, search and compare runs, as well as download run artifacts or
metadata for analysis in other tools. If you log runs to a local mlruns directory,
run mlflow ui in the directory above it, and it loads the corresponding runs.
Alternatively, the MLflow tracking server serves the same UI and enables remote storage of run artifacts.
In that case, you can view the UI using URL http://<ip address of your MLflow tracking server>:5000 in your browser from any
machine, including any remote machine that can connect to your tracking server.
The UI contains the following key features:
Experiment-based run listing and comparison
Searching for runs by parameter or metric value
Visualizing run metrics
Downloading run results
Querying Runs Programmatically
You can access all of the functions in the Tracking UI programmatically. This makes it easy to do several common tasks:
Query and compare runs using any data analysis tool of your choice, for example, pandas.
Determine the artifact URI for a run to feed some of its artifacts into a new run when executing a workflow. For an example of querying runs and constructing a multistep workflow, see the MLflow Multistep Workflow Example project.
Load artifacts from past runs as MLflow Models. For an example of training, exporting, and loading a model, and predicting using the model, see the MLflow TensorFlow example.
Run automated parameter search algorithms, where you query the metrics from various runs to submit new ones. For an example of running automated parameter search algorithms, see the MLflow Hyperparameter Tuning Example project.
MLflow Tracking Servers
In this section:
You run an MLflow tracking server using mlflow server. An example configuration for a server is:
mlflow server \
--backend-store-uri /mnt/persistent-disk \
--default-artifact-root s3://my-mlflow-bucket/ \
--host 0.0.0.0
Storage
An MLflow tracking server has two components for storage: a backend store and an artifact store.
The backend store is where MLflow Tracking Server stores experiment and run metadata as well as params, metrics, and tags for runs. MLflow supports two types of backend stores: file store and database-backed store.
Use --backend-store-uri to configure the type of backend store. You specify a file store
backend as ./path_to_store or file:/path_to_store and a database-backed store as
SQLAlchemy database URI. The database URI typically takes the format <dialect>+<driver>://<username>:<password>@<host>:<port>/<database>.
MLflow supports the database dialects mysql, mssql, sqlite, and postgresql.
Drivers are optional. If you do not specify a driver, SQLAlchemy uses a dialect’s default driver. For example, --backend-store-uri sqlite:///mlflow.db would use a local SQLite database.
Important
mlflow server will fail against a database-backed store with an out-of-date database schema.
To prevent this, upgrade your database schema to the latest supported version using
mlflow db upgrade [db_uri]. Schema migrations can result in database downtime, may
take longer on larger databases, and are not guaranteed to be transactional. You should always
take a backup of your database prior to running mlflow db upgrade - consult your database’s
documentation for instructions on taking a backup.
By default --backend-store-uri is set to the local ./mlruns directory (the same as when
running mlflow run locally), but when running a server, make sure that this points to a
persistent (that is, non-ephemeral) file system location.
The artifact store is a location suitable for large data (such as an S3 bucket or shared NFS
file system) and is where clients log their artifact output (for example, models).
artifact_location is a property recorded on mlflow.entities.Experiment for
default location to store artifacts for all runs in this experiment. Additional, artifact_uri
is a property on mlflow.entities.RunInfo to indicate location where all artifacts for
this run are stored.
Use --default-artifact-root (defaults to local ./mlruns directory) to configure default
location to server’s artifact store. This will be used as artifact location for newly-created
experiments that do not specify one. Once you create an experiment, --default-artifact-root
is no longer relevant to that experiment.
To allow the server and clients to access the artifact location, you should configure your cloud
provider credentials as normal. For example, for S3, you can set the AWS_ACCESS_KEY_ID
and AWS_SECRET_ACCESS_KEY environment variables, use an IAM role, or configure a default
profile in ~/.aws/credentials.
See Set up AWS Credentials and Region for Development for more info.
Important
If you do not specify a --default-artifact-root or an artifact URI when creating the experiment
(for example, mlflow experiments create --artifact-location s3://<my-bucket>), the artifact root
is a path inside the file store. Typically this is not an appropriate location, as the client and
server probably refer to different physical locations (that is, the same path on different disks).
