Plan for Swarm in production
Estimated reading time: 14 minutesYou are viewing docs for legacy standalone Swarm. These topics describe standalone Docker Swarm. In Docker 1.12 and higher, Swarm mode is integrated with Docker Engine. Most users should use integrated Swarm mode — a good place to start is Getting started with swarm mode, Swarm mode CLI commands, and the Get started with Docker walkthrough). Standalone Docker Swarm is not integrated into the Docker Engine API and CLI commands.
This article provides guidance to help you plan, deploy, and manage Docker swarm clusters in business critical production environments. The following high level topics are covered:
Security
There are many aspects to securing a Docker Swarm cluster. This section covers:
- Authentication using TLS
- Network access control
These topics are not exhaustive. They form part of a wider security architecture that includes: security patching, strong password policies, role based access control, technologies such as SELinux and AppArmor, strict auditing, and more.
Configure Swarm for TLS
All nodes in a swarm cluster must bind their Docker Engine daemons to a network port. This brings with it all of the usual network related security implications such as man-in-the-middle attacks. These risks are compounded when the network in question is untrusted such as the internet. To mitigate these risks, Swarm and the Engine support Transport Layer Security (TLS) for authentication.
The Engine daemons, including the swarm manager, that are configured to use TLS only accepts commands from Docker Engine clients that sign their communications. Engine and Swarm support external 3rd party Certificate Authorities (CA) as well as internal corporate CAs.
The default Engine and Swarm ports for TLS are:
- Engine daemon: 2376/tcp
- Swarm manager: 3376/tcp
For more information on configuring Swarm for TLS, see the Overview Docker Swarm with TLS page.
Network access control
Production networks are complex, and usually locked down so that only allowed traffic can flow on the network. The list below shows the network ports and protocols that the different components of a Swam cluster listen on. You should use these to configure your firewalls and other network access control lists.
- Swarm manager.
- Inbound 80/tcp (HTTP). This allows
docker pullcommands to work. If you plan to pull images from Docker Hub, you must allow Internet connections through port 80. - Inbound 2375/tcp. This allows Docker Engine CLI commands direct to the Engine daemon.
- Inbound 3375/tcp. This allows Engine CLI commands to the swarm manager.
- Inbound 22/tcp. This allows remote management via SSH.
- Inbound 80/tcp (HTTP). This allows
- Service Discovery:
- Inbound 80/tcp (HTTP). This allows
docker pullcommands to work. If you plan to pull images from Docker Hub, you must allow Internet connections through port 80. - Inbound Discovery service port. This needs setting to the port that the backend discovery service listens on (consul, etcd, or zookeeper).
- Inbound 22/tcp. This allows remote management via SSH.
- Inbound 80/tcp (HTTP). This allows
- Swarm nodes:
- Inbound 80/tcp (HTTP). This allows
docker pullcommands to work. If you plan to pull images from Docker Hub, you must allow Internet connections through port 80. - Inbound 2375/tcp. This allows Engine CLI commands direct to the Docker daemon.
- Inbound 22/tcp. This allows remote management via SSH.
- Inbound 80/tcp (HTTP). This allows
- Custom, cross-host container networks:
- Inbound 7946/tcp Allows for discovering other container networks.
- Inbound 7946/udp Allows for discovering other container networks.
- Inbound
<store-port>/tcp Network key-value store service port. - 4789/udp For the container overlay network.
- ESP packets For encrypted overlay networks.
If your firewalls and other network devices are connection state aware, they allow responses to established TCP connections. If your devices are not state aware, you need to open up ephemeral ports from 32768-65535. For added security you can configure the ephemeral port rules to only allow connections from interfaces on known swarm devices.
If your swarm cluster is configured for TLS, replace 2375 with 2376, and
3375 with 3376.
The ports listed above are just for swarm cluster operations such as cluster creation, cluster management, and scheduling of containers against the cluster. You may need to open additional network ports for application-related communications.
It is possible for different components of a swarm cluster to exist on separate networks. For example, many organizations operate separate management and production networks. Some Docker Engine clients may exist on a management network, while swarm managers, discovery service instances, and nodes might exist on one or more production networks. To offset against network failures, you can deploy swarm managers, discovery services, and nodes across multiple production networks. In all of these cases you can use the list of ports above to assist the work of your network infrastructure teams to efficiently and securely configure your network.
High Availability (HA)
All production environments should be highly available, meaning they are continuously operational over long periods of time. To achieve high availability, an environment must survive failures of its individual component parts.
