Upgrade Docker EE
Estimated reading time: 10 minutesDocker Engine - Enterprise 18.09 Upgrades
In Docker Engine - Enterprise 18.09, significant architectural improvements were made to the network architecture in Swarm to increase the performance and scale of the built-in load balancing functionality.
Note: These changes introduce new constraints to the Docker Engine - Enterprise upgrade process that, if not correctly followed, can have impact on the availability of applications running on the Swarm. These constraints impact any upgrades coming from any version before 18.09 to version 18.09 or greater.
Cluster Upgrade Best Practices
Docker Engine - Enterprise upgrades in Swarm clusters should follow these guidelines in order to avoid IP address space exhaustion and associated application downtime.
- New workloads should not be actively scheduled in the cluster during upgrades.
- Differences in the major (X.y.z.) or minor (x.Y.z) version numbers between the managers and workers can cause unintended consequences when new workloads are scheduled.
- Manager nodes should all be upgraded first before upgrading worker nodes. Upgrading manager nodes sequentially is recommended if live workloads are running in the cluster during the upgrade.
- Once manager nodes are upgraded worker nodes should be upgraded next and then the Swarm cluster upgrade is complete.
- If running UCP, the UCP upgrade should follow once all of the Swarm engines have been upgraded.
To upgrade Docker Engine - Enterprise you need to individually upgrade each of the following components:
- Docker Engine - Enterprise.
- Universal Control Plane (UCP).
- Docker Trusted Registry (DTR).
While upgrading, some of these components become temporarily unavailable. So you should schedule your upgrades to take place outside business peak hours to make sure there’s no impact to your business.
Create a backup
Before upgrading Docker Engine - Enterprise, you should make sure you create a backup. This makes it possible to recover if anything goes wrong during the upgrade.
Check the compatibility matrix
You should also check the compatibility matrix, to make sure all Docker EE components are certified to work with one another. You may also want to check the Docker EE maintenance lifecycle, to understand until when your version may be supported.
Apply firewall rules
Before you upgrade, make sure:
- Your firewall rules are configured to allow traffic in the ports UCP uses for communication. Learn about UCP port requirements.
- Make sure you don’t have containers or services that are listening on ports used by UCP.
- Configure your load balancer to forward TCP traffic to the Kubernetes API server port (6443/TCP by default) running on manager nodes.
Certificates
Externally signed certificates are used by the Kubernetes API server and the UCP controller.
IP Address Consumption in 18.09+
In Swarm overlay networks, each task connected to a network consumes an IP address on that network. Swarm networks have a
finite amount of IPs based on the --subnet configured when the network is created. If no subnet is specified then Swarm
defaults to a /24 network with 254 available IP addresses. When the IP space of a network is fully consumed, Swarm tasks
can no longer be scheduled on that network.
Starting with Docker Engine - Enterprise 18.09 and later, each Swarm node will consume an IP address from every Swarm network. This IP address is consumed by the Swarm internal load balancer on the network. Swarm networks running on Engine versions 18.09 or greater must be configured to account for this increase in IP usage. Networks at or near consumption prior to engine version 18.09 may have a risk of reaching full utilization that will prevent tasks from being scheduled on to the network.
Maximum IP consumption per network at any given moment follows the following formula:
Max IP Consumed per Network = Number of Tasks on a Swarm Network + 1 IP for each node where these tasks are scheduled
To prevent this from happening, overlay networks should have enough capacity prior to an upgrade to 18.09, such that the network will have enough capacity after the upgrade. The below instructions offer tooling and steps to ensure capacity is measured before performing an upgrade.
The above following only applies to containers running on Swarm overlay networks. This does not impact bridge, macvlan, host, or 3rd party docker networks.
Upgrade Docker Engine - Enterprise
To avoid application downtime, you should be running Docker Engine - Enterprise in Swarm mode and deploying your workloads as Docker services. That way you can drain the nodes of any workloads before starting the upgrade.
If you have workloads running as containers as opposed to swarm services, make sure they are configured with a restart policy. This ensures that your containers are started automatically after the upgrade.