File store performance
MLflow will automatically try to use LibYAML bindings if they are already installed. However if you notice any performance issues when using file store backend, it could mean LibYAML is not installed on your system. On Linux or Mac you can easily install it using your system package manager:
# On Ubuntu/Debian
apt-get install libyaml-cpp-dev libyaml-dev
# On macOS using Homebrew
brew install yaml-cpp libyaml
After installing LibYAML, you need to reinstall PyYAML:
# Reinstall PyYAML
pip --no-cache-dir install --force-reinstall -I pyyaml
Deletion Behavior
In order to allow MLflow Runs to be restored, Run metadata and artifacts are not automatically removed from the backend store or artifact store when a Run is deleted. The mlflow gc CLI is provided for permanently removing Run metadata and artifacts for deleted runs.
SQLAlchemy Options
You can inject some SQLAlchemy connection pooling options using environment variables.
MLflow Environment Variable |
SQLAlchemy QueuePool Option |
|
|
|
|
Artifact Stores
In this section:
In addition to local file paths, MLflow supports the following storage systems as artifact stores: Amazon S3, Azure Blob Storage, Google Cloud Storage, SFTP server, and NFS.
Amazon S3
To store artifacts in S3, specify a URI of the form s3://<bucket>/<path>. MLflow obtains
credentials to access S3 from your machine’s IAM role, a profile in ~/.aws/credentials, or
the environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY depending on which of
these are available. For more information on how to set credentials, see
Set up AWS Credentials and Region for Development.
To add S3 file upload extra arguments, set MLFLOW_S3_UPLOAD_EXTRA_ARGS to a JSON object of key/value pairs.
For example, if you want to upload to a KMS Encrypted bucket using the KMS Key 1234:
export MLFLOW_S3_UPLOAD_EXTRA_ARGS='{"ServerSideEncryption": "aws:kms", "SSEKMSKeyId": "1234"}'
For a list of available extra args see Boto3 ExtraArgs Documentation.
To store artifacts in a custom endpoint, set the MLFLOW_S3_ENDPOINT_URL to your endpoint’s URL.
For example, if you have a MinIO server at 1.2.3.4 on port 9000:
export MLFLOW_S3_ENDPOINT_URL=http://1.2.3.4:9000
Additionally, if MinIO server is configured with non-default region, you should set AWS_DEFAULT_REGION variable:
export AWS_DEFAULT_REGION=my_region
Complete list of configurable values for an S3 client is available in boto3 documentation.
Azure Blob Storage
To store artifacts in Azure Blob Storage, specify a URI of the form
wasbs://<container>@<storage-account>.blob.core.windows.net/<path>.
MLflow expects Azure Storage access credentials in the
AZURE_STORAGE_CONNECTION_STRING or AZURE_STORAGE_ACCESS_KEY environment variables (preferring
a connection string if one is set), so you must set one of these variables on both your client
application and your MLflow tracking server. Finally, you must run pip install azure-storage-blob
separately (on both your client and the server) to access Azure Blob Storage; MLflow does not declare
a dependency on this package by default.
Google Cloud Storage
To store artifacts in Google Cloud Storage, specify a URI of the form gs://<bucket>/<path>.
You should configure credentials for accessing the GCS container on the client and server as described
in the GCS documentation.
Finally, you must run pip install google-cloud-storage (on both your client and the server)
to access Google Cloud Storage; MLflow does not declare a dependency on this package by default.
FTP server
To store artifacts in a FTP server, specify a URI of the form ftp://user@host/path/to/directory .
The URI may optionally include a password for logging into the server, e.g. ftp://user:pass@host/path/to/directory
SFTP Server
To store artifacts in an SFTP server, specify a URI of the form sftp://user@host/path/to/directory.
You should configure the client to be able to log in to the SFTP server without a password over SSH (e.g. public key, identity file in ssh_config, etc.).
The format sftp://user:pass@host/ is supported for logging in. However, for safety reasons this is not recommended.
When using this store, pysftp must be installed on both the server and the client. Run pip install pysftp to install the required package.
NFS
To store artifacts in an NFS mount, specify a URI as a normal file system path, e.g., /mnt/nfs.