The following sections discuss some technologies and best practices that can enable you to build resilient, highly-available swarm clusters. You can then use these cluster to run your most demanding production applications and workloads.
Swarm manager HA
The swarm manager is responsible for accepting all commands coming in to a swarm cluster, and scheduling resources against the cluster. If the swarm manager becomes unavailable, some cluster operations cannot be performed until the swarm manager becomes available again. This is unacceptable in large-scale business critical scenarios.
Swarm provides HA features to mitigate against possible failures of the swarm manager. You can use Swarm’s HA feature to configure multiple swarm managers for a single cluster. These swarm managers operate in an active/passive formation with a single swarm manager being the primary, and all others being secondaries.
Swarm secondary managers operate as warm standby’s, meaning they run in the background of the primary swarm manager. The secondary swarm managers are online and accept commands issued to the cluster, just as the primary swarm manager. However, any commands received by the secondaries are forwarded to the primary where they are executed. Should the primary swarm manager fail, a new primary is elected from the surviving secondaries.
When creating HA swarm managers, you should take care to distribute them over as many failure domains as possible. A failure domain is a network section that can be negatively affected if a critical device or service experiences problems. For example, if your cluster is running in the Ireland Region of Amazon Web Services (eu-west-1) and you configure three swarm managers (1 x primary, 2 x secondary), you should place one in each availability zone as shown below.
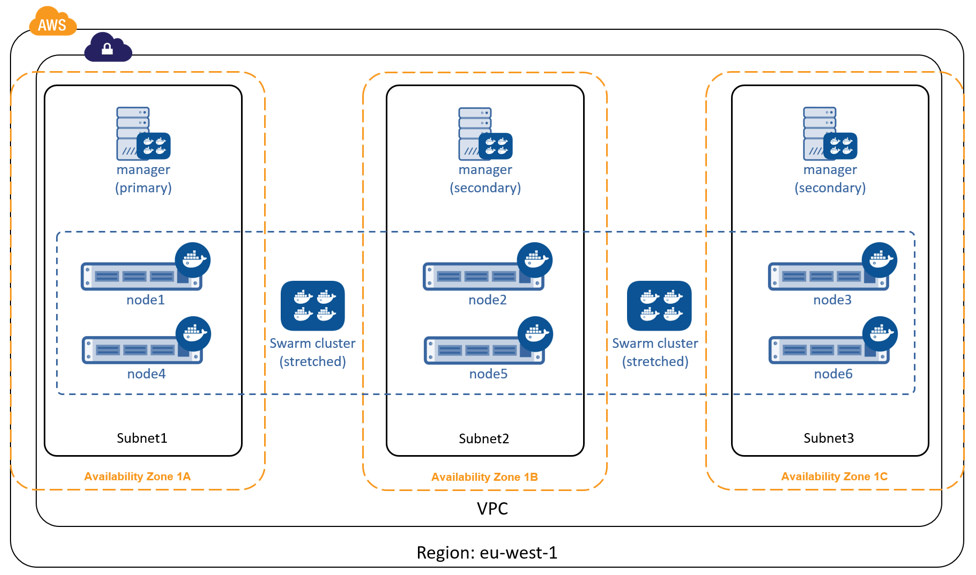
In this configuration, the swarm cluster can survive the loss of any two availability zones. For your applications to survive such failures, they must be architected across as many failure domains as well.
For swarm clusters serving high-demand, line-of-business applications, you should have 3 or more swarm managers. This configuration allows you to take one manager down for maintenance, suffer an unexpected failure, and still continue to manage and operate the cluster.
Discovery service HA
The discovery service is a key component of a swarm cluster. If the discovery service becomes unavailable, this can prevent certain cluster operations. For example, without a working discovery service, operations such as adding new nodes to the cluster and making queries against the cluster configuration fail. This is not acceptable in business critical production environments.
Swarm supports four backend discovery services:
- Hosted (not for production use)
- Consul
- etcd
- Zookeeper
Consul, etcd, and Zookeeper are all suitable for production, and should be configured for high availability. You should use each service’s existing tools and best practices to configure these for HA.
For swarm clusters serving high-demand, line-of-business applications, it is recommended to have 5 or more discovery service instances. This due to the replication/HA technologies they use (such as Paxos/Raft) requiring a strong quorum. Having 5 instances allows you to take one down for maintenance, suffer an unexpected failure, and still maintain a strong quorum.
When creating a highly available swarm discovery service, you should take care to distribute each discovery service instance over as many failure domains as possible. For example, if your cluster is running in the Ireland Region of Amazon Web Services (eu-west-1) and you configure three discovery service instances, you should place one in each availability zone.