To ensure that workloads running as Swarm services have no downtime, you need to:
- Determine if the network is in danger of exhaustion; and remediate to a new, larger network prior to upgrading.
- Drain the node you want to upgrade so that services get scheduled in another node.
- Upgrade the Docker Engine on that node.
- Make the node available again.
If you do this sequentially for every node, you can upgrade with no application downtime. When upgrading manager nodes, make sure the upgrade of a node finishes before you start upgrading the next node. Upgrading multiple manager nodes at the same time can lead to a loss of quorum, and possible data loss.
Determine if the network is in danger of exhaustion
Starting with a cluster with one or more services configured, determine whether some networks may require updating the IP address space in order to function correctly after an Docker Engine - Enterprise 18.09 upgrade.
-
SSH into a manager node on a cluster where your applications are running.
-
Run the following:
$ docker run -it --rm -v /var/run/docker.sock:/var/run/docker.sock docker/ip-util-check
If the network is in danger of exhaustion, the output will show similar warnings or errors:
Overlay IP Utilization Report
----
Network ex_net1/XXXXXXXXXXXX has an IP address capacity of 29 and uses 28 addresses
ERROR: network will be over capacity if upgrading Docker engine version 18.09
or later.
----
Network ex_net2/YYYYYYYYYYYY has an IP address capacity of 29 and uses 24 addresses
WARNING: network could exhaust IP addresses if the cluster scales to 5 or more nodes
----
Network ex_net3/ZZZZZZZZZZZZ has an IP address capacity of 61 and uses 52 addresses
WARNING: network could exhaust IP addresses if the cluster scales to 9 or more nodes
- Once you determine all networks are sized appropriately, start the upgrade on the Swarm managers.
Triage and fix an upgrade that exhausted IP address space
With an exhausted network, you can triage it using the following steps.
-
SSH into a manager node on a cluster where your applications are running.
-
Check the
docker service lsoutput. It will display the service that is unable to completely fill all its replicas such as:
ID NAME MODE REPLICAS IMAGE PORTS
wn3x4lu9cnln ex_service replicated 19/24 nginx:latest
- Use
docker service ps ex_serviceto find a failed replica such as:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
...
i64lee19ia6s \_ ex_service.11 nginx:latest tk1706-ubuntu-1 Shutdown Rejected 7 minutes ago "node is missing network attac…"
...
- Examine the error using
docker inspect. In this example, thedocker inspect i64lee19ia6soutput shows the error in theStatus.Errfield:
...
"Status": {
"Timestamp": "2018-08-24T21:03:37.885405884Z",
"State": "rejected",
"Message": "preparing",
**"Err": "node is missing network attachments, ip addresses may be exhausted",**
"ContainerStatus": {
"ContainerID": "",
"PID": 0,
"ExitCode": 0
},
"PortStatus": {}
},
...
-
Adjust your network subnet in the deployment manifest, such that it has enough IPs required by the application.
-
Redeploy the application.
-
Confirm the adjusted service deployed successfully.
Manager Upgrades When Moving to Docker Engine - Enterprise 18.09 and later
The following is a constraint introduced by architectural changes to the Swarm overlay networking when upgrading to Docker Engine - Enterprise 18.09 or later. It only applies to this one-time upgrade and to workloads that are using the Swarm overlay driver. Once upgraded to Docker Engine - Enterprise 18.09, this constraint does not impact future upgrades.
When upgrading to Docker Engine - Enterprise 18.09, manager nodes cannot reschedule new workloads on the managers until all managers have been upgraded to the Docker Engine - Enterprise 18.09 (or higher) version. During the upgrade of the managers, there is a possibility that any new workloads that are scheduled on the managers will fail to schedule until all of the managers have been upgraded.
In order to avoid any impactful application downtime, it is advised to reschedule any critical workloads on to Swarm worker nodes during the upgrade of managers. Worker nodes and their network functionality will continue to operate independently during any upgrades or outages on the managers. Note that this restriction only applies to managers and not worker nodes.
Drain the node
If you are running live application on the cluster while upgrading, remove applications from nodes being upgrades as to not create unplanned outages.
Start by draining the node so that services get scheduled in another node and continue running without downtime.