This path must be the same on both the server and the client – you may need to use symlinks or remount
the client in order to enforce this property.
HDFS
To store artifacts in HDFS, specify a hdfs: URI. It can contain host and port: hdfs://<host>:<port>/<path> or just the path: hdfs://<path>.
There are also two ways to authenticate to HDFS:
Use current UNIX account authorization
Kerberos credentials using following environment variables:
export MLFLOW_KERBEROS_TICKET_CACHE=/tmp/krb5cc_22222222
export MLFLOW_KERBEROS_USER=user_name_to_use
Most of the cluster contest settings are read from hdfs-site.xml accessed by the HDFS native
driver using the CLASSPATH environment variable.
Optionally you can select a different version of the HDFS driver library using:
export MLFLOW_HDFS_DRIVER=libhdfs3
The default driver is libhdfs.
Networking
The --host option exposes the service on all interfaces. If running a server in production, we
would recommend not exposing the built-in server broadly (as it is unauthenticated and unencrypted),
and instead putting it behind a reverse proxy like NGINX or Apache httpd, or connecting over VPN.
You can then pass authentication headers to MLflow using these environment variables.
Additionally, you should ensure that the --backend-store-uri (which defaults to the
./mlruns directory) points to a persistent (non-ephemeral) disk or database connection.
Logging to a Tracking Server
To log to a tracking server, set the MLFLOW_TRACKING_URI environment variable to the server’s URI,
along with its scheme and port (for example, http://10.0.0.1:5000) or call mlflow.set_tracking_uri().
The mlflow.start_run(), mlflow.log_param(), and mlflow.log_metric() calls
then make API requests to your remote tracking server.
import mlflow remote_server_uri = "..." # set to your server URI mlflow.set_tracking_uri(remote_server_uri) # Note: on Databricks, the experiment name passed to mlflow_set_experiment must be a # valid path in the workspace mlflow.set_experiment("/my-experiment") with mlflow.start_run(): mlflow.log_param("a", 1) mlflow.log_metric("b", 2)library(mlflow) install_mlflow() remote_server_uri = "..." # set to your server URI mlflow_set_tracking_uri(remote_server_uri) # Note: on Databricks, the experiment name passed to mlflow_set_experiment must be a # valid path in the workspace mlflow_set_experiment("/my-experiment") mlflow_log_param("a", "1")
In addition to the MLFLOW_TRACKING_URI environment variable, the following environment variables
allow passing HTTP authentication to the tracking server:
MLFLOW_TRACKING_USERNAMEandMLFLOW_TRACKING_PASSWORD- username and password to use with HTTP Basic authentication. To use Basic authentication, you must set both environment variables .MLFLOW_TRACKING_TOKEN- token to use with HTTP Bearer authentication. Basic authentication takes precedence if set.MLFLOW_TRACKING_INSECURE_TLS- if set to the literaltrue, MLflow does not verify the TLS connection, meaning it does not validate certificates or hostnames forhttps://tracking URIs. This flag is not recommended for production environments.
System Tags
You can annotate runs with arbitrary tags. Tag keys that start with mlflow. are reserved for
internal use. The following tags are set automatically by MLflow, when appropriate:
Key |
Description |
|---|---|
|
Human readable name that identifies this run. |
|
A descriptive note about this run. This reserved tag is not set automatically and can be overridden by the user to include additional information about the run. The content is displayed on the run’s page under the Notes section. |
|
The ID of the parent run, if this is a nested run. |
|
Identifier of the user who created the run. |
|
Source type. Possible values: |
|
Source identifier (e.g., GitHub URL, local Python filename, name of notebook) |
|
Commit hash of the executed code, if in a git repository. |
|
Name of the branch of the executed code, if in a git repository. |
|
URL that the executed code was cloned from. |
|
The runtime context used by the MLflow project.
Possible values: |
|
Name of the project entry point associated with the current run, if any. |
|
Name of the Docker image used to execute this run. |
|
ID of the Docker image used to execute this run. |
|
(Experimental) Model metadata collected by log-model calls. Includes the serialized form of the MLModel model files logged to a run, although the exact format and information captured is subject to change. |