The diagram below shows a swarm cluster configured for HA. It has three swarm managers and three discovery service instances spread over three failure domains (availability zones). It also has swarm nodes balanced across all three failure domains. The loss of two availability zones in the configuration shown below does not cause the swarm cluster to go down.
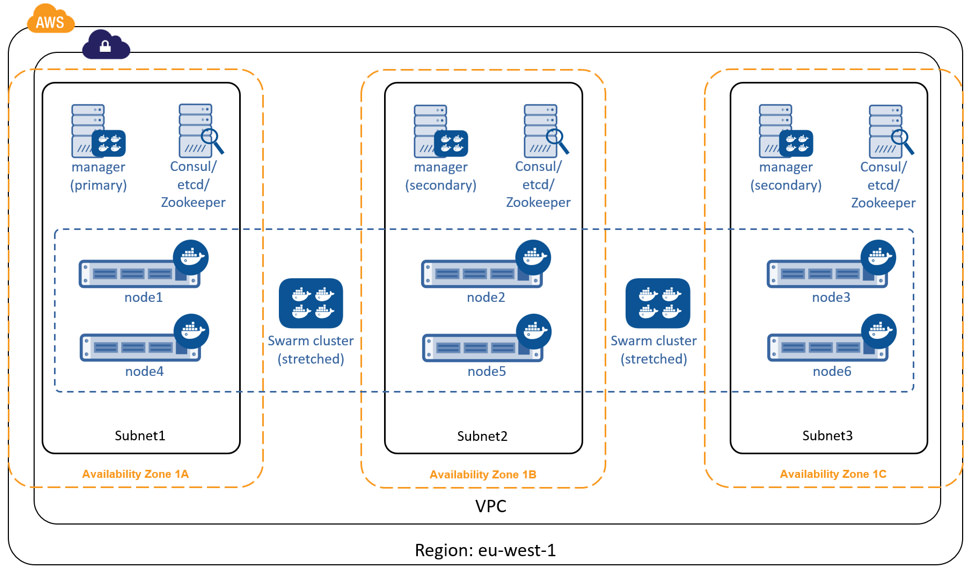
It is possible to share the same Consul, etcd, or Zookeeper containers between the swarm discovery and Engine container networks. However, for best performance and availability you should deploy dedicated instances – a discovery instance for Swarm and another for your container networks.
Multiple clouds
You can architect and build swarm clusters that stretch across multiple cloud providers, and even across public cloud and on premises infrastructures. The diagram below shows an example swarm cluster stretched across AWS and Azure.
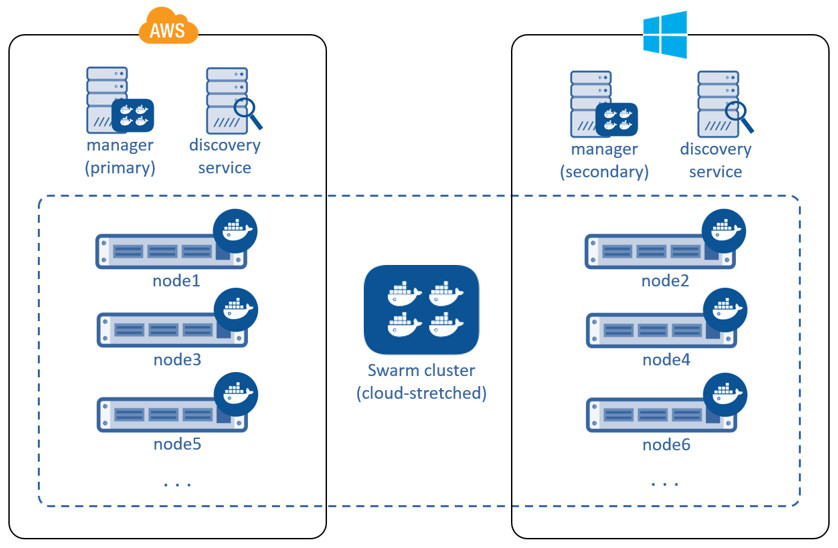
While such architectures may appear to provide the ultimate in availability, there are several factors to consider. Network latency can be problematic, as can partitioning. As such, you should seriously consider technologies that provide reliable, high speed, low latency connections into these cloud platforms – technologies such as AWS Direct Connect and Azure ExpressRoute.
If you are considering a production deployment across multiple infrastructures like this, make sure you have good test coverage over your entire system.