For that, run this command on a manager node:
$ docker node update --availability drain <node>
Perform the upgrade
To upgrade a node individually by operating system, please follow the instructions listed below:
Post-Upgrade Steps
After all manager and worker nodes have been upgrades, the Swarm cluster can be used again to schedule new
workloads. If workloads were previously scheduled off of the managers, they can be rescheduled again.
If any worker nodes were drained, they can be undrained again by setting --availability active.
Upgrade UCP
Once you’ve upgraded the Docker Engine - Enterprise running on all the nodes, upgrade UCP. You can do this from the UCP web UI.
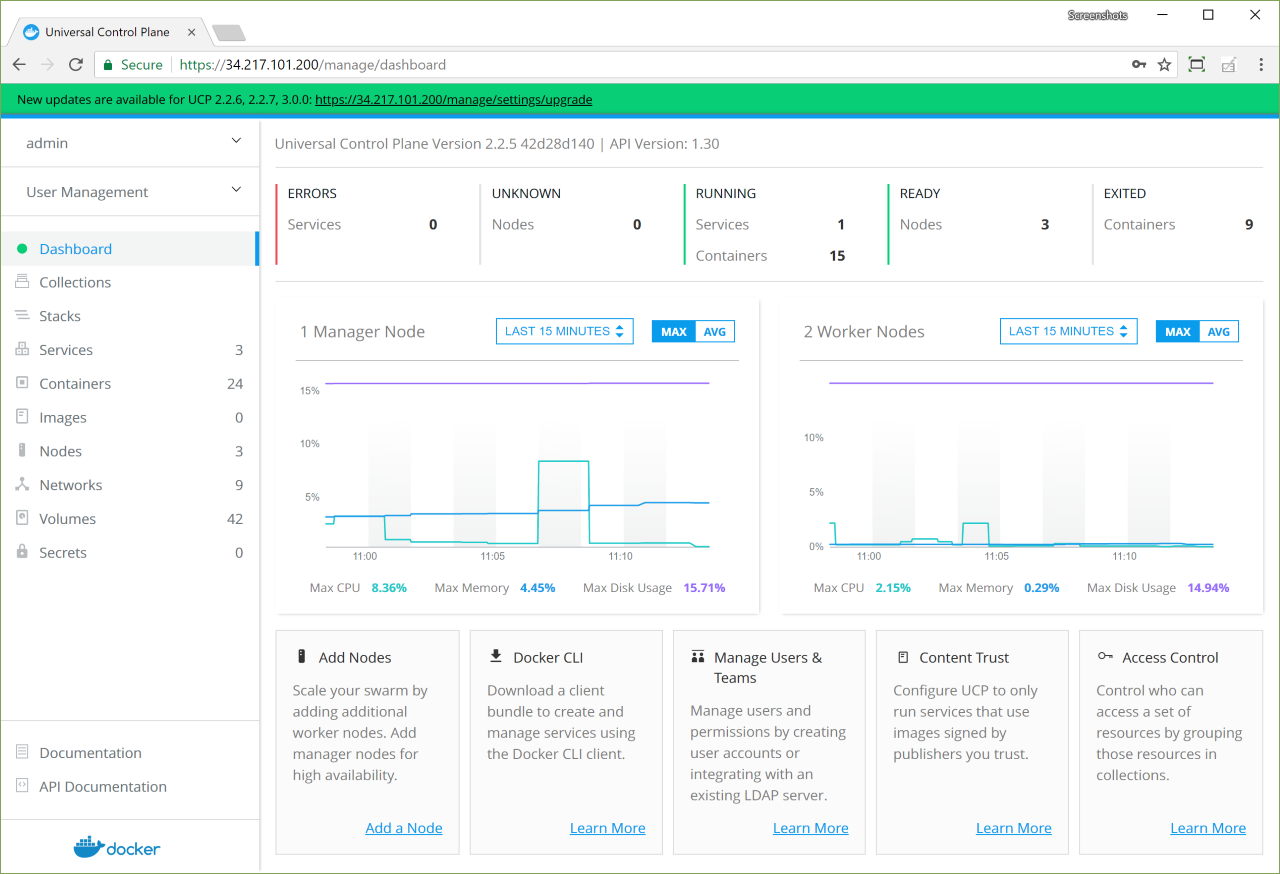
Click on the banner, and choose the version you want to upgrade to.
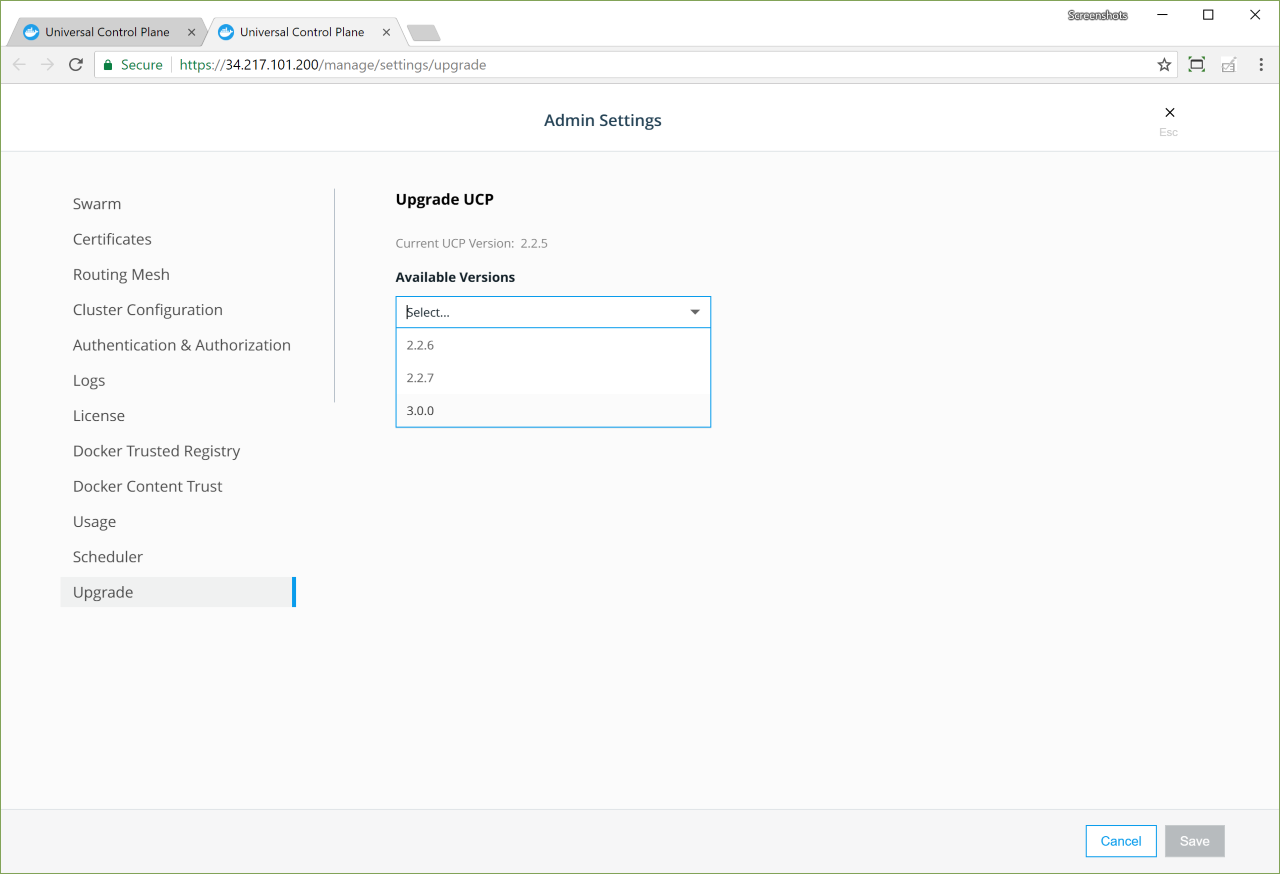
Once you click Upgrade UCP, the upgrade starts. If you want you can upgrade UCP from the CLI instead. Learn more.
Upgrade DTR
Log in into the DTR web UI to check if there’s a new version available.
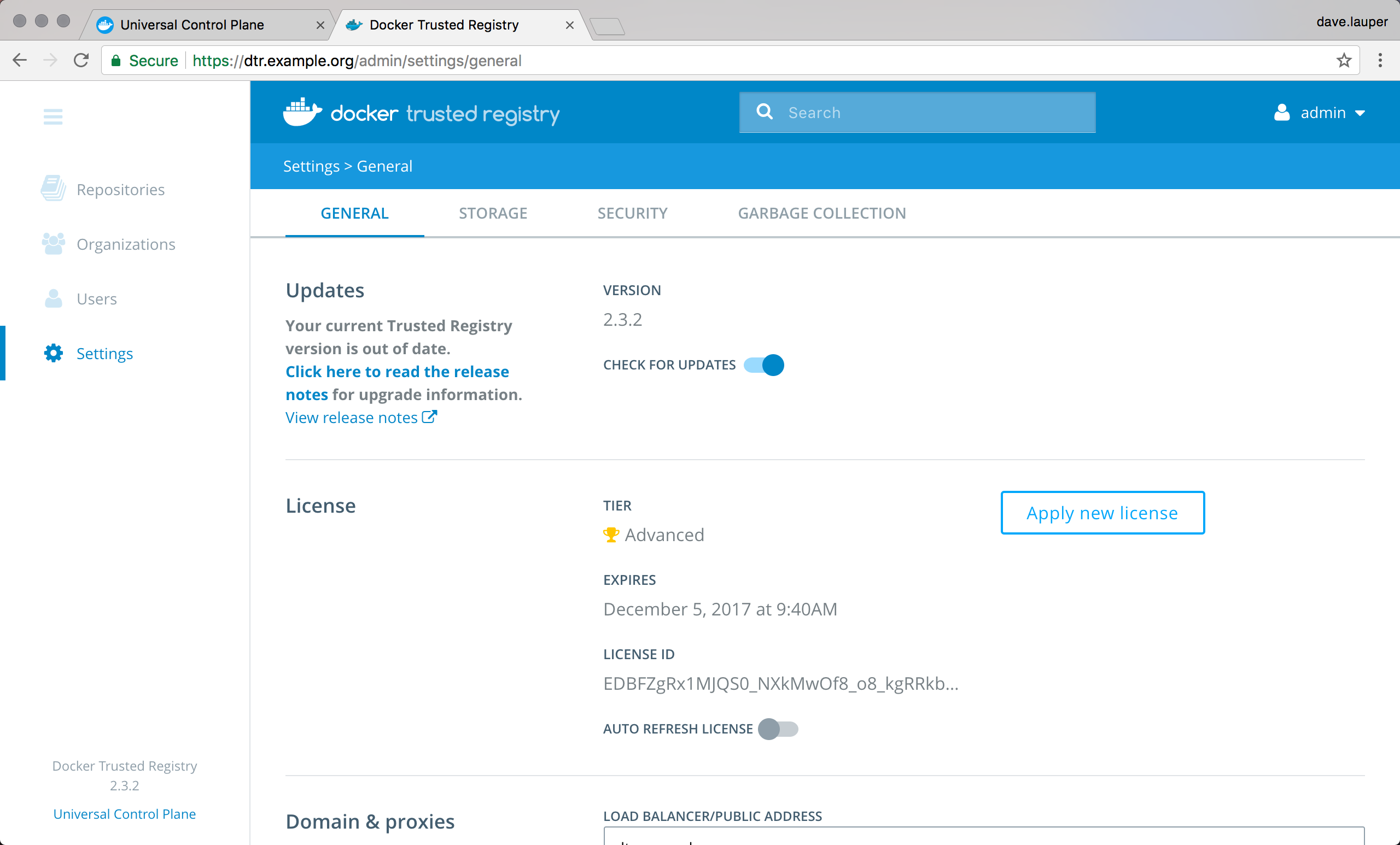
Then follow these instructions to upgrade DTR. When this is finished, your Docker EE has been upgraded.