Isolated production environments
It is possible to run multiple environments, such as development, staging, and
production, on a single swarm cluster. You accomplish this by tagging swarm
nodes and using constraints to filter containers onto nodes tagged as
production or staging etc. However, this is not recommended. The recommended
approach is to air-gap production environments, especially high performance
business critical production environments.
For example, many companies not only deploy dedicated isolated infrastructures for production – such as networks, storage, compute and other systems. They also deploy separate management systems and policies. This results in things like users having separate accounts for logging on to production systems etc. In these types of environments, it is mandatory to deploy dedicated production swarm clusters that operate on the production hardware infrastructure and follow thorough production management, monitoring, audit and other policies.
Operating system selection
You should give careful consideration to the operating system that your Swarm infrastructure relies on. This consideration is vital for production environments.
It is not unusual for a company to use one operating system in development environments, and a different one in production. A common example of this is to use CentOS in development environments, but then to use Red Hat Enterprise Linux (RHEL) in production. This decision is often a balance between cost and support. CentOS Linux can be downloaded and used for free, but commercial support options are few and far between. Whereas RHEL has an associated support and license cost, but comes with world class commercial support from Red Hat.
When choosing the production operating system to use with your swarm clusters, choose one that closely matches what you have used in development and staging environments. Although containers abstract much of the underlying OS, some features have configuration requirements. For example, to use Docker container networking with Docker Engine 1.10 or higher, your host must have a Linux kernel that is version 3.10 or higher. Refer to the change logs to understand the requirements for a particular version of Docker Engine or Swarm.
You should also consider procedures and channels for deploying and potentially patching your production operating systems.
Performance
Performance is critical in environments that support business critical line of business applications. The following sections discuss some technologies and best practices that can help you build high performance swarm clusters.
Container networks
Docker Engine container networks are overlay networks and can be created across multiple Engine hosts. For this reason, a container network requires a key-value (KV) store to maintain network configuration and state. This KV store can be shared in common with the one used by the swarm cluster discovery service. However, for best performance and fault isolation, you should deploy individual KV store instances for container networks and swarm discovery. This is especially so in demanding business critical production environments.
Beginning with Docker Engine 1.9, Docker container networks require specific Linux kernel versions. Higher kernel versions are usually preferred, but carry an increased risk of instability because of the newness of the kernel. Where possible, use a kernel version that is already approved for use in your production environment. If you can not use a 3.10 or higher Linux kernel version for production, you should begin the process of approving a newer kernel as early as possible.
Scheduling strategies
Scheduling strategies are how Swarm decides which nodes in a cluster to start containers on. Swarm supports the following strategies:
- spread
- binpack
- random (not for production use)
You can also write your own.
Spread is the default strategy. It attempts to balance the number of containers evenly across all nodes in the cluster. This is a good choice for high performance clusters, as it spreads container workload across all resources in the cluster. These resources include CPU, RAM, storage, and network bandwidth.
If your swarm nodes are balanced across multiple failure domains, the spread strategy evenly balance containers across those failure domains. However, spread on its own is not aware of the roles of any of those containers, so has no intelligence to spread multiple instances of the same service across failure domains. To achieve this you should use tags and constraints.
The binpack strategy runs as many containers as possible on a node, effectively filling it up, before scheduling containers on the next node.
This means that binpack does not use all cluster resources until the cluster fills up. As a result, applications running on swarm clusters that operate the binpack strategy might not perform as well as those that operate the spread strategy. However, binpack is a good choice for minimizing infrastructure requirements and cost. For example, imagine you have a 10-node cluster where each node has 16 CPUs and 128GB of RAM. However, your container workload across the entire cluster is only using the equivalent of 6 CPUs and 64GB RAM. The spread strategy would balance containers across all nodes in the cluster. However, the binpack strategy would fit all containers on a single node, potentially allowing you turn off the additional nodes and save on cost.
Ownership of Swarm clusters
The question of ownership is vital in production environments. It is therefore vital that you consider and agree on all of the following when planning, documenting, and deploying your production swarm clusters.
- Whose budget does the production swarm infrastructure come out of?
- Who owns the accounts that can administer and manage the production swarm cluster?
- Who is responsible for monitoring the production swarm infrastructure?
- Who is responsible for patching and upgrading the production swarm infrastructure?
- On-call responsibilities and escalation procedures?
The above is not a complete list, and the answers to the questions vary depending on how your organization’s and team’s are structured. Some companies are along way down the DevOps route, while others are not. Whatever situation your company is in, it is important that you factor all of the above into the planning, deployment, and ongoing management of your production swarm clusters.
Related information
- Try Swarm at scale
- Swarm and container networks
- High availability in Docker Swarm
- Docker Data